




Michelle Greene
@mgreenephd.bsky.social
Cognitive scientist at Barnard College; visual categorization; EEG; eye movements; machine learning; childless cat fae; will ask to see a picture of your pet. Opinions my own. They/she. 🏳️🌈
Sobs in intellectual.

October 22, 2025 at 10:13 AM
Sobs in intellectual.

Another flight, another dude who feels entitled to my legroom. 🙄

October 9, 2025 at 3:18 PM
Another flight, another dude who feels entitled to my legroom. 🙄
Heading to the Bronx. Betting hard on the idea that they won’t throw punches at a middle aged professor.

October 1, 2025 at 8:56 PM
Heading to the Bronx. Betting hard on the idea that they won’t throw punches at a middle aged professor.
My favorite subway graffiti right now is anti-friend hot takes.


September 29, 2025 at 9:27 PM
My favorite subway graffiti right now is anti-friend hot takes.
Sure. Here's Spring 2025. The first column is the project name, subsequent columns are goals for each month, color-coded by task type (data collection, analysis, dissemination, etc.)

September 29, 2025 at 3:42 PM
Sure. Here's Spring 2025. The first column is the project name, subsequent columns are goals for each month, color-coded by task type (data collection, analysis, dissemination, etc.)
Really excited for #CCN2025! Come see our poster (A58).
We asked people to describe the same pictures with different task instructions and trained a CNN to learn these sentence embeddings.
Both networks learned task-relevant visual features that humans also needed for the same tasks!
We asked people to describe the same pictures with different task instructions and trained a CNN to learn these sentence embeddings.
Both networks learned task-relevant visual features that humans also needed for the same tasks!

August 12, 2025 at 6:01 AM
Really excited for #CCN2025! Come see our poster (A58).
We asked people to describe the same pictures with different task instructions and trained a CNN to learn these sentence embeddings.
Both networks learned task-relevant visual features that humans also needed for the same tasks!
We asked people to describe the same pictures with different task instructions and trained a CNN to learn these sentence embeddings.
Both networks learned task-relevant visual features that humans also needed for the same tasks!
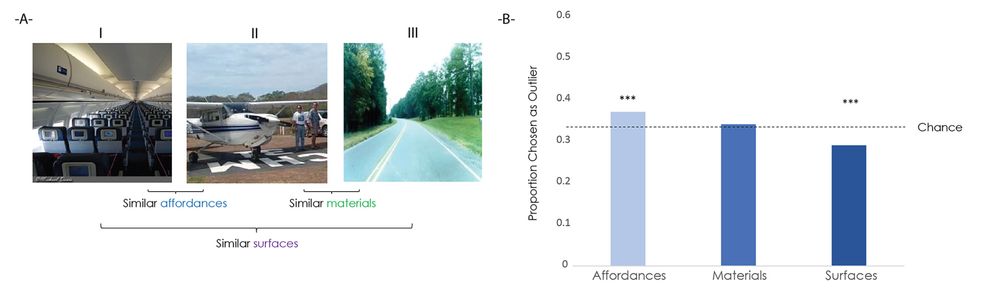
Experiment 1 used @martinhebart.bsky.social's odd-one-out triplet task, but with a twist: each pair within a triplet was selected to be an outlier in one of three feature spaces:
✅ Affordances
✅ Surfaces
✅ Materials
People picked the affordance outlier as being the most different most often. (3/7)
✅ Affordances
✅ Surfaces
✅ Materials
People picked the affordance outlier as being the most different most often. (3/7)
July 8, 2025 at 4:38 PM
Experiment 1 used @martinhebart.bsky.social's odd-one-out triplet task, but with a twist: each pair within a triplet was selected to be an outlier in one of three feature spaces:
✅ Affordances
✅ Surfaces
✅ Materials
People picked the affordance outlier as being the most different most often. (3/7)
✅ Affordances
✅ Surfaces
✅ Materials
People picked the affordance outlier as being the most different most often. (3/7)
Heading to the NYC Dyke March! Who else is going?

June 28, 2025 at 8:35 PM
Heading to the NYC Dyke March! Who else is going?

Come chat with Carina about object-word EEG cross decoding, now in Banyan.

May 18, 2025 at 12:45 PM
Come chat with Carina about object-word EEG cross decoding, now in Banyan.
And Amy and Vivian will present on EEG decoding of visual and semantic scene information. 5/5

May 15, 2025 at 11:21 PM
And Amy and Vivian will present on EEG decoding of visual and semantic scene information. 5/5
Skylar used an SSVEP "sweep" paradigm to examine the information accumulation of visual and semantic information. 4/5

May 15, 2025 at 11:21 PM
Skylar used an SSVEP "sweep" paradigm to examine the information accumulation of visual and semantic information. 4/5
Our other posters will be on Tuesday afternoon (pregame for Club Vision with us). Sage and Hooriya will present some interesting double dissociations between detection and categorization for two types of complexity, visual and semantic. 3/5

May 15, 2025 at 11:21 PM
Our other posters will be on Tuesday afternoon (pregame for Club Vision with us). Sage and Hooriya will present some interesting double dissociations between detection and categorization for two types of complexity, visual and semantic. 3/5
Carina will present Sunday in the Undergraduate Just in Time session. Her work considers the neural correlates of word-picture congruence in scene recognition. 2/5

May 15, 2025 at 11:21 PM
Carina will present Sunday in the Undergraduate Just in Time session. Her work considers the neural correlates of word-picture congruence in scene recognition. 2/5
I have no idea what’s going on in this chaotic discarded painting, but I’ve never felt more seen.

April 30, 2025 at 12:26 PM
I have no idea what’s going on in this chaotic discarded painting, but I’ve never felt more seen.
Amazing turnout for #handsoff NYC. The second photo is the crowd waiting to start marching after I had "salmoned" back to the start. Wall to wall to wall from 40th to 25th!


April 5, 2025 at 7:46 PM
Amazing turnout for #handsoff NYC. The second photo is the crowd waiting to start marching after I had "salmoned" back to the start. Wall to wall to wall from 40th to 25th!

That sky though….

April 1, 2025 at 2:15 PM
That sky though….
Portrait of the artist in college at a protest against G.W. Bush's appearance on campus. My sign (not pictured) read "L.A.B.I.A.: Lesbians Against Bush's Idiotic Administration. Read our lips". Thinking a lot about how my students don't have the same freedom to be young & opinionated. 1/3

March 29, 2025 at 8:34 PM
Portrait of the artist in college at a protest against G.W. Bush's appearance on campus. My sign (not pictured) read "L.A.B.I.A.: Lesbians Against Bush's Idiotic Administration. Read our lips". Thinking a lot about how my students don't have the same freedom to be young & opinionated. 1/3
5/ Even within affluent countries like the US, these biases persist. Homes from wealthier US counties were classified with higher confidence. The models implicitly equate "affluent" with "clear," "legitimate," and "recognizable."

March 23, 2025 at 1:02 PM
5/ Even within affluent countries like the US, these biases persist. Homes from wealthier US counties were classified with higher confidence. The models implicitly equate "affluent" with "clear," "legitimate," and "recognizable."
2/ Here are the top five classifications from a leading CNN (Resnet-50). As you can see, not only are the images misclassified, but they're misclassified in ways that connote death, disrepair, and decay.

March 23, 2025 at 1:02 PM
2/ Here are the top five classifications from a leading CNN (Resnet-50). As you can see, not only are the images misclassified, but they're misclassified in ways that connote death, disrepair, and decay.
🚨New publication alert!🚨 Our latest paper explores socioeconomic biases in AI—but this time, it's not about people directly. It's about homes. Consider these images: it's clear to us that they're all bathrooms. 1/

March 23, 2025 at 1:02 PM
🚨New publication alert!🚨 Our latest paper explores socioeconomic biases in AI—but this time, it's not about people directly. It's about homes. Consider these images: it's clear to us that they're all bathrooms. 1/
