




Mark Dredze
@mdredze.bsky.social
John C Malone Professor at Johns Hopkins Computer Science, Center for Language and Speech Processing, Malone Center for Engineering in Healthcare.
Parttime: Bloomberg LP #nlproc
Parttime: Bloomberg LP #nlproc
I know I can improve my ARR reviews, but there really is no need for name calling. 😁

February 5, 2025 at 2:13 PM
I know I can improve my ARR reviews, but there really is no need for name calling. 😁
ARR: Reviews are due today.
Me:
Me:

January 20, 2025 at 1:29 PM
ARR: Reviews are due today.
Me:
Me:
I feel seen. This is why I always access my API keys from my laptop.

January 17, 2025 at 7:50 PM
I feel seen. This is why I always access my API keys from my laptop.
Do you have any of those fortune cookies that mock academics?
Sure!
Sure!

January 14, 2025 at 10:19 PM
Do you have any of those fortune cookies that mock academics?
Sure!
Sure!
Starting a new year and reflecting on how lucky I am to work at @hopkinsengineer.bsky.social with amazing people @jhucompsci.bsky.social @jhuclsp.bsky.social.
I was promoted to full professor in 2023, and my students presented me with this amazing poster of current and former PhD students.
I was promoted to full professor in 2023, and my students presented me with this amazing poster of current and former PhD students.

January 2, 2025 at 5:40 PM
Starting a new year and reflecting on how lucky I am to work at @hopkinsengineer.bsky.social with amazing people @jhucompsci.bsky.social @jhuclsp.bsky.social.
I was promoted to full professor in 2023, and my students presented me with this amazing poster of current and former PhD students.
I was promoted to full professor in 2023, and my students presented me with this amazing poster of current and former PhD students.
Examining the generated QA pairs, you can really see the difference. Our generations (bottom) look harder and more interesting.
Try our strategy for your synthetic generation task? Check out our paper, being presented at #ML4H2024 .
arxiv.org/abs/2412.04573
Try our strategy for your synthetic generation task? Check out our paper, being presented at #ML4H2024 .
arxiv.org/abs/2412.04573

December 22, 2024 at 4:01 PM
Examining the generated QA pairs, you can really see the difference. Our generations (bottom) look harder and more interesting.
Try our strategy for your synthetic generation task? Check out our paper, being presented at #ML4H2024 .
arxiv.org/abs/2412.04573
Try our strategy for your synthetic generation task? Check out our paper, being presented at #ML4H2024 .
arxiv.org/abs/2412.04573
Training a Clinical QA system on our data gives big improvements, whether we generate data from Llama or GPT-4o. These improvements are both in F1 and any overlap between the extracted and true answers.

December 22, 2024 at 4:01 PM
Training a Clinical QA system on our data gives big improvements, whether we generate data from Llama or GPT-4o. These improvements are both in F1 and any overlap between the extracted and true answers.
Paper at #ML42024!
Clinical QA can help doctors find critical information in patient records. But where do we get training data for these systems? Generating this data from an LLM is hard. 🧵
Clinical QA can help doctors find critical information in patient records. But where do we get training data for these systems? Generating this data from an LLM is hard. 🧵

December 22, 2024 at 4:01 PM
Paper at #ML42024!
Clinical QA can help doctors find critical information in patient records. But where do we get training data for these systems? Generating this data from an LLM is hard. 🧵
Clinical QA can help doctors find critical information in patient records. But where do we get training data for these systems? Generating this data from an LLM is hard. 🧵
It turns out that when you have just a little supervised data, the models trained on more data and tasks, even when out of domain, do BETTER on the new clinical domain.
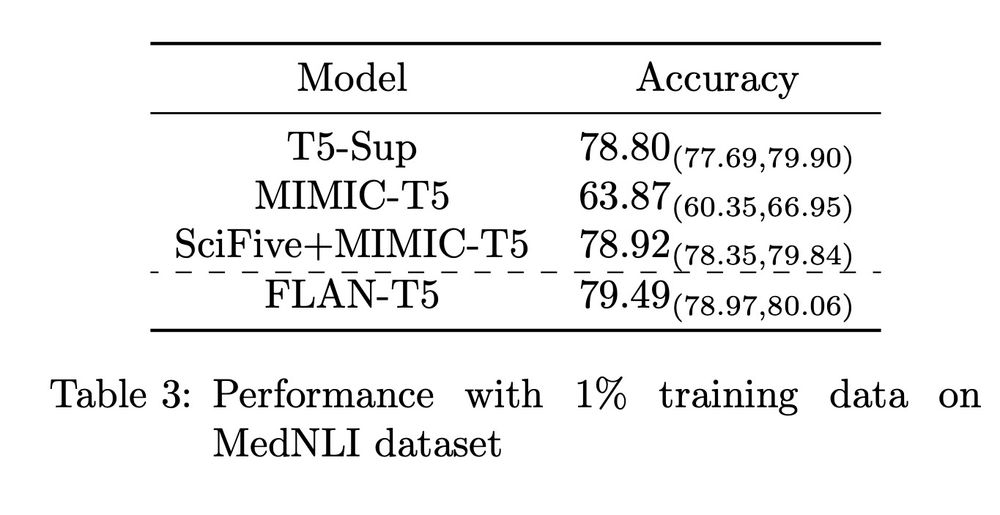
December 22, 2024 at 3:59 PM
It turns out that when you have just a little supervised data, the models trained on more data and tasks, even when out of domain, do BETTER on the new clinical domain.
We try a new clinical task and dataset/domain. In this case, the clinical T5 benefits disappear.
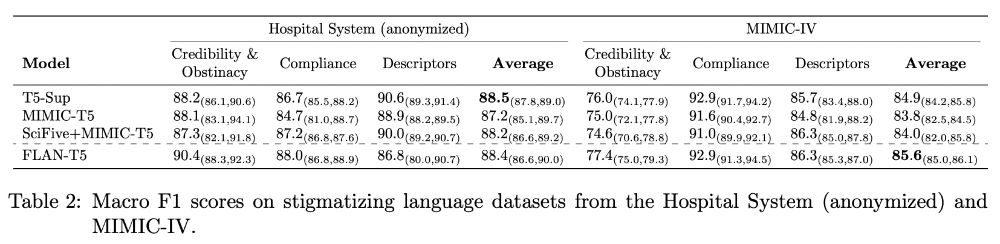
December 22, 2024 at 3:59 PM
We try a new clinical task and dataset/domain. In this case, the clinical T5 benefits disappear.
Comparing 2 clinical with 3 general models on 6 clinical datasets, we find that some clinical models improve. However, these clinical test sets come from the same domain as the clinical training data. Maybe the clinical models are better on THIS clinical data, but not in general?

December 22, 2024 at 3:59 PM
Comparing 2 clinical with 3 general models on 6 clinical datasets, we find that some clinical models improve. However, these clinical test sets come from the same domain as the clinical training data. Maybe the clinical models are better on THIS clinical data, but not in general?
Are Clinical T5 Models Better for Clinical Text? That's the question we asked in our #ML4H2024 paper.
Turns out clinical models may not be worth it. 🧵
arxiv.org/abs/2412.05845
Turns out clinical models may not be worth it. 🧵
arxiv.org/abs/2412.05845

December 22, 2024 at 3:59 PM
Are Clinical T5 Models Better for Clinical Text? That's the question we asked in our #ML4H2024 paper.
Turns out clinical models may not be worth it. 🧵
arxiv.org/abs/2412.05845
Turns out clinical models may not be worth it. 🧵
arxiv.org/abs/2412.05845

Live shot of me answering email.

December 12, 2024 at 7:56 PM
Live shot of me answering email.
Me sitting in the back listening to conference talks and muttering to myself.

December 10, 2024 at 1:03 AM
Me sitting in the back listening to conference talks and muttering to myself.

Still working on my letters this year.

December 3, 2024 at 5:05 PM
Still working on my letters this year.


Even more American.

December 3, 2024 at 2:16 AM
Even more American.
Even more American.

December 3, 2024 at 2:16 AM
Even more American.
Prompt: Draw a picture of an American family at Thanksgiving dinner.

December 3, 2024 at 2:16 AM
Prompt: Draw a picture of an American family at Thanksgiving dinner.
It's that time of the academic year.

December 1, 2024 at 10:55 PM
It's that time of the academic year.

