



Michael Knaus
@mcknaus.bsky.social
Assistant Professor of "Data Science in Economics" at Uni Tübingen. Interested in the intersection of causal inference and so-called machine learning.
Teaching material: https://github.com/MCKnaus/causalML-teaching
Homepage: mcknaus.github.io
Teaching material: https://github.com/MCKnaus/causalML-teaching
Homepage: mcknaus.github.io
🚨Job alert🚨
Premium tenure-track (ass to full prof) in "𝐌𝐋 𝐌𝐞𝐭𝐡𝐨𝐝𝐬 𝐢𝐧 𝐁𝐮𝐬𝐢𝐧𝐞𝐬𝐬 𝐚𝐧𝐝 𝐄𝐜𝐨𝐧𝐨𝐦𝐢𝐜𝐬" @unituebingen.bsky.social made possible by @ml4science.bsky.social
Spread the word and feel free to reach out if you have any questions about the position or the environment.
Link: shorturl.at/QHZ5G
Premium tenure-track (ass to full prof) in "𝐌𝐋 𝐌𝐞𝐭𝐡𝐨𝐝𝐬 𝐢𝐧 𝐁𝐮𝐬𝐢𝐧𝐞𝐬𝐬 𝐚𝐧𝐝 𝐄𝐜𝐨𝐧𝐨𝐦𝐢𝐜𝐬" @unituebingen.bsky.social made possible by @ml4science.bsky.social
Spread the word and feel free to reach out if you have any questions about the position or the environment.
Link: shorturl.at/QHZ5G

September 12, 2025 at 1:25 PM
🚨Job alert🚨
Premium tenure-track (ass to full prof) in "𝐌𝐋 𝐌𝐞𝐭𝐡𝐨𝐝𝐬 𝐢𝐧 𝐁𝐮𝐬𝐢𝐧𝐞𝐬𝐬 𝐚𝐧𝐝 𝐄𝐜𝐨𝐧𝐨𝐦𝐢𝐜𝐬" @unituebingen.bsky.social made possible by @ml4science.bsky.social
Spread the word and feel free to reach out if you have any questions about the position or the environment.
Link: shorturl.at/QHZ5G
Premium tenure-track (ass to full prof) in "𝐌𝐋 𝐌𝐞𝐭𝐡𝐨𝐝𝐬 𝐢𝐧 𝐁𝐮𝐬𝐢𝐧𝐞𝐬𝐬 𝐚𝐧𝐝 𝐄𝐜𝐨𝐧𝐨𝐦𝐢𝐜𝐬" @unituebingen.bsky.social made possible by @ml4science.bsky.social
Spread the word and feel free to reach out if you have any questions about the position or the environment.
Link: shorturl.at/QHZ5G
The OutcomeWeights #RStats package now has a logo and a new vignette illustrating how Double ML improves covariate balance over "Single ML" RA or IPW.
Check it out:
mcknaus.github.io/OutcomeWeigh...
#causalSky #causalML
Check it out:
mcknaus.github.io/OutcomeWeigh...
#causalSky #causalML


May 28, 2025 at 2:11 PM
The OutcomeWeights #RStats package now has a logo and a new vignette illustrating how Double ML improves covariate balance over "Single ML" RA or IPW.
Check it out:
mcknaus.github.io/OutcomeWeigh...
#causalSky #causalML
Check it out:
mcknaus.github.io/OutcomeWeigh...
#causalSky #causalML
One of my favorite parts is running OLS within the DoubleML package of @philippbach.bsky.social and colleagues.
Of course this is unnecessarily complicated, but instructive.
Of course this is unnecessarily complicated, but instructive.

April 25, 2025 at 10:25 AM
One of my favorite parts is running OLS within the DoubleML package of @philippbach.bsky.social and colleagues.
Of course this is unnecessarily complicated, but instructive.
Of course this is unnecessarily complicated, but instructive.
I am a fan of this one, though it is not diverging but converging: doi.org/10.1016/j.ec...
It is so obvious where the policy change happens that it is not even indicated...
It is so obvious where the policy change happens that it is not even indicated...

March 25, 2025 at 11:26 AM
I am a fan of this one, though it is not diverging but converging: doi.org/10.1016/j.ec...
It is so obvious where the policy change happens that it is not even indicated...
It is so obvious where the policy change happens that it is not even indicated...
... which is at least much better than ChatGPT in 2022.

December 12, 2024 at 12:30 PM
... which is at least much better than ChatGPT in 2022.
ChatGPTo1 tells "I have drawn a snowman" when asked to solve the assignment...

December 12, 2024 at 12:30 PM
ChatGPTo1 tells "I have drawn a snowman" when asked to solve the assignment...
Causal Christmas 🎄 Challenge: mcknaus.github.io/assets/cctc/...
My Causal ML students draw sth using 2 potential outcome functions and see how causal forest approximates the resulting CATE fct as bonus assignment. Wanna join the challenge? Share your art in the replies
#rstats #CausalSky #EconSky
My Causal ML students draw sth using 2 potential outcome functions and see how causal forest approximates the resulting CATE fct as bonus assignment. Wanna join the challenge? Share your art in the replies
#rstats #CausalSky #EconSky



December 12, 2024 at 12:30 PM
Causal Christmas 🎄 Challenge: mcknaus.github.io/assets/cctc/...
My Causal ML students draw sth using 2 potential outcome functions and see how causal forest approximates the resulting CATE fct as bonus assignment. Wanna join the challenge? Share your art in the replies
#rstats #CausalSky #EconSky
My Causal ML students draw sth using 2 potential outcome functions and see how causal forest approximates the resulting CATE fct as bonus assignment. Wanna join the challenge? Share your art in the replies
#rstats #CausalSky #EconSky
Concluding
Outcome weights are available for Causal ML building a nice bridge to pscore methods.
The findings regarding weights properties raise questions that I won't answer in this paper.
For now I am happy to provide you with a framework and results telling you that if you want the weight…
Outcome weights are available for Causal ML building a nice bridge to pscore methods.
The findings regarding weights properties raise questions that I won't answer in this paper.
For now I am happy to provide you with a framework and results telling you that if you want the weight…

November 19, 2024 at 12:11 PM
Concluding
Outcome weights are available for Causal ML building a nice bridge to pscore methods.
The findings regarding weights properties raise questions that I won't answer in this paper.
For now I am happy to provide you with a framework and results telling you that if you want the weight…
Outcome weights are available for Causal ML building a nice bridge to pscore methods.
The findings regarding weights properties raise questions that I won't answer in this paper.
For now I am happy to provide you with a framework and results telling you that if you want the weight…
Neat illustration
The formal details are boring and in the paper BUT here is an appetizer.
Note that only fully-normalized estimators estimate an effect of 1 if the outcome is simulated to be Y = 1 + D.
I run default DoubleML/grf functions and only AIPW with RF recovers the true effect of one.
The formal details are boring and in the paper BUT here is an appetizer.
Note that only fully-normalized estimators estimate an effect of 1 if the outcome is simulated to be Y = 1 + D.
I run default DoubleML/grf functions and only AIPW with RF recovers the true effect of one.

November 19, 2024 at 12:11 PM
Neat illustration
The formal details are boring and in the paper BUT here is an appetizer.
Note that only fully-normalized estimators estimate an effect of 1 if the outcome is simulated to be Y = 1 + D.
I run default DoubleML/grf functions and only AIPW with RF recovers the true effect of one.
The formal details are boring and in the paper BUT here is an appetizer.
Note that only fully-normalized estimators estimate an effect of 1 if the outcome is simulated to be Y = 1 + D.
I run default DoubleML/grf functions and only AIPW with RF recovers the true effect of one.
Implementation details are key
It turns out that implementation details control weights properties and that
1. AIPW is fully-normalized in standard implementations
2. PLR(-IV) and causal/instrumental forest are not. Instead their weights are scale-normalized adding to (minus) the same constant.
It turns out that implementation details control weights properties and that
1. AIPW is fully-normalized in standard implementations
2. PLR(-IV) and causal/instrumental forest are not. Instead their weights are scale-normalized adding to (minus) the same constant.


November 19, 2024 at 12:11 PM
Implementation details are key
It turns out that implementation details control weights properties and that
1. AIPW is fully-normalized in standard implementations
2. PLR(-IV) and causal/instrumental forest are not. Instead their weights are scale-normalized adding to (minus) the same constant.
It turns out that implementation details control weights properties and that
1. AIPW is fully-normalized in standard implementations
2. PLR(-IV) and causal/instrumental forest are not. Instead their weights are scale-normalized adding to (minus) the same constant.
Now the fun part
We can investigate whether weights are fully-normalized adding up to 1 for treated and to -1 for controls or falling into other classes (see figure).
This connects nicely to recent work of @tymonsloczynski.bsky.social and @jmwooldridge.bsky.social on Abadie’s kappa estimators.
We can investigate whether weights are fully-normalized adding up to 1 for treated and to -1 for controls or falling into other classes (see figure).
This connects nicely to recent work of @tymonsloczynski.bsky.social and @jmwooldridge.bsky.social on Abadie’s kappa estimators.

November 19, 2024 at 12:11 PM
Now the fun part
We can investigate whether weights are fully-normalized adding up to 1 for treated and to -1 for controls or falling into other classes (see figure).
This connects nicely to recent work of @tymonsloczynski.bsky.social and @jmwooldridge.bsky.social on Abadie’s kappa estimators.
We can investigate whether weights are fully-normalized adding up to 1 for treated and to -1 for controls or falling into other classes (see figure).
This connects nicely to recent work of @tymonsloczynski.bsky.social and @jmwooldridge.bsky.social on Abadie’s kappa estimators.
But how concretely???
Plug&play with the great cobalt package of @noahgreifer.bsky.social and Double ML with random forests. We see that 5-fold cross-fitting improves covariate balancing over 2-folds.
Also tuning causal/instrumental forests improves balancing for C(L)ATE estimates substantially.
Plug&play with the great cobalt package of @noahgreifer.bsky.social and Double ML with random forests. We see that 5-fold cross-fitting improves covariate balancing over 2-folds.
Also tuning causal/instrumental forests improves balancing for C(L)ATE estimates substantially.


November 19, 2024 at 12:11 PM
But how concretely???
Plug&play with the great cobalt package of @noahgreifer.bsky.social and Double ML with random forests. We see that 5-fold cross-fitting improves covariate balancing over 2-folds.
Also tuning causal/instrumental forests improves balancing for C(L)ATE estimates substantially.
Plug&play with the great cobalt package of @noahgreifer.bsky.social and Double ML with random forests. We see that 5-fold cross-fitting improves covariate balancing over 2-folds.
Also tuning causal/instrumental forests improves balancing for C(L)ATE estimates substantially.
But how concretely??
Find attached the derivations for PLR and AIPW. If you want to see even more ugly expressions, check the paper.
If you prefer code over formulas, check the "theory in action notebook" confirming computationally that the math in the paper is correct: shorturl.at/N4I4V
Find attached the derivations for PLR and AIPW. If you want to see even more ugly expressions, check the paper.
If you prefer code over formulas, check the "theory in action notebook" confirming computationally that the math in the paper is correct: shorturl.at/N4I4V




November 19, 2024 at 12:11 PM
But how concretely??
Find attached the derivations for PLR and AIPW. If you want to see even more ugly expressions, check the paper.
If you prefer code over formulas, check the "theory in action notebook" confirming computationally that the math in the paper is correct: shorturl.at/N4I4V
Find attached the derivations for PLR and AIPW. If you want to see even more ugly expressions, check the paper.
If you prefer code over formulas, check the "theory in action notebook" confirming computationally that the math in the paper is correct: shorturl.at/N4I4V
How concretely?
Smoothers, we need smoothers!!! Outcome nuisance parameters have to be estimated using methods like (post-selection) OLS, (kernel) (ridge) or series regressions, tree-based methods, …
Check out @aliciacurth.bsky.social for nice references and cool insights using smoothers in ML.
Smoothers, we need smoothers!!! Outcome nuisance parameters have to be estimated using methods like (post-selection) OLS, (kernel) (ridge) or series regressions, tree-based methods, …
Check out @aliciacurth.bsky.social for nice references and cool insights using smoothers in ML.



November 19, 2024 at 12:11 PM
How concretely?
Smoothers, we need smoothers!!! Outcome nuisance parameters have to be estimated using methods like (post-selection) OLS, (kernel) (ridge) or series regressions, tree-based methods, …
Check out @aliciacurth.bsky.social for nice references and cool insights using smoothers in ML.
Smoothers, we need smoothers!!! Outcome nuisance parameters have to be estimated using methods like (post-selection) OLS, (kernel) (ridge) or series regressions, tree-based methods, …
Check out @aliciacurth.bsky.social for nice references and cool insights using smoothers in ML.
Application of framework
Derive outcome weights for the six leading cases of Double ML and Generalized Random Forest.
Luckily it suffices to do the work for instrumental forest, AIPW and Wald-AIPW. Everything else and also outcome weights documented in the literature follow as special cases.
Derive outcome weights for the six leading cases of Double ML and Generalized Random Forest.
Luckily it suffices to do the work for instrumental forest, AIPW and Wald-AIPW. Everything else and also outcome weights documented in the literature follow as special cases.

November 19, 2024 at 12:11 PM
Application of framework
Derive outcome weights for the six leading cases of Double ML and Generalized Random Forest.
Luckily it suffices to do the work for instrumental forest, AIPW and Wald-AIPW. Everything else and also outcome weights documented in the literature follow as special cases.
Derive outcome weights for the six leading cases of Double ML and Generalized Random Forest.
Luckily it suffices to do the work for instrumental forest, AIPW and Wald-AIPW. Everything else and also outcome weights documented in the literature follow as special cases.
How in general?
Establish numerical equivalence between moment-based and weighted representation.
Insights required:
1. (Almost) everything is an IV (@instrumenthull.bsky.social ll.bsky.social), or at least a pseudo-IV
2. A transformation matrix producing your pseudo-outcome is all you need
Establish numerical equivalence between moment-based and weighted representation.
Insights required:
1. (Almost) everything is an IV (@instrumenthull.bsky.social ll.bsky.social), or at least a pseudo-IV
2. A transformation matrix producing your pseudo-outcome is all you need



November 19, 2024 at 12:11 PM
How in general?
Establish numerical equivalence between moment-based and weighted representation.
Insights required:
1. (Almost) everything is an IV (@instrumenthull.bsky.social ll.bsky.social), or at least a pseudo-IV
2. A transformation matrix producing your pseudo-outcome is all you need
Establish numerical equivalence between moment-based and weighted representation.
Insights required:
1. (Almost) everything is an IV (@instrumenthull.bsky.social ll.bsky.social), or at least a pseudo-IV
2. A transformation matrix producing your pseudo-outcome is all you need
Why?
Outcome weights are a well-established lens to understand how a
concrete estimator implementation processes a
concrete sample to produce a
concrete point estimate.
No asymptotics, expectations or approximations.
Just watch a (potentially complicated multi-stage) estimator digest your sample.
Outcome weights are a well-established lens to understand how a
concrete estimator implementation processes a
concrete sample to produce a
concrete point estimate.
No asymptotics, expectations or approximations.
Just watch a (potentially complicated multi-stage) estimator digest your sample.




November 19, 2024 at 12:11 PM
Why?
Outcome weights are a well-established lens to understand how a
concrete estimator implementation processes a
concrete sample to produce a
concrete point estimate.
No asymptotics, expectations or approximations.
Just watch a (potentially complicated multi-stage) estimator digest your sample.
Outcome weights are a well-established lens to understand how a
concrete estimator implementation processes a
concrete sample to produce a
concrete point estimate.
No asymptotics, expectations or approximations.
Just watch a (potentially complicated multi-stage) estimator digest your sample.
New WP 🚨
1. Recipe to write estimators as weighted outcomes
2. Double ML and causal forests as weighting estimators
3. Plug&play classic covariate balancing checks
4. Explains why Causal ML fails to find an effect of 1 with noiseless outcome Y = 1 + D
5. More fun facts
arxiv.org/abs/2411.11559
1. Recipe to write estimators as weighted outcomes
2. Double ML and causal forests as weighting estimators
3. Plug&play classic covariate balancing checks
4. Explains why Causal ML fails to find an effect of 1 with noiseless outcome Y = 1 + D
5. More fun facts
arxiv.org/abs/2411.11559

November 19, 2024 at 12:11 PM
New WP 🚨
1. Recipe to write estimators as weighted outcomes
2. Double ML and causal forests as weighting estimators
3. Plug&play classic covariate balancing checks
4. Explains why Causal ML fails to find an effect of 1 with noiseless outcome Y = 1 + D
5. More fun facts
arxiv.org/abs/2411.11559
1. Recipe to write estimators as weighted outcomes
2. Double ML and causal forests as weighting estimators
3. Plug&play classic covariate balancing checks
4. Explains why Causal ML fails to find an effect of 1 with noiseless outcome Y = 1 + D
5. More fun facts
arxiv.org/abs/2411.11559
Very happy to contribute to this great initiative to #SupportUkraine
When? April 11th
What? 2h of fun understanding how (easy) DoubleML and Causal Forests of @VC31415 and @Susan_Athey work by replicating R output in few lines of code. #RStats
How? Sign up here t.ly/3weFr
When? April 11th
What? 2h of fun understanding how (easy) DoubleML and Causal Forests of @VC31415 and @Susan_Athey work by replicating R output in few lines of code. #RStats
How? Sign up here t.ly/3weFr

March 4, 2024 at 10:47 AM
Very happy to contribute to this great initiative to #SupportUkraine
When? April 11th
What? 2h of fun understanding how (easy) DoubleML and Causal Forests of @VC31415 and @Susan_Athey work by replicating R output in few lines of code. #RStats
How? Sign up here t.ly/3weFr
When? April 11th
What? 2h of fun understanding how (easy) DoubleML and Causal Forests of @VC31415 and @Susan_Athey work by replicating R output in few lines of code. #RStats
How? Sign up here t.ly/3weFr
This is fun influencemap.cmlab.dev/submit/?id=C...

December 14, 2023 at 12:17 PM
This is fun influencemap.cmlab.dev/submit/?id=C...
Causal Christmas Tree Challenge: mcknaus.github.io/assets/cctc/...
Traditionally my Causal ML students draw sth using two potential outcome functions and see how causal forest approximates the resulting CATE fct.
Wanna join the challenge? Share your "art" in the replies 👇
#EconSky #rstats #CausalSky
Traditionally my Causal ML students draw sth using two potential outcome functions and see how causal forest approximates the resulting CATE fct.
Wanna join the challenge? Share your "art" in the replies 👇
#EconSky #rstats #CausalSky



December 12, 2023 at 2:57 PM
Causal Christmas Tree Challenge: mcknaus.github.io/assets/cctc/...
Traditionally my Causal ML students draw sth using two potential outcome functions and see how causal forest approximates the resulting CATE fct.
Wanna join the challenge? Share your "art" in the replies 👇
#EconSky #rstats #CausalSky
Traditionally my Causal ML students draw sth using two potential outcome functions and see how causal forest approximates the resulting CATE fct.
Wanna join the challenge? Share your "art" in the replies 👇
#EconSky #rstats #CausalSky
The notebook is most useful with the respective slides github.com/MCKnaus/caus...
Full course material here github.com/MCKnaus/caus...
Hope some find it useful.
Full course material here github.com/MCKnaus/caus...
Hope some find it useful.




October 26, 2023 at 3:11 PM
The notebook is most useful with the respective slides github.com/MCKnaus/caus...
Full course material here github.com/MCKnaus/caus...
Hope some find it useful.
Full course material here github.com/MCKnaus/caus...
Hope some find it useful.
Then we leave the linear world and observe how OLS RMSE does not converge anymore while nonparametric methods like kernel regression still converges, though at a slower rate.
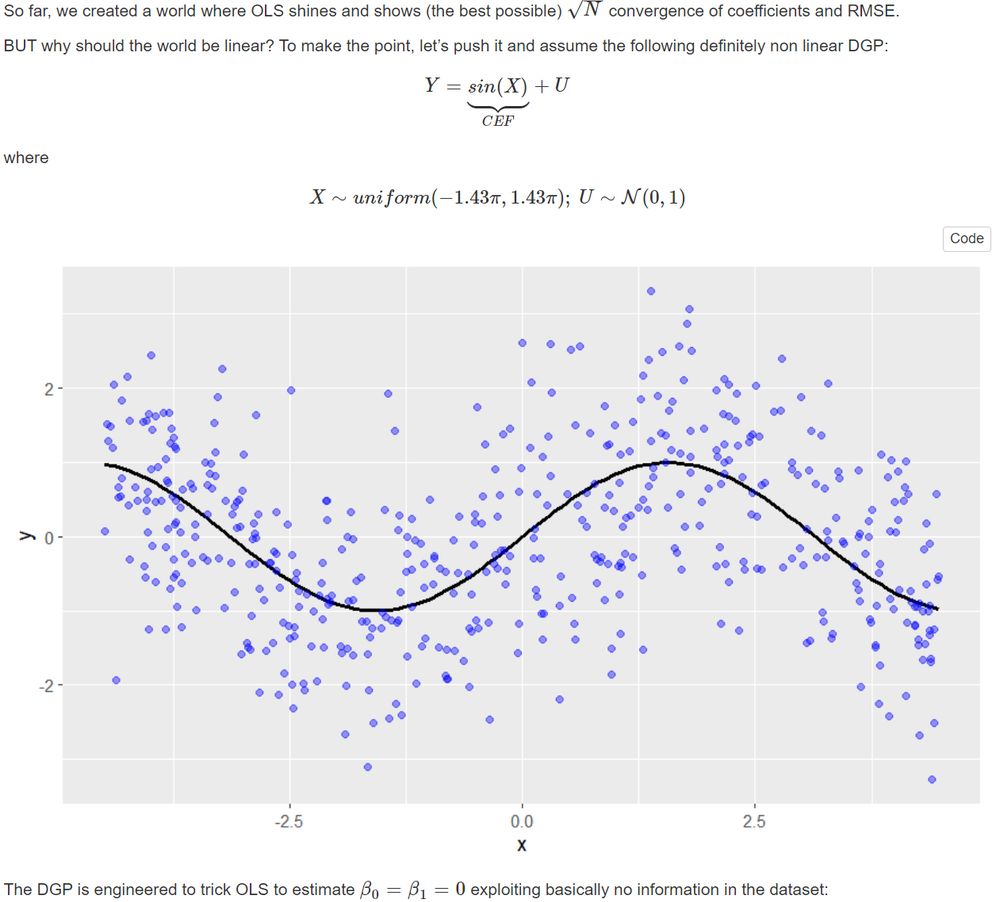

October 26, 2023 at 3:09 PM
Then we leave the linear world and observe how OLS RMSE does not converge anymore while nonparametric methods like kernel regression still converges, though at a slower rate.
Then we proceed to N^1/2 convergence of OLS RMSE in a linear model as this is the type of convergence that is relevant for methods like Double ML.


October 26, 2023 at 3:08 PM
Then we proceed to N^1/2 convergence of OLS RMSE in a linear model as this is the type of convergence that is relevant for methods like Double ML.
“Convergence rates”, mostly in the form of N^1/4 frequently occur in Causal ML methods. In my experience students often lack a good understanding of this crucial concept.
This notebooks starts with N^1/2 convergence of OLS parameters as this is what students should be most familiar with.
This notebooks starts with N^1/2 convergence of OLS parameters as this is what students should be most familiar with.



October 26, 2023 at 3:07 PM
“Convergence rates”, mostly in the form of N^1/4 frequently occur in Causal ML methods. In my experience students often lack a good understanding of this crucial concept.
This notebooks starts with N^1/2 convergence of OLS parameters as this is what students should be most familiar with.
This notebooks starts with N^1/2 convergence of OLS parameters as this is what students should be most familiar with.