



Masoud Jafaripour
@masoudjafaripour.bsky.social
Researcher (CS @UAlbertaCS) working on #Robot_Learning, #RLHF, #Planning, & #LLMs #VLMs, previously @SharifUni, @UnivOfTehran
Reposted by Masoud Jafaripour

This one's been a long time coming.
In this post on Decisions & Dragons I answer "Should we abandon RL?"
The answer is obviously no, but people ask because they have a fundamental misunderstanding of what RL is.
RL is a problem, not an approach.
www.decisionsanddragons.com/posts/should...
In this post on Decisions & Dragons I answer "Should we abandon RL?"
The answer is obviously no, but people ask because they have a fundamental misunderstanding of what RL is.
RL is a problem, not an approach.
www.decisionsanddragons.com/posts/should...
August 15, 2025 at 11:30 PM
This one's been a long time coming.
In this post on Decisions & Dragons I answer "Should we abandon RL?"
The answer is obviously no, but people ask because they have a fundamental misunderstanding of what RL is.
RL is a problem, not an approach.
www.decisionsanddragons.com/posts/should...
In this post on Decisions & Dragons I answer "Should we abandon RL?"
The answer is obviously no, but people ask because they have a fundamental misunderstanding of what RL is.
RL is a problem, not an approach.
www.decisionsanddragons.com/posts/should...
The best video I saw so far on explanation of KL divergence, cross-entropy loss, and their relation/application in LLM training.

Kullback–Leibler (KL) divergence is a cornerstone of machine learning.
We use it everywhere, from training classifiers and distilling knowledge from models, to learning generative models and aligning LLMs.
BUT, what does it mean, and how do we (actually) compute it?
Video: youtu.be/tXE23653JrU
We use it everywhere, from training classifiers and distilling knowledge from models, to learning generative models and aligning LLMs.
BUT, what does it mean, and how do we (actually) compute it?
Video: youtu.be/tXE23653JrU

June 7, 2025 at 3:39 AM
The best video I saw so far on explanation of KL divergence, cross-entropy loss, and their relation/application in LLM training.
Reposted by Masoud Jafaripour

Thrilled to announce that Joshua’s paper won one of three Outstanding Paper awards at ICLR.
Come to the poster on Friday afternoon (#376 in Hall 3) or the talk on Saturday (4:30 in Hall 1), and while you’re at it snag him for a postdoc!
Come to the poster on Friday afternoon (#376 in Hall 3) or the talk on Saturday (4:30 in Hall 1), and while you’re at it snag him for a postdoc!

📢Curious why your LLM behaves strangely after long SFT or DPO?
We offer a fresh perspective—consider doing a "force analysis" on your model’s behavior.
Check out our #ICLR2025 Oral paper:
Learning Dynamics of LLM Finetuning!
(0/12)
We offer a fresh perspective—consider doing a "force analysis" on your model’s behavior.
Check out our #ICLR2025 Oral paper:
Learning Dynamics of LLM Finetuning!
(0/12)

April 23, 2025 at 7:54 AM
Thrilled to announce that Joshua’s paper won one of three Outstanding Paper awards at ICLR.
Come to the poster on Friday afternoon (#376 in Hall 3) or the talk on Saturday (4:30 in Hall 1), and while you’re at it snag him for a postdoc!
Come to the poster on Friday afternoon (#376 in Hall 3) or the talk on Saturday (4:30 in Hall 1), and while you’re at it snag him for a postdoc!
Reposted by Masoud Jafaripour

Smashing the endorse button as fast as I can
www.lesswrong.com/posts/oKAFFv...
www.lesswrong.com/posts/oKAFFv...

A Bear Case: My Predictions Regarding AI Progress — LessWrong
This isn't really a "timeline", as such – I don't know the timings – but this is my current, fairly optimistic take on where we're heading. …
www.lesswrong.com
March 9, 2025 at 9:09 PM
Smashing the endorse button as fast as I can
www.lesswrong.com/posts/oKAFFv...
www.lesswrong.com/posts/oKAFFv...
Reposted by Masoud Jafaripour

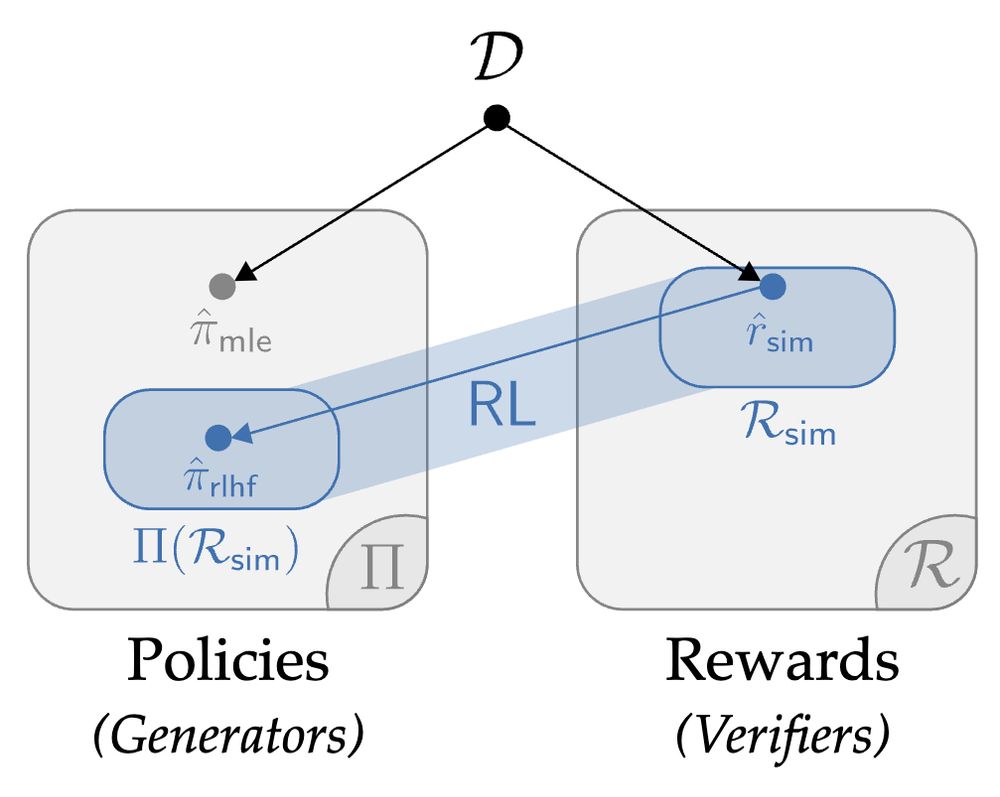
1.5 yrs ago, we set out to answer a seemingly simple question: what are we *actually* getting out of RL in fine-tuning? I'm thrilled to share a pearl we found on the deepest dive of my PhD: the value of RL in RLHF seems to come from *generation-verification gaps*. Get ready to 🤿:
March 4, 2025 at 8:59 PM
1.5 yrs ago, we set out to answer a seemingly simple question: what are we *actually* getting out of RL in fine-tuning? I'm thrilled to share a pearl we found on the deepest dive of my PhD: the value of RL in RLHF seems to come from *generation-verification gaps*. Get ready to 🤿:
Reposted by Masoud Jafaripour

Ever looked at LLM skill emergence and thought 70B parameters was a magic number? Our new paper shows sudden breakthroughs are samples from bimodal performance distributions across seeds. Observed accuracy jumps abruptly while the underlying accuracy DISTRIBUTION changes slowly!

February 25, 2025 at 10:33 PM
Ever looked at LLM skill emergence and thought 70B parameters was a magic number? Our new paper shows sudden breakthroughs are samples from bimodal performance distributions across seeds. Observed accuracy jumps abruptly while the underlying accuracy DISTRIBUTION changes slowly!
Reposted by Masoud Jafaripour

LLMs That Don't Gaslight You
A new language model uses diffusion instead of next-token prediction. That means the text it can back out of a hallucination before it commits. This is a big win for areas like law & contracts, where global consistency is valued
timkellogg.me/blog/2025/02...
A new language model uses diffusion instead of next-token prediction. That means the text it can back out of a hallucination before it commits. This is a big win for areas like law & contracts, where global consistency is valued
timkellogg.me/blog/2025/02...

LLaDA: Large Language Diffusion Models
timkellogg.me
February 17, 2025 at 11:32 PM
LLMs That Don't Gaslight You
A new language model uses diffusion instead of next-token prediction. That means the text it can back out of a hallucination before it commits. This is a big win for areas like law & contracts, where global consistency is valued
timkellogg.me/blog/2025/02...
A new language model uses diffusion instead of next-token prediction. That means the text it can back out of a hallucination before it commits. This is a big win for areas like law & contracts, where global consistency is valued
timkellogg.me/blog/2025/02...
Reposted by Masoud Jafaripour

🔥 allenai/Llama-3.1-Tulu-3-8B (trained with PPO) -> allenai/Llama-3.1-Tulu-3.1-8B (trained with GRPO)
We are happy to "quietly" release our latest GRPO-trained Tulu 3.1 model, which is considerably better in MATH and GSM8K!
We are happy to "quietly" release our latest GRPO-trained Tulu 3.1 model, which is considerably better in MATH and GSM8K!

February 12, 2025 at 5:33 PM
🔥 allenai/Llama-3.1-Tulu-3-8B (trained with PPO) -> allenai/Llama-3.1-Tulu-3.1-8B (trained with GRPO)
We are happy to "quietly" release our latest GRPO-trained Tulu 3.1 model, which is considerably better in MATH and GSM8K!
We are happy to "quietly" release our latest GRPO-trained Tulu 3.1 model, which is considerably better in MATH and GSM8K!
Reposted by Masoud Jafaripour

The Illustrated DeepSeek-R1
Spent the weekend reading the paper and sorting through the intuitions. Here's a visual guide and the main intuitions to understand the model and the process that created it.
newsletter.languagemodels.co/p/the-illust...
Spent the weekend reading the paper and sorting through the intuitions. Here's a visual guide and the main intuitions to understand the model and the process that created it.
newsletter.languagemodels.co/p/the-illust...
January 27, 2025 at 8:22 PM
The Illustrated DeepSeek-R1
Spent the weekend reading the paper and sorting through the intuitions. Here's a visual guide and the main intuitions to understand the model and the process that created it.
newsletter.languagemodels.co/p/the-illust...
Spent the weekend reading the paper and sorting through the intuitions. Here's a visual guide and the main intuitions to understand the model and the process that created it.
newsletter.languagemodels.co/p/the-illust...
Reposted by Masoud Jafaripour

Since everyone wants to learn RL for language models now post DeepSeek, reminder that I've been working on this book quietly in the background for months.
Policy gradient chapter is coming together. Plugging away at the book every day now.
rlhfbook.com/c/11-policy-...
Policy gradient chapter is coming together. Plugging away at the book every day now.
rlhfbook.com/c/11-policy-...

February 1, 2025 at 10:05 PM
Since everyone wants to learn RL for language models now post DeepSeek, reminder that I've been working on this book quietly in the background for months.
Policy gradient chapter is coming together. Plugging away at the book every day now.
rlhfbook.com/c/11-policy-...
Policy gradient chapter is coming together. Plugging away at the book every day now.
rlhfbook.com/c/11-policy-...
Reposted by Masoud Jafaripour
Why reasoning models will generalize
DeepSeek R1 is just the tip of the ice berg of rapid progress.
People underestimate the long-term potential of “reasoning.”
DeepSeek R1 is just the tip of the ice berg of rapid progress.
People underestimate the long-term potential of “reasoning.”

Why reasoning models will generalize
People underestimate the long-term potential of “reasoning.”
buff.ly
January 28, 2025 at 9:04 PM
Why reasoning models will generalize
DeepSeek R1 is just the tip of the ice berg of rapid progress.
People underestimate the long-term potential of “reasoning.”
DeepSeek R1 is just the tip of the ice berg of rapid progress.
People underestimate the long-term potential of “reasoning.”
Reposted by Masoud Jafaripour
apparently RLCoT (chain of thought learned via RL) is in itself an emergent behavior that doesn’t happen until about 1.5B sized models
PPO, GPRO, PRIME — doesn’t matter what RL you use, the key is that it’s RL
experiment logs: wandb.ai/jiayipan/Tin...
x: x.com/jiayi_pirate...
PPO, GPRO, PRIME — doesn’t matter what RL you use, the key is that it’s RL
experiment logs: wandb.ai/jiayipan/Tin...
x: x.com/jiayi_pirate...

jiayipan
Weights & Biases, developer tools for machine learning
wandb.ai
January 25, 2025 at 6:46 PM
apparently RLCoT (chain of thought learned via RL) is in itself an emergent behavior that doesn’t happen until about 1.5B sized models
PPO, GPRO, PRIME — doesn’t matter what RL you use, the key is that it’s RL
experiment logs: wandb.ai/jiayipan/Tin...
x: x.com/jiayi_pirate...
PPO, GPRO, PRIME — doesn’t matter what RL you use, the key is that it’s RL
experiment logs: wandb.ai/jiayipan/Tin...
x: x.com/jiayi_pirate...
Reposted by Masoud Jafaripour
Explainer: What's R1 and Everything Else
This is an attempt to consolidate the dizzying rate of AI developments since Christmas. If you're into AI but not deep enough, this should get you oriented again.
timkellogg.me/blog/2025/01...
This is an attempt to consolidate the dizzying rate of AI developments since Christmas. If you're into AI but not deep enough, this should get you oriented again.
timkellogg.me/blog/2025/01...

January 26, 2025 at 3:17 AM
Explainer: What's R1 and Everything Else
This is an attempt to consolidate the dizzying rate of AI developments since Christmas. If you're into AI but not deep enough, this should get you oriented again.
timkellogg.me/blog/2025/01...
This is an attempt to consolidate the dizzying rate of AI developments since Christmas. If you're into AI but not deep enough, this should get you oriented again.
timkellogg.me/blog/2025/01...
Reposted by Masoud Jafaripour

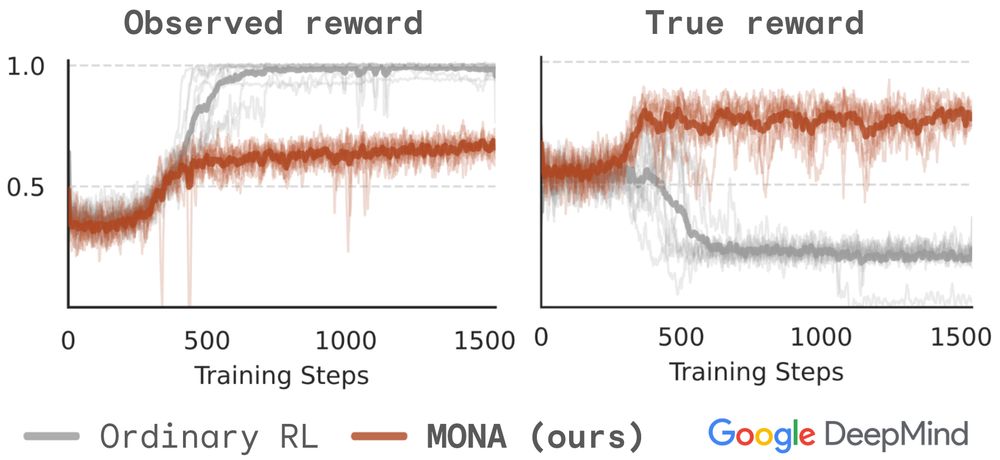
New Google DeepMind safety paper! LLM agents are coming – how do we stop them finding complex plans to hack the reward?
Our method, MONA, prevents many such hacks, *even if* humans are unable to detect them!
Inspired by myopic optimization but better performance – details in🧵
Our method, MONA, prevents many such hacks, *even if* humans are unable to detect them!
Inspired by myopic optimization but better performance – details in🧵
January 23, 2025 at 3:33 PM
New Google DeepMind safety paper! LLM agents are coming – how do we stop them finding complex plans to hack the reward?
Our method, MONA, prevents many such hacks, *even if* humans are unable to detect them!
Inspired by myopic optimization but better performance – details in🧵
Our method, MONA, prevents many such hacks, *even if* humans are unable to detect them!
Inspired by myopic optimization but better performance – details in🧵
Reposted by Masoud Jafaripour

Self-improvement of a population of llms over time: llm-multiagent-ft.github.io

January 14, 2025 at 1:26 AM
Self-improvement of a population of llms over time: llm-multiagent-ft.github.io
Reposted by Masoud Jafaripour

Paper shows very small LLMs can match or beat larger ones through 'deep thinking' - evaluating different solution paths - and other tricks. Their 7B model beats o1-preview on complex math by exploring 64 different solutions & picking the best one.
Test-time compute paradigm seems really fruitful.
Test-time compute paradigm seems really fruitful.

January 11, 2025 at 5:34 AM
Paper shows very small LLMs can match or beat larger ones through 'deep thinking' - evaluating different solution paths - and other tricks. Their 7B model beats o1-preview on complex math by exploring 64 different solutions & picking the best one.
Test-time compute paradigm seems really fruitful.
Test-time compute paradigm seems really fruitful.
Reposted by Masoud Jafaripour
Quick recap on the state of reasoning -- can LMs reason (I say yes, just different than humans)? How?
My talk at the NeurIPS Latent Space live event (pre o3).
Slides: https://buff.ly/40hsoTx
Post: https://buff.ly/40i2rDC
YouTube: https://buff.ly/40k8GH3
My talk at the NeurIPS Latent Space live event (pre o3).
Slides: https://buff.ly/40hsoTx
Post: https://buff.ly/40i2rDC
YouTube: https://buff.ly/40k8GH3

Quick recap on the state of reasoning
My talk at the NeurIPS Latent Space live event.
buff.ly
January 2, 2025 at 4:10 PM
Quick recap on the state of reasoning -- can LMs reason (I say yes, just different than humans)? How?
My talk at the NeurIPS Latent Space live event (pre o3).
Slides: https://buff.ly/40hsoTx
Post: https://buff.ly/40i2rDC
YouTube: https://buff.ly/40k8GH3
My talk at the NeurIPS Latent Space live event (pre o3).
Slides: https://buff.ly/40hsoTx
Post: https://buff.ly/40i2rDC
YouTube: https://buff.ly/40k8GH3
Reposted by Masoud Jafaripour


Reposted by Masoud Jafaripour
Here are the slides for our language modeling tutorial with @kylelo.bsky.social and @akshitab.bsky.social in west ballroom b (ongoing).
docs.google.com/presentation...
docs.google.com/presentation...

[10 December 2024, NeurIPs] Tutorial on Language Modeling
Language Modeling Kyle Lo – Akshita Bhagia – Nathan Lambert Allen Institute of AI [email protected] Neural Information Processing Systems (NeurIPS) 10 December 2024 1
docs.google.com
December 10, 2024 at 6:29 PM
Here are the slides for our language modeling tutorial with @kylelo.bsky.social and @akshitab.bsky.social in west ballroom b (ongoing).
docs.google.com/presentation...
docs.google.com/presentation...
Reposted by Masoud Jafaripour

The slides of my NeurIPS lecture "From Diffusion Models to Schrödinger Bridges - Generative Modeling meets Optimal Transport" can be found here
drive.google.com/file/d/1eLa3...
drive.google.com/file/d/1eLa3...
BreimanLectureNeurIPS2024_Doucet.pdf
drive.google.com
December 15, 2024 at 6:40 PM
The slides of my NeurIPS lecture "From Diffusion Models to Schrödinger Bridges - Generative Modeling meets Optimal Transport" can be found here
drive.google.com/file/d/1eLa3...
drive.google.com/file/d/1eLa3...
Reposted by Masoud Jafaripour

On the different hues of "Inference Time Scaling" (ITS) in LLMs #SundayHarangue
👉 x.com/rao2z/status...
(bsky still doesn't allow long posts, so..)
👉 x.com/rao2z/status...
(bsky still doesn't allow long posts, so..)
x.com
x.com
December 2, 2024 at 5:22 AM
On the different hues of "Inference Time Scaling" (ITS) in LLMs #SundayHarangue
👉 x.com/rao2z/status...
(bsky still doesn't allow long posts, so..)
👉 x.com/rao2z/status...
(bsky still doesn't allow long posts, so..)
Reposted by Masoud Jafaripour

You know how RL is back now? Well, so are our upcoming deadlines

SIGGRAPH'25 (form): 24 days.
RSS'25 (abs): 25 days.
SIGGRAPH'25 (paper-md5): 31 days.
RSS'25 (paper): 32 days.
ICML'25: 38 days.
RLC'25 (abs): 53 days.
RLC'25 (paper): 60 days.
ICCV'25: 73 days.
RSS'25 (abs): 25 days.
SIGGRAPH'25 (paper-md5): 31 days.
RSS'25 (paper): 32 days.
ICML'25: 38 days.
RLC'25 (abs): 53 days.
RLC'25 (paper): 60 days.
ICCV'25: 73 days.
December 23, 2024 at 11:42 PM
You know how RL is back now? Well, so are our upcoming deadlines
Reposted by Masoud Jafaripour
The more time I spend on RLHF, the more I realize the devil is in the details (even more than RL for continuous control). My co-author Zhaolin Gao wrote this excellent blog post on some of these details: huggingface.co/blog/GitBag/.... Maybe it'll be your savior!

RLHF 101: A Technical Dive into RLHF
A Blog post by Zhaolin Gao on Hugging Face
huggingface.co
December 11, 2024 at 8:05 PM
The more time I spend on RLHF, the more I realize the devil is in the details (even more than RL for continuous control). My co-author Zhaolin Gao wrote this excellent blog post on some of these details: huggingface.co/blog/GitBag/.... Maybe it'll be your savior!