




Maryam Shanechi
@maryamshanechi.bsky.social
Sawchuk Chair & Prof at USC Viterbi School of Engineering | Founding Director of USC Center for Neurotech | Developing AI/ML methods & neurotech to decode the brain & treat its conditions 🧠🤖💻 https://nseip.usc.edu/
🚀Overall, our cross-modal distillation can enable high-accuracy and stable LFP models for #BCIs.
👏Eray Erturk, Saba Hashemi
See Eray at #NeurIPS2025
📍Poster Session 1, Hall C,D,E #2115 | Wed 3 Dec | 11AM - 2PM @neuripsconf.bsky.social
📃 openreview.net/forum?id=hT7...
🖥️ github.com/ShanechiLab/...
👏Eray Erturk, Saba Hashemi
See Eray at #NeurIPS2025
📍Poster Session 1, Hall C,D,E #2115 | Wed 3 Dec | 11AM - 2PM @neuripsconf.bsky.social
📃 openreview.net/forum?id=hT7...
🖥️ github.com/ShanechiLab/...
November 25, 2025 at 8:15 PM
🚀Overall, our cross-modal distillation can enable high-accuracy and stable LFP models for #BCIs.
👏Eray Erturk, Saba Hashemi
See Eray at #NeurIPS2025
📍Poster Session 1, Hall C,D,E #2115 | Wed 3 Dec | 11AM - 2PM @neuripsconf.bsky.social
📃 openreview.net/forum?id=hT7...
🖥️ github.com/ShanechiLab/...
👏Eray Erturk, Saba Hashemi
See Eray at #NeurIPS2025
📍Poster Session 1, Hall C,D,E #2115 | Wed 3 Dec | 11AM - 2PM @neuripsconf.bsky.social
📃 openreview.net/forum?id=hT7...
🖥️ github.com/ShanechiLab/...
Our framework achieves:
✅ Substantial decoding performance improvement over several LFP-only baselines
✅ Consistent improvements in unsupervised, supervised & multi-session distillation setups
✅ Generalization to unseen sessions without additional distillation
✅ Spike-aligned LFP latent structure
✅ Substantial decoding performance improvement over several LFP-only baselines
✅ Consistent improvements in unsupervised, supervised & multi-session distillation setups
✅ Generalization to unseen sessions without additional distillation
✅ Spike-aligned LFP latent structure

November 25, 2025 at 8:15 PM
Our framework achieves:
✅ Substantial decoding performance improvement over several LFP-only baselines
✅ Consistent improvements in unsupervised, supervised & multi-session distillation setups
✅ Generalization to unseen sessions without additional distillation
✅ Spike-aligned LFP latent structure
✅ Substantial decoding performance improvement over several LFP-only baselines
✅ Consistent improvements in unsupervised, supervised & multi-session distillation setups
✅ Generalization to unseen sessions without additional distillation
✅ Spike-aligned LFP latent structure
Our framework:
1️⃣ Pretrains a multi-session spike model
2️⃣ Fine-tunes the multi-session spike model on new spike signals
3️⃣ Trains the Distilled LFP model via cross-modal representation alignment
🔥 This produces spike-informed LFP models with significantly improved decoding.
1️⃣ Pretrains a multi-session spike model
2️⃣ Fine-tunes the multi-session spike model on new spike signals
3️⃣ Trains the Distilled LFP model via cross-modal representation alignment
🔥 This produces spike-informed LFP models with significantly improved decoding.

November 25, 2025 at 8:15 PM
Our framework:
1️⃣ Pretrains a multi-session spike model
2️⃣ Fine-tunes the multi-session spike model on new spike signals
3️⃣ Trains the Distilled LFP model via cross-modal representation alignment
🔥 This produces spike-informed LFP models with significantly improved decoding.
1️⃣ Pretrains a multi-session spike model
2️⃣ Fine-tunes the multi-session spike model on new spike signals
3️⃣ Trains the Distilled LFP model via cross-modal representation alignment
🔥 This produces spike-informed LFP models with significantly improved decoding.
Why this matters:
🧠 LFPs are used in many #BCIs and have high stability, but often underperform for behavior decoding compared with spikes.
❓ We ask: Can we transfer representational knowledge from spike models → LFP models?
✅ Answer: Yes — and the gains are substantial!
🧠 LFPs are used in many #BCIs and have high stability, but often underperform for behavior decoding compared with spikes.
❓ We ask: Can we transfer representational knowledge from spike models → LFP models?
✅ Answer: Yes — and the gains are substantial!
November 25, 2025 at 8:15 PM
Why this matters:
🧠 LFPs are used in many #BCIs and have high stability, but often underperform for behavior decoding compared with spikes.
❓ We ask: Can we transfer representational knowledge from spike models → LFP models?
✅ Answer: Yes — and the gains are substantial!
🧠 LFPs are used in many #BCIs and have high stability, but often underperform for behavior decoding compared with spikes.
❓ We ask: Can we transfer representational knowledge from spike models → LFP models?
✅ Answer: Yes — and the gains are substantial!
Excited for SBIND to support neural image modalities, thus expanding our prior neural-behavioral models:
PSID & DPAD (Nat Neuro 2021 & 2024), IPSID (PNAS 2024), PGLDM (NeurIPS 2024), BRAID (ICLR 2025)
📜 Paper: openreview.net/pdf?id=k4KVh...
💻Code: github.com/shanechiLab/...
PSID & DPAD (Nat Neuro 2021 & 2024), IPSID (PNAS 2024), PGLDM (NeurIPS 2024), BRAID (ICLR 2025)
📜 Paper: openreview.net/pdf?id=k4KVh...
💻Code: github.com/shanechiLab/...
July 14, 2025 at 5:46 PM
Excited for SBIND to support neural image modalities, thus expanding our prior neural-behavioral models:
PSID & DPAD (Nat Neuro 2021 & 2024), IPSID (PNAS 2024), PGLDM (NeurIPS 2024), BRAID (ICLR 2025)
📜 Paper: openreview.net/pdf?id=k4KVh...
💻Code: github.com/shanechiLab/...
PSID & DPAD (Nat Neuro 2021 & 2024), IPSID (PNAS 2024), PGLDM (NeurIPS 2024), BRAID (ICLR 2025)
📜 Paper: openreview.net/pdf?id=k4KVh...
💻Code: github.com/shanechiLab/...
Also on public data (🙏to Churchland, Andersen, and Shapiro labs)
✅ Self-attention improves neural-behavior predictions by learning long-range patterns while convolutions learn local ones
✅ Two-stage learning improves behavior prediction by disentangling behaviorally relevant dynamics
✅ Self-attention improves neural-behavior predictions by learning long-range patterns while convolutions learn local ones
✅ Two-stage learning improves behavior prediction by disentangling behaviorally relevant dynamics

July 14, 2025 at 5:46 PM
Also on public data (🙏to Churchland, Andersen, and Shapiro labs)
✅ Self-attention improves neural-behavior predictions by learning long-range patterns while convolutions learn local ones
✅ Two-stage learning improves behavior prediction by disentangling behaviorally relevant dynamics
✅ Self-attention improves neural-behavior predictions by learning long-range patterns while convolutions learn local ones
✅ Two-stage learning improves behavior prediction by disentangling behaviorally relevant dynamics
On public widefield calcium (Churchland lab) and functional ultrasound (Andersen and Shapiro labs) neural imaging data, SBIND outperforms other neural-behavioral models in decoding continuous and categorical behaviors in visual decision-making and memory-guided saccade tasks.
July 14, 2025 at 5:46 PM
On public widefield calcium (Churchland lab) and functional ultrasound (Andersen and Shapiro labs) neural imaging data, SBIND outperforms other neural-behavioral models in decoding continuous and categorical behaviors in visual decision-making and memory-guided saccade tasks.
SBIND:
✅ Operates directly on raw images & avoids preprocessing.
✅ Combines self-attention and convolutional layers to model both global and local patterns.
✅ Uses two-stage learning of convolutional RNNs (ConvRNNs) to disentangle behaviorally relevant and other neural dynamics.
✅ Operates directly on raw images & avoids preprocessing.
✅ Combines self-attention and convolutional layers to model both global and local patterns.
✅ Uses two-stage learning of convolutional RNNs (ConvRNNs) to disentangle behaviorally relevant and other neural dynamics.

July 14, 2025 at 5:46 PM
SBIND:
✅ Operates directly on raw images & avoids preprocessing.
✅ Combines self-attention and convolutional layers to model both global and local patterns.
✅ Uses two-stage learning of convolutional RNNs (ConvRNNs) to disentangle behaviorally relevant and other neural dynamics.
✅ Operates directly on raw images & avoids preprocessing.
✅ Combines self-attention and convolutional layers to model both global and local patterns.
✅ Uses two-stage learning of convolutional RNNs (ConvRNNs) to disentangle behaviorally relevant and other neural dynamics.
Excited for BRAID to expand our neural-behavioral models: PSID & DPAD (Nat Neurosci 2020 & 2024), PGLDM (NeurIPS 2024), IPSID (PNAS 2024)!
See Parsa Vahidi at #ICLR2025!
📍Poster Session 5, Hall 3+Hall 2B #57 | Sat 4/26 | 10AM - 12:30PM
📜 openreview.net/forum?id=3us...
💻 github.com/ShanechiLab/...
See Parsa Vahidi at #ICLR2025!
📍Poster Session 5, Hall 3+Hall 2B #57 | Sat 4/26 | 10AM - 12:30PM
📜 openreview.net/forum?id=3us...
💻 github.com/ShanechiLab/...
April 21, 2025 at 7:43 PM
Excited for BRAID to expand our neural-behavioral models: PSID & DPAD (Nat Neurosci 2020 & 2024), PGLDM (NeurIPS 2024), IPSID (PNAS 2024)!
See Parsa Vahidi at #ICLR2025!
📍Poster Session 5, Hall 3+Hall 2B #57 | Sat 4/26 | 10AM - 12:30PM
📜 openreview.net/forum?id=3us...
💻 github.com/ShanechiLab/...
See Parsa Vahidi at #ICLR2025!
📍Poster Session 5, Hall 3+Hall 2B #57 | Sat 4/26 | 10AM - 12:30PM
📜 openreview.net/forum?id=3us...
💻 github.com/ShanechiLab/...
On public motor cortex data during reaching from the Sabes lab, BRAID outperformed several baselines in neural-behavioral predictions by capturing nonlinearity, modeling sensory task instructions as input, and disentangling intrinsic behaviorally relevant neural dynamics.

April 21, 2025 at 7:40 PM
On public motor cortex data during reaching from the Sabes lab, BRAID outperformed several baselines in neural-behavioral predictions by capturing nonlinearity, modeling sensory task instructions as input, and disentangling intrinsic behaviorally relevant neural dynamics.
In nonlinear simulations, BRAID accurately disentangled intrinsic neural-behavioral dynamics from input dynamics. In terms of learning the intrinsic dynamics and decoding behavior, BRAID outperformed prior neural-behavioral models, which either don’t include input or are linear.

April 21, 2025 at 7:40 PM
In nonlinear simulations, BRAID accurately disentangled intrinsic neural-behavioral dynamics from input dynamics. In terms of learning the intrinsic dynamics and decoding behavior, BRAID outperformed prior neural-behavioral models, which either don’t include input or are linear.
BRAID
✅ Disentangles intrinsic behaviorally relevant neural dynamics from input, neural-specific & behavior-specific dynamics
✅ Captures nonlinearity
It is a multi-stage RNN: each stage learns a subtype of dynamics & combines a predictor network w/ a generative network to learn intrinsic dynamics.
✅ Disentangles intrinsic behaviorally relevant neural dynamics from input, neural-specific & behavior-specific dynamics
✅ Captures nonlinearity
It is a multi-stage RNN: each stage learns a subtype of dynamics & combines a predictor network w/ a generative network to learn intrinsic dynamics.

April 21, 2025 at 7:40 PM
BRAID
✅ Disentangles intrinsic behaviorally relevant neural dynamics from input, neural-specific & behavior-specific dynamics
✅ Captures nonlinearity
It is a multi-stage RNN: each stage learns a subtype of dynamics & combines a predictor network w/ a generative network to learn intrinsic dynamics.
✅ Disentangles intrinsic behaviorally relevant neural dynamics from input, neural-specific & behavior-specific dynamics
✅ Captures nonlinearity
It is a multi-stage RNN: each stage learns a subtype of dynamics & combines a predictor network w/ a generative network to learn intrinsic dynamics.
You can see our poster at #ICLR2025!
📍 Poster Session 1, Hall 3 + Hall 2B, #68 | Thu, Apr 24 | 10 AM - 12:30 PM
Poster: iclr.cc/virtual/2025...
📜 💻Paper and code: openreview.net/pdf?id=mkDam...
📍 Poster Session 1, Hall 3 + Hall 2B, #68 | Thu, Apr 24 | 10 AM - 12:30 PM
Poster: iclr.cc/virtual/2025...
📜 💻Paper and code: openreview.net/pdf?id=mkDam...
April 17, 2025 at 6:55 PM
You can see our poster at #ICLR2025!
📍 Poster Session 1, Hall 3 + Hall 2B, #68 | Thu, Apr 24 | 10 AM - 12:30 PM
Poster: iclr.cc/virtual/2025...
📜 💻Paper and code: openreview.net/pdf?id=mkDam...
📍 Poster Session 1, Hall 3 + Hall 2B, #68 | Thu, Apr 24 | 10 AM - 12:30 PM
Poster: iclr.cc/virtual/2025...
📜 💻Paper and code: openreview.net/pdf?id=mkDam...
On public neural data from the mice head direction circuit from Buzsáki lab, PGPCA outperforms baselines across all state dimensions. Also, interestingly, the geometric coordinate outperforms the Euclidean one, showing that the noise around the manifold also follows the same geometry.

April 17, 2025 at 6:55 PM
On public neural data from the mice head direction circuit from Buzsáki lab, PGPCA outperforms baselines across all state dimensions. Also, interestingly, the geometric coordinate outperforms the Euclidean one, showing that the noise around the manifold also follows the same geometry.
In simulations, PGPCA recovers the true data distribution and distinguishes between different coordinates (geometric vs. Euclidean) regardless of the manifold state distribution p(z). Also, PGPCA outperforms Probabilistic PCA (PPCA) in modeling data around a nonlinear manifold.

April 17, 2025 at 6:55 PM
In simulations, PGPCA recovers the true data distribution and distinguishes between different coordinates (geometric vs. Euclidean) regardless of the manifold state distribution p(z). Also, PGPCA outperforms Probabilistic PCA (PPCA) in modeling data around a nonlinear manifold.
PGPCA decomposes the data distribution p(y) into a state distribution on a nonlinear manifold p(z) plus a deviation from the manifold captured by the distribution coordinate K(z). K(z) can be Euclidean or geometric, as we derive. A new algorithm learns the model parameters.

April 17, 2025 at 6:55 PM
PGPCA decomposes the data distribution p(y) into a state distribution on a nonlinear manifold p(z) plus a deviation from the manifold captured by the distribution coordinate K(z). K(z) can be Euclidean or geometric, as we derive. A new algorithm learns the model parameters.
Overall, multiscale SID is particularly beneficial when efficient & accurate multimodal learning and fusion are desired.
👏 Congrats Parima Ahmadipour & Omid Sani. Thanks to collaborator Bijan Pesaran.
📜Paper: iopscience.iop.org/article/10.1...
💻Code: github.com/ShanechiLab/...
👏 Congrats Parima Ahmadipour & Omid Sani. Thanks to collaborator Bijan Pesaran.
📜Paper: iopscience.iop.org/article/10.1...
💻Code: github.com/ShanechiLab/...
December 18, 2024 at 7:17 PM
Overall, multiscale SID is particularly beneficial when efficient & accurate multimodal learning and fusion are desired.
👏 Congrats Parima Ahmadipour & Omid Sani. Thanks to collaborator Bijan Pesaran.
📜Paper: iopscience.iop.org/article/10.1...
💻Code: github.com/ShanechiLab/...
👏 Congrats Parima Ahmadipour & Omid Sani. Thanks to collaborator Bijan Pesaran.
📜Paper: iopscience.iop.org/article/10.1...
💻Code: github.com/ShanechiLab/...
Also, compared to multiscale EM, multiscale SID has a much lower training time, coupled with a better accuracy in dynamical mode identification and a better or similar accuracy in predicting neural activity and behavior.
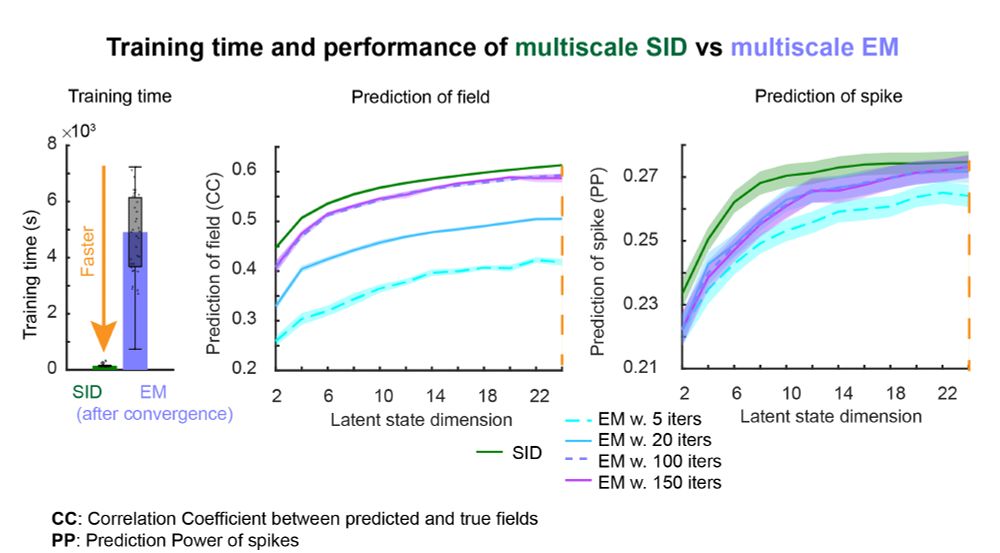
December 18, 2024 at 7:17 PM
Also, compared to multiscale EM, multiscale SID has a much lower training time, coupled with a better accuracy in dynamical mode identification and a better or similar accuracy in predicting neural activity and behavior.
Using neural data recorded during arm movements, we show that multiscale SID can fuse information across spiking & field potential neural modalities. This results in improved learning of dynamical modes & better behavior (movement) prediction compared to using a single modality.
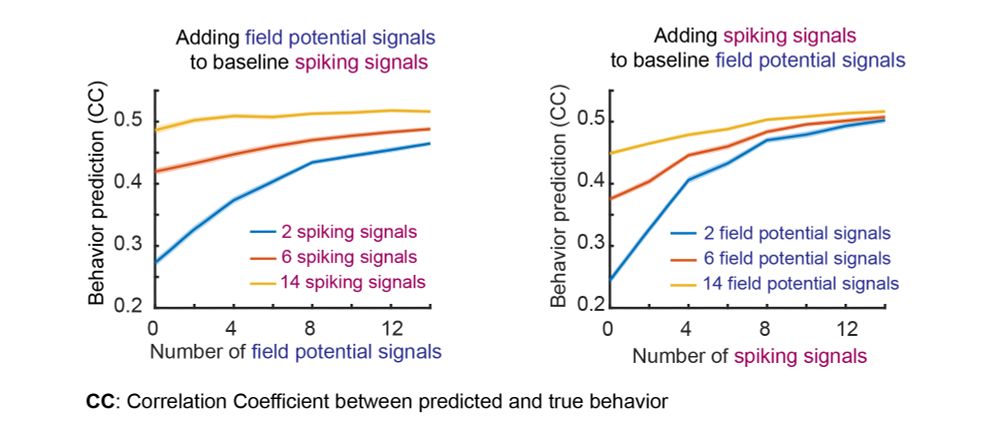
December 18, 2024 at 7:17 PM
Using neural data recorded during arm movements, we show that multiscale SID can fuse information across spiking & field potential neural modalities. This results in improved learning of dynamical modes & better behavior (movement) prediction compared to using a single modality.
We develop multiscale SID, a computationally efficient learning method that extends subspace identification (SID) to multimodal time-series. We also introduce a constrained optimization to learn valid noise statistics, which enables multimodal statistical inference. Inference can be done causally.
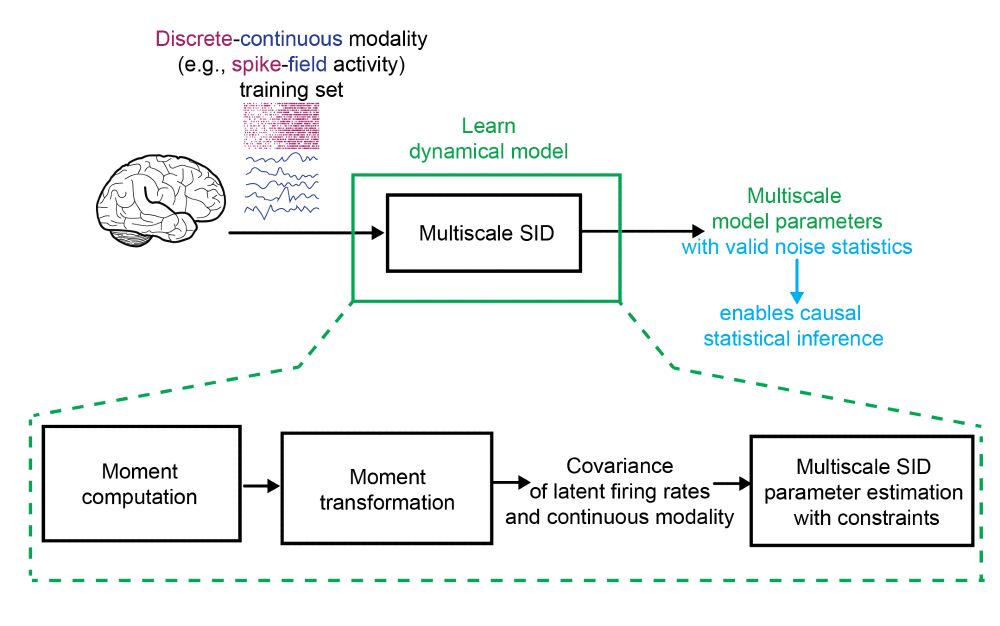
December 18, 2024 at 7:17 PM
We develop multiscale SID, a computationally efficient learning method that extends subspace identification (SID) to multimodal time-series. We also introduce a constrained optimization to learn valid noise statistics, which enables multimodal statistical inference. Inference can be done causally.
Learning dynamical models of multimodal time-series (e.g., spike-LFP neural data) can reveal their collective dynamics & enable multimodal fusion to improve decoding (e.g., of behavior). But this learning often relies on expectation-maximization (EM), which is iterative & slow.
December 18, 2024 at 7:17 PM
Learning dynamical models of multimodal time-series (e.g., spike-LFP neural data) can reveal their collective dynamics & enable multimodal fusion to improve decoding (e.g., of behavior). But this learning often relies on expectation-maximization (EM), which is iterative & slow.