



Martin Hebart
@martinhebart.bsky.social
Proud dad, Professor of Computational Cognitive Neuroscience, author of The Decoding Toolbox, founder of http://things-initiative.org
our lab 👉 https://hebartlab.com
our lab 👉 https://hebartlab.com
Huge congrats to Philipp Kaniuth for successfully defending his PhD summa cum laude (with distinction) “on the measurement of representations and similarity”! Phil was my first PhD candidate, so it’s a particularly special event for me, and he can be very proud of his achievements!

November 20, 2025 at 6:16 PM
Huge congrats to Philipp Kaniuth for successfully defending his PhD summa cum laude (with distinction) “on the measurement of representations and similarity”! Phil was my first PhD candidate, so it’s a particularly special event for me, and he can be very proud of his achievements!
Please repost! I am looking for a PhD candidate in the area of Computational Cognitive Neuroscience to start in early 2026.
The position is funded as part of the Excellence Cluster "The Adaptive Mind" at @jlugiessen.bsky.social.
Please apply here until Nov 25:
www.uni-giessen.de/de/ueber-uns...
The position is funded as part of the Excellence Cluster "The Adaptive Mind" at @jlugiessen.bsky.social.
Please apply here until Nov 25:
www.uni-giessen.de/de/ueber-uns...

November 4, 2025 at 1:57 PM
Please repost! I am looking for a PhD candidate in the area of Computational Cognitive Neuroscience to start in early 2026.
The position is funded as part of the Excellence Cluster "The Adaptive Mind" at @jlugiessen.bsky.social.
Please apply here until Nov 25:
www.uni-giessen.de/de/ueber-uns...
The position is funded as part of the Excellence Cluster "The Adaptive Mind" at @jlugiessen.bsky.social.
Please apply here until Nov 25:
www.uni-giessen.de/de/ueber-uns...
The similarity embedding enabled us to make sense of actions as a combination of their behaviorally-relevant dimensions (relevant w.r.t. similarity judgments, i.e. for categorization and making sense of the world).

October 27, 2025 at 7:23 PM
The similarity embedding enabled us to make sense of actions as a combination of their behaviorally-relevant dimensions (relevant w.r.t. similarity judgments, i.e. for categorization and making sense of the world).
Andre carefully curated a set of 768 1s movies from 256 action categories. Using a triplet odd-one-out tasking 6,036 workers, he found 28 interpretable dimensions underlying these similarity judgments. Here are just 6 of them.

October 27, 2025 at 7:23 PM
Andre carefully curated a set of 768 1s movies from 256 action categories. Using a triplet odd-one-out tasking 6,036 workers, he found 28 interpretable dimensions underlying these similarity judgments. Here are just 6 of them.
Pretty amazing how you can learn something in books and in school and it explains everything around you - how the planets move, etc. But then it’s just next level when you can see it is real, with your own eyes.


September 7, 2025 at 7:25 PM
Pretty amazing how you can learn something in books and in school and it explains everything around you - how the planets move, etc. But then it’s just next level when you can see it is real, with your own eyes.
It’s easier to see if you focus on the bottom or top! It’s just a pattern of blobs. Do you see it now? On the left like bush or like half butterflies. On the right like eye glasses.


September 4, 2025 at 5:27 PM
It’s easier to see if you focus on the bottom or top! It’s just a pattern of blobs. Do you see it now? On the left like bush or like half butterflies. On the right like eye glasses.
The photo was blurry, so that reduces the effect! It’s easier to see here.
I would also like to know more about what is known in that age range!
I would also like to know more about what is known in that age range!

September 4, 2025 at 5:11 PM
The photo was blurry, so that reduces the effect! It’s easier to see here.
I would also like to know more about what is known in that age range!
I would also like to know more about what is known in that age range!
Later I realized that my son had experienced a version of Rubin’s illusion, also known as the face-vase illusion. If you look closely at the Batman logo, you can also make the background stick out. My son thought the illusion was real and that he had discovered a way to change the logo to a pattern.

September 4, 2025 at 3:40 PM
Later I realized that my son had experienced a version of Rubin’s illusion, also known as the face-vase illusion. If you look closely at the Batman logo, you can also make the background stick out. My son thought the illusion was real and that he had discovered a way to change the logo to a pattern.
Today I had a curious encounter with my 4-yo son. He told me he discovered that his Batman action figure could switch the Batman logo to something else. He showed me, touched its arm, shook it and said: “there, it changed.”
The thing is: the logo is fixed and cannot change. So what had happened?
The thing is: the logo is fixed and cannot change. So what had happened?

September 4, 2025 at 3:40 PM
Today I had a curious encounter with my 4-yo son. He told me he discovered that his Batman action figure could switch the Batman logo to something else. He showed me, touched its arm, shook it and said: “there, it changed.”
The thing is: the logo is fixed and cannot change. So what had happened?
The thing is: the logo is fixed and cannot change. So what had happened?
Really happy that PhD candidate Malin Styrnal in our lab won both the Best Student Poster Award *and* the Poster of the Day Award at #ECVP2025 for her presentation "The similarity of similarity tasks: Comparing eight different measures of similarity"! (unfortunately no photo with her!)
Go Malin! 🥳
Go Malin! 🥳

August 29, 2025 at 3:21 PM
Really happy that PhD candidate Malin Styrnal in our lab won both the Best Student Poster Award *and* the Poster of the Day Award at #ECVP2025 for her presentation "The similarity of similarity tasks: Comparing eight different measures of similarity"! (unfortunately no photo with her!)
Go Malin! 🥳
Go Malin! 🥳
Very much looking forward to #CCN2025! Would love to see you at our lab's talks and posters, and meet me at the panel discussion in the Algonauts session on Wednesday!

August 11, 2025 at 10:52 AM
Very much looking forward to #CCN2025! Would love to see you at our lab's talks and posters, and meet me at the panel discussion in the Algonauts session on Wednesday!
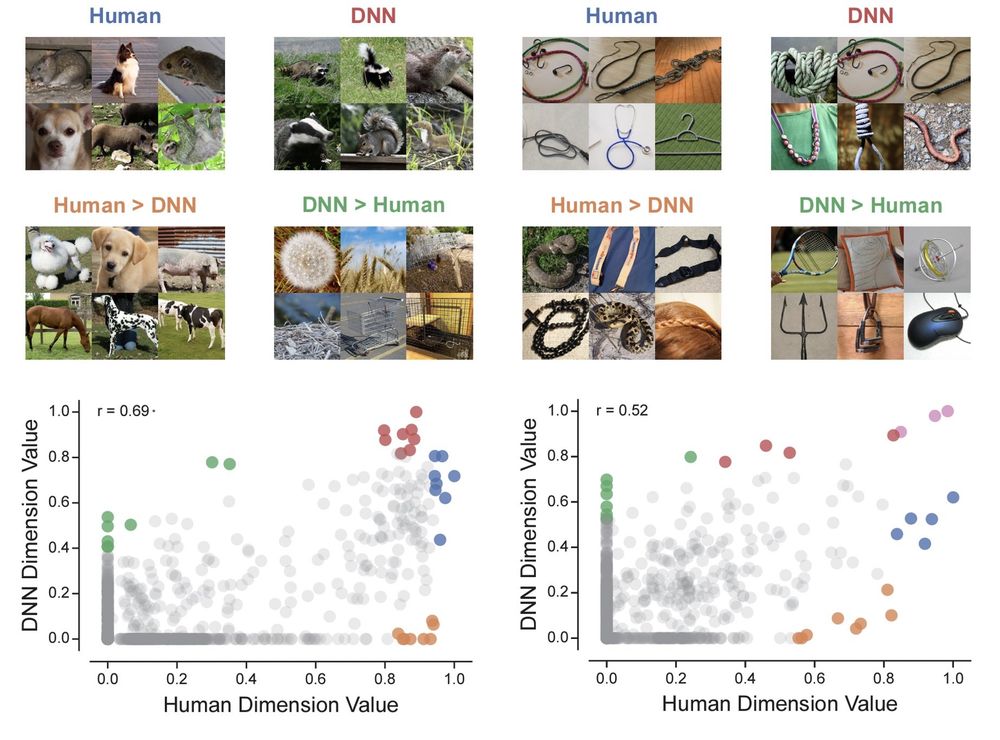
However, when looking at the differences, there were clear examples where the DNN dimension yielded low values when the human dimension was clearly high (e.g., animals in an “animal-related”), or where the DNN dimension was high when it should be low (e.g., a shopping cart) 13/n
June 23, 2025 at 8:03 PM
However, when looking at the differences, there were clear examples where the DNN dimension yielded low values when the human dimension was clearly high (e.g., animals in an “animal-related”), or where the DNN dimension was high when it should be low (e.g., a shopping cart) 13/n
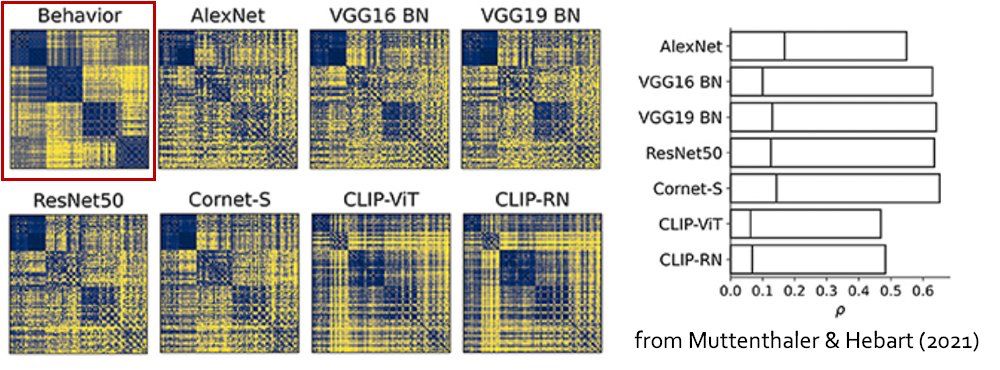
However, what was still missing was a face-to-face comparison with humans. For that, we used the most human-AI aligned pairs of dimensions. At a first glance, again it seemed as if they reflected similar information 12/n

June 23, 2025 at 8:03 PM
However, what was still missing was a face-to-face comparison with humans. For that, we used the most human-AI aligned pairs of dimensions. At a first glance, again it seemed as if they reflected similar information 12/n
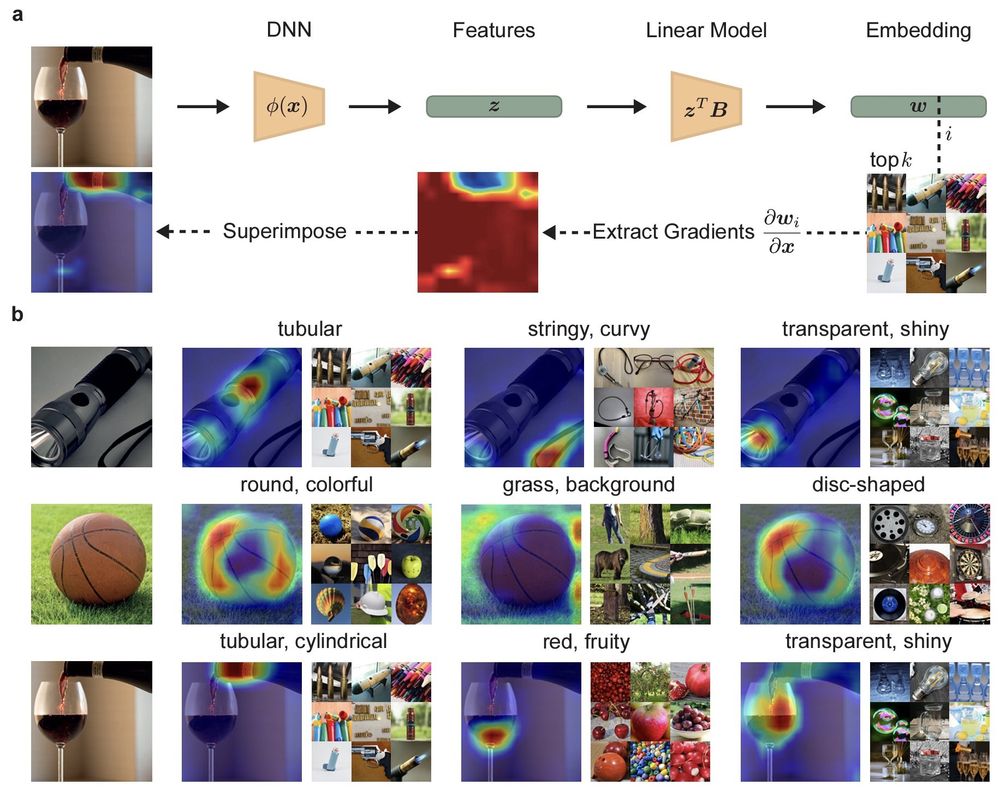
We first created heatmaps of relevant image regions for individual image dimensions using GradCam. The results made sense: For example, an alleged technology dimension highlighted the button of a flashlight as informative about technology. 10/n
June 23, 2025 at 8:03 PM
We first created heatmaps of relevant image regions for individual image dimensions using GradCam. The results made sense: For example, an alleged technology dimension highlighted the button of a flashlight as informative about technology. 10/n
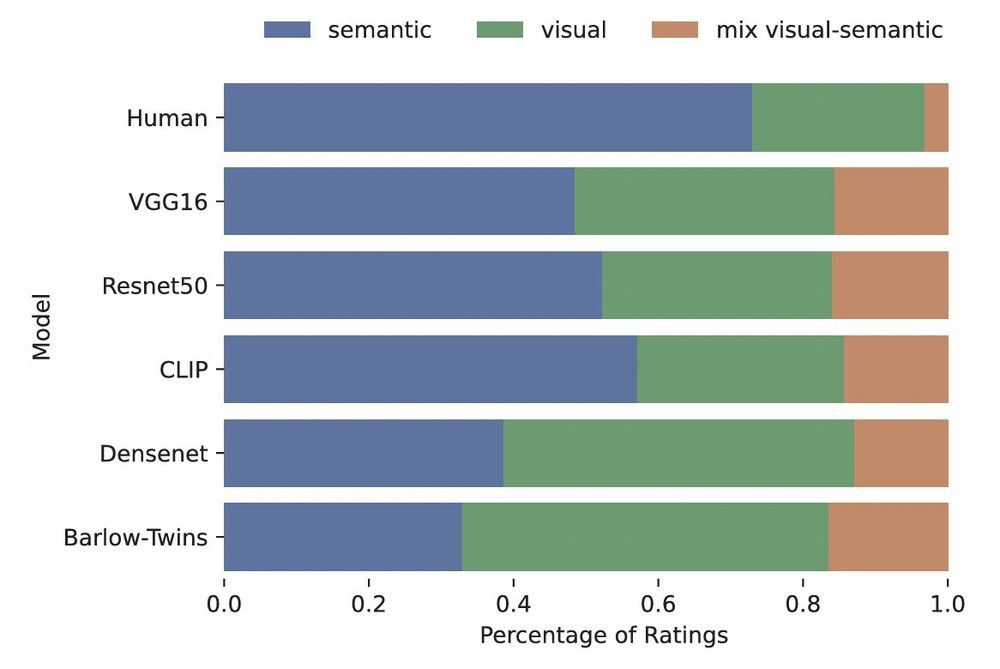
This visual bias wasn’t specific to VGG-16. We repeated the same dimension identification approach for other common network architectures and found a similar bias across all tested networks. 7/n
June 23, 2025 at 8:03 PM
This visual bias wasn’t specific to VGG-16. We repeated the same dimension identification approach for other common network architectures and found a similar bias across all tested networks. 7/n
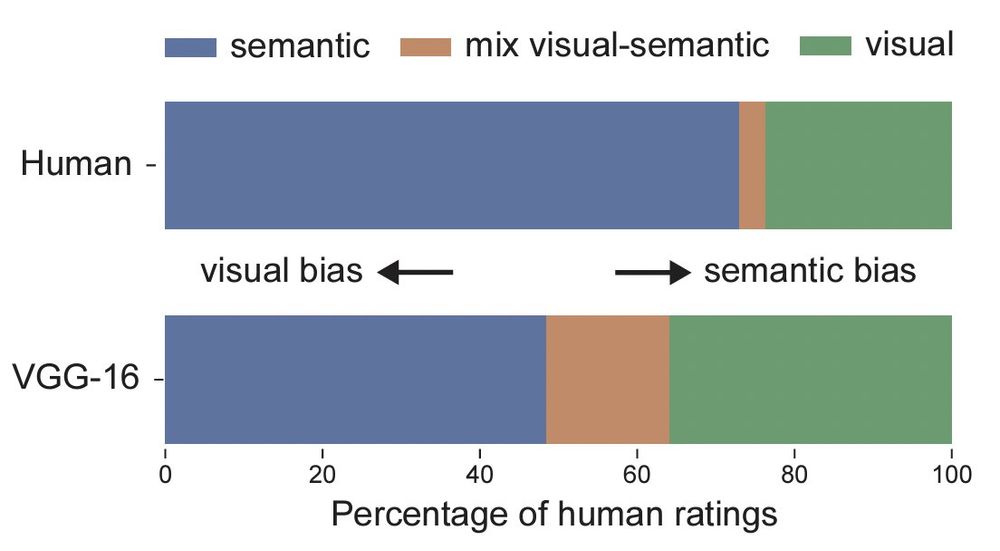
However, this comparison already revealed an important difference. When we quantified the proportion of visual, semantic, and mixed dimensions, it turned out that human representations were much more semantic, while the DNN was dominated by visual dimensions. 6/n
June 23, 2025 at 8:03 PM
However, this comparison already revealed an important difference. When we quantified the proportion of visual, semantic, and mixed dimensions, it turned out that human representations were much more semantic, while the DNN was dominated by visual dimensions. 6/n
Using the penultimate layer of the common VGG-16 architecture, we found 70 representational dimensions. At a first glance they appeared to be largely interpretable, reflecting visual and semantic object dimensions. Some of them even appeared to encode basic shape features. 5/n

June 23, 2025 at 8:03 PM
Using the penultimate layer of the common VGG-16 architecture, we found 70 representational dimensions. At a first glance they appeared to be largely interpretable, reflecting visual and semantic object dimensions. Some of them even appeared to encode basic shape features. 5/n
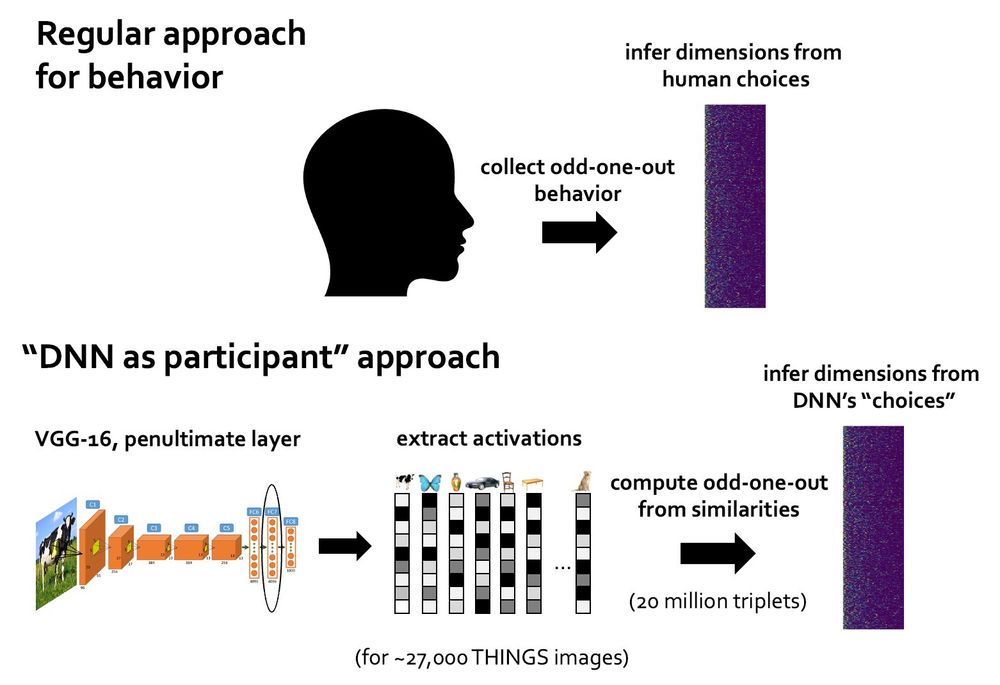
Equivalently to humans, we can then infer the core representational dimensions from these similarity “judgments”. This now enables us to directly compare representational dimensions in humans with those found in deep nets! So, what do we find? 4/n
June 23, 2025 at 8:03 PM
Equivalently to humans, we can then infer the core representational dimensions from these similarity “judgments”. This now enables us to directly compare representational dimensions in humans with those found in deep nets! So, what do we find? 4/n
To address this, we adapted a recent approach in cognitive science for identifying core representational dimensions underlying human similarity judgments in an odd-one-out task. The trick: We treat a deep neural network representation as a human playing the odd-one-out game. 3/n

June 23, 2025 at 8:03 PM
To address this, we adapted a recent approach in cognitive science for identifying core representational dimensions underlying human similarity judgments in an odd-one-out task. The trick: We treat a deep neural network representation as a human playing the odd-one-out game. 3/n
How can we compare human and AI representation? A popular approach is studying representational similarities. But this method only informs about the *degree* of alignment. Without clear hypotheses, we do not know *what it actually is* that makes them similar or different. 2/n
June 23, 2025 at 8:03 PM
How can we compare human and AI representation? A popular approach is studying representational similarities. But this method only informs about the *degree* of alignment. Without clear hypotheses, we do not know *what it actually is* that makes them similar or different. 2/n
A more personal note: my sister Alexandra is a professional singer in the Northern German Radio Choir. She has a great solo tonight at 8pm CET in the Hamburg Elbe philharmonic hall. If you like Italian baroque, tune in online:
www.ndr.de/orchester_ch...
www.ndr.de/orchester_ch...

June 20, 2025 at 1:24 PM
A more personal note: my sister Alexandra is a professional singer in the Northern German Radio Choir. She has a great solo tonight at 8pm CET in the Hamburg Elbe philharmonic hall. If you like Italian baroque, tune in online:
www.ndr.de/orchester_ch...
www.ndr.de/orchester_ch...
Leaving after an intense visit to the US to my #VSS2025 science fam, to @lisik.bsky.social & Mick Bonner at Johns Hopkins, to my science fam at NIH w/ @cibaker.bsky.social & to my old home DC & APS meeting (🙏 Lila Chrysikou!) where I met many scientific heros. Leaving with very sentimental feelings!

May 25, 2025 at 10:21 PM
Leaving after an intense visit to the US to my #VSS2025 science fam, to @lisik.bsky.social & Mick Bonner at Johns Hopkins, to my science fam at NIH w/ @cibaker.bsky.social & to my old home DC & APS meeting (🙏 Lila Chrysikou!) where I met many scientific heros. Leaving with very sentimental feelings!
The final talk of #CAOS2025 is given by @taliakonkle.bsky.social highlighting how we can use deep learning to learn about the inductive biases and the features learned and used in vision.

May 9, 2025 at 2:59 PM
The final talk of #CAOS2025 is given by @taliakonkle.bsky.social highlighting how we can use deep learning to learn about the inductive biases and the features learned and used in vision.
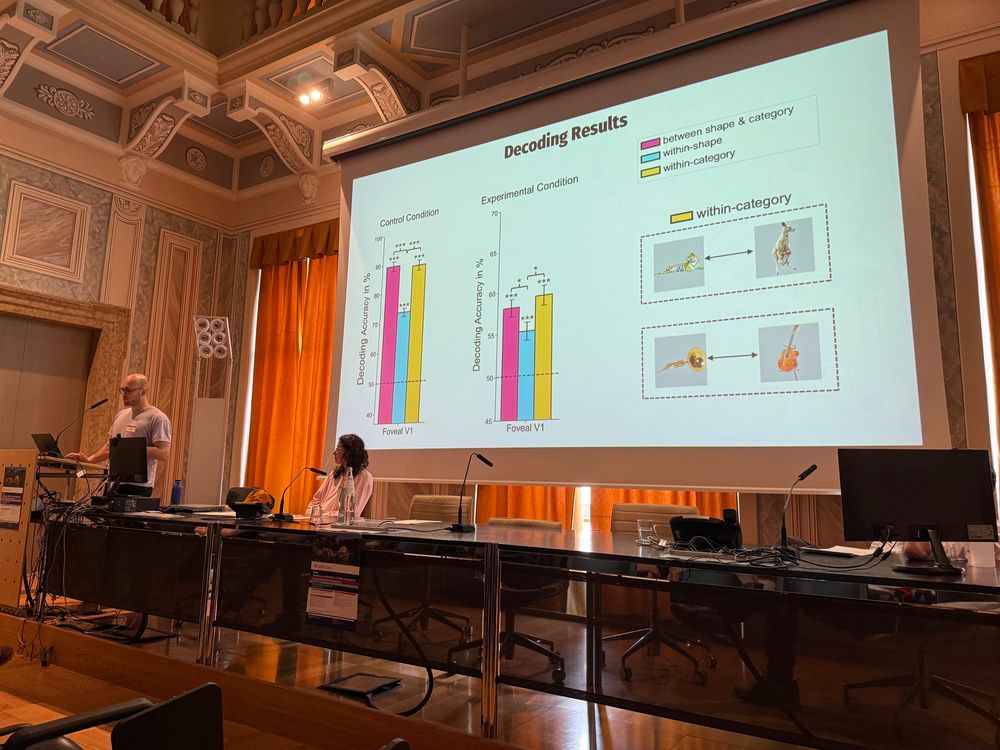
One of the student award winners is @lucakaemmer.bsky.social who showed feedback to foveal early visual cortex during the preparation of saccades that also reflects the content of what participants see. #CAOS2025
May 9, 2025 at 12:19 PM
One of the student award winners is @lucakaemmer.bsky.social who showed feedback to foveal early visual cortex during the preparation of saccades that also reflects the content of what participants see. #CAOS2025
Next up is Jeff Bowers criticizing conclusions drawn about the performance of deep learning approaches as explanatory models of vision and language. #CAOS2025 Looking forward to the discussions after the talk.

May 9, 2025 at 9:55 AM
Next up is Jeff Bowers criticizing conclusions drawn about the performance of deep learning approaches as explanatory models of vision and language. #CAOS2025 Looking forward to the discussions after the talk.