



Marzena Karpinska
@markar.bsky.social
#nlp researcher interested in evaluation including: multilingual models, long-form input/output, processing/generation of creative texts
previous: postdoc @ umass_nlp
phd from utokyo
https://marzenakrp.github.io/
previous: postdoc @ umass_nlp
phd from utokyo
https://marzenakrp.github.io/
Reposted by Marzena Karpinska

🚨New paper on AI & copyright
Authors have sued LLM companies for using books w/o permission for model training.
Courts however need empirical evidence of market harm. Our preregistered study exactly addresses this gap.
Joint work w Jane Ginsburg from Columbia Law and @dhillonp.bsky.social 1/n🧵
Authors have sued LLM companies for using books w/o permission for model training.
Courts however need empirical evidence of market harm. Our preregistered study exactly addresses this gap.
Joint work w Jane Ginsburg from Columbia Law and @dhillonp.bsky.social 1/n🧵

October 22, 2025 at 4:54 PM
🚨New paper on AI & copyright
Authors have sued LLM companies for using books w/o permission for model training.
Courts however need empirical evidence of market harm. Our preregistered study exactly addresses this gap.
Joint work w Jane Ginsburg from Columbia Law and @dhillonp.bsky.social 1/n🧵
Authors have sued LLM companies for using books w/o permission for model training.
Courts however need empirical evidence of market harm. Our preregistered study exactly addresses this gap.
Joint work w Jane Ginsburg from Columbia Law and @dhillonp.bsky.social 1/n🧵
Reposted by Marzena Karpinska

Well this is sure to be a blockbuster AI article... @jennarussell.bsky.social et al are kicking ass and taking names in journalism, both individuals and organizations.
"AI use in American newspapers is widespread, uneven, and rarely disclosed"
arxiv.org/abs/2510.18774
"AI use in American newspapers is widespread, uneven, and rarely disclosed"
arxiv.org/abs/2510.18774


October 23, 2025 at 1:53 PM
Well this is sure to be a blockbuster AI article... @jennarussell.bsky.social et al are kicking ass and taking names in journalism, both individuals and organizations.
"AI use in American newspapers is widespread, uneven, and rarely disclosed"
arxiv.org/abs/2510.18774
"AI use in American newspapers is widespread, uneven, and rarely disclosed"
arxiv.org/abs/2510.18774
AI is infiltrating American newsrooms.
Sadly, it is mostly *undisclosed* meaning that readers are often unaware that they are consuming LLM text.
Even worse, we find some of these texts making it to the print press (undisclosed)
Can we at least be honest about using models for editing?
Sadly, it is mostly *undisclosed* meaning that readers are often unaware that they are consuming LLM text.
Even worse, we find some of these texts making it to the print press (undisclosed)
Can we at least be honest about using models for editing?
AI is already at work in American newsrooms.
We examine 186k articles published this summer and find that ~9% are either fully or partially AI-generated, usually without readers having any idea.
Here's what we learned about how AI is influencing local and national journalism:
We examine 186k articles published this summer and find that ~9% are either fully or partially AI-generated, usually without readers having any idea.
Here's what we learned about how AI is influencing local and national journalism:

October 22, 2025 at 10:32 PM
AI is infiltrating American newsrooms.
Sadly, it is mostly *undisclosed* meaning that readers are often unaware that they are consuming LLM text.
Even worse, we find some of these texts making it to the print press (undisclosed)
Can we at least be honest about using models for editing?
Sadly, it is mostly *undisclosed* meaning that readers are often unaware that they are consuming LLM text.
Even worse, we find some of these texts making it to the print press (undisclosed)
Can we at least be honest about using models for editing?
Reposted by Marzena Karpinska

AI is already at work in American newsrooms.
We examine 186k articles published this summer and find that ~9% are either fully or partially AI-generated, usually without readers having any idea.
Here's what we learned about how AI is influencing local and national journalism:
We examine 186k articles published this summer and find that ~9% are either fully or partially AI-generated, usually without readers having any idea.
Here's what we learned about how AI is influencing local and national journalism:
October 22, 2025 at 3:24 PM
AI is already at work in American newsrooms.
We examine 186k articles published this summer and find that ~9% are either fully or partially AI-generated, usually without readers having any idea.
Here's what we learned about how AI is influencing local and national journalism:
We examine 186k articles published this summer and find that ~9% are either fully or partially AI-generated, usually without readers having any idea.
Here's what we learned about how AI is influencing local and national journalism:
Reposted by Marzena Karpinska

📢 Announcing the First Workshop on Multilingual and Multicultural Evaluation (MME) at #EACL2026 🇲🇦
MME focuses on resources, metrics & methodologies for evaluating multilingual systems! multilingual-multicultural-evaluation.github.io
📅 Workshop Mar 24–29, 2026
🗓️ Submit by Dec 19, 2025
MME focuses on resources, metrics & methodologies for evaluating multilingual systems! multilingual-multicultural-evaluation.github.io
📅 Workshop Mar 24–29, 2026
🗓️ Submit by Dec 19, 2025

October 20, 2025 at 10:37 AM
📢 Announcing the First Workshop on Multilingual and Multicultural Evaluation (MME) at #EACL2026 🇲🇦
MME focuses on resources, metrics & methodologies for evaluating multilingual systems! multilingual-multicultural-evaluation.github.io
📅 Workshop Mar 24–29, 2026
🗓️ Submit by Dec 19, 2025
MME focuses on resources, metrics & methodologies for evaluating multilingual systems! multilingual-multicultural-evaluation.github.io
📅 Workshop Mar 24–29, 2026
🗓️ Submit by Dec 19, 2025
Reposted by Marzena Karpinska

I'd love to see someone try to estimate just how much time and money has gone into research that is either fully undermined by reliance on LLMs or fully pointless --- because obvious if you start from an understanding of what LLMs actually are.
www.pnas.org/doi/10.1073/...
www.pnas.org/doi/10.1073/...

October 18, 2025 at 10:11 AM
I'd love to see someone try to estimate just how much time and money has gone into research that is either fully undermined by reliance on LLMs or fully pointless --- because obvious if you start from an understanding of what LLMs actually are.
www.pnas.org/doi/10.1073/...
www.pnas.org/doi/10.1073/...
I'm not sure why people lost the ability to do related work properly but if you absolutely need to use AI at least proofread it? (And they most likely edited with ai)
www.pangram.com/history/01bf...
www.pangram.com/history/01bf...

October 18, 2025 at 4:18 PM
I'm not sure why people lost the ability to do related work properly but if you absolutely need to use AI at least proofread it? (And they most likely edited with ai)
www.pangram.com/history/01bf...
www.pangram.com/history/01bf...
Reposted by Marzena Karpinska

The viral "Definition of AGI" paper tells you to read fake references which do not exist!
Proof: different articles present at the specified journal/volume/page number, and their titles exist nowhere on any searchable repository.
Take this as a warning to not use LMs to generate your references!
Proof: different articles present at the specified journal/volume/page number, and their titles exist nowhere on any searchable repository.
Take this as a warning to not use LMs to generate your references!




October 18, 2025 at 12:54 AM
The viral "Definition of AGI" paper tells you to read fake references which do not exist!
Proof: different articles present at the specified journal/volume/page number, and their titles exist nowhere on any searchable repository.
Take this as a warning to not use LMs to generate your references!
Proof: different articles present at the specified journal/volume/page number, and their titles exist nowhere on any searchable repository.
Take this as a warning to not use LMs to generate your references!
Reposted by Marzena Karpinska
𝑵𝒆𝒘 𝒃𝒍𝒐𝒈𝒑𝒐𝒔𝒕! A rundown of some cool papers I got to chat about at #COLM2025 and some scattered thoughts
saxon.me/blog/2025/co...
saxon.me/blog/2025/co...

COLM 2025: 9 cool papers and some thoughts
Reflections on the 2025 COLM conference, and a discussion of 9 cool COLM papers on benchmarking and eval, personas, and improving models for better long-context performance and consistency.
saxon.me
October 17, 2025 at 5:24 AM
𝑵𝒆𝒘 𝒃𝒍𝒐𝒈𝒑𝒐𝒔𝒕! A rundown of some cool papers I got to chat about at #COLM2025 and some scattered thoughts
saxon.me/blog/2025/co...
saxon.me/blog/2025/co...
Come to talk with us today about the evaluation of long form multilingual generation at the second poster session #COLM2025
📍4:30–6:30 PM / Room 710 – Poster #8
📍4:30–6:30 PM / Room 710 – Poster #8

October 7, 2025 at 5:54 PM
Come to talk with us today about the evaluation of long form multilingual generation at the second poster session #COLM2025
📍4:30–6:30 PM / Room 710 – Poster #8
📍4:30–6:30 PM / Room 710 – Poster #8



Reposted by Marzena Karpinska

When reading AI reasoning text (aka CoT), we (humans) form a narrative about the underlying computation process, which we take as a transparent explanation of model behavior. But what if our narratives are wrong? We measure that and find it usually is.
Now on arXiv: arxiv.org/abs/2508.16599
Now on arXiv: arxiv.org/abs/2508.16599

Humans Perceive Wrong Narratives from AI Reasoning Texts
A new generation of AI models generates step-by-step reasoning text before producing an answer. This text appears to offer a human-readable window into their computation process, and is increasingly r...
arxiv.org
August 27, 2025 at 9:30 PM
When reading AI reasoning text (aka CoT), we (humans) form a narrative about the underlying computation process, which we take as a transparent explanation of model behavior. But what if our narratives are wrong? We measure that and find it usually is.
Now on arXiv: arxiv.org/abs/2508.16599
Now on arXiv: arxiv.org/abs/2508.16599
Reposted by Marzena Karpinska

📊 Preliminary ranking of WMT 2025 General Machine Translation benchmark is here!
But don't draw conclusions just yet - automatic metrics are biased for techniques like metric as a reward model or MBR. The official human ranking will be part of General MT findings at WMT.
arxiv.org/abs/2508.14909
But don't draw conclusions just yet - automatic metrics are biased for techniques like metric as a reward model or MBR. The official human ranking will be part of General MT findings at WMT.
arxiv.org/abs/2508.14909

Preliminary Ranking of WMT25 General Machine Translation Systems
We present the preliminary ranking of the WMT25 General Machine Translation Shared Task, in which MT systems have been evaluated using automatic metrics. As this ranking is based on automatic evaluati...
arxiv.org
August 23, 2025 at 9:28 AM
📊 Preliminary ranking of WMT 2025 General Machine Translation benchmark is here!
But don't draw conclusions just yet - automatic metrics are biased for techniques like metric as a reward model or MBR. The official human ranking will be part of General MT findings at WMT.
arxiv.org/abs/2508.14909
But don't draw conclusions just yet - automatic metrics are biased for techniques like metric as a reward model or MBR. The official human ranking will be part of General MT findings at WMT.
arxiv.org/abs/2508.14909
Happy to see this work accepted to #EMNLP2025! 🎉🎉🎉

August 20, 2025 at 8:49 PM
Happy to see this work accepted to #EMNLP2025! 🎉🎉🎉
Reposted by Marzena Karpinska

✨We are thrilled to announce that over 3200 papers have been accepted to #EMNLP2025 ✨
This includes over 1800 main conference papers and over 1400 papers in findings!
Congratulations to all authors!! 🎉🎉🎉
This includes over 1800 main conference papers and over 1400 papers in findings!
Congratulations to all authors!! 🎉🎉🎉
August 20, 2025 at 8:47 PM
✨We are thrilled to announce that over 3200 papers have been accepted to #EMNLP2025 ✨
This includes over 1800 main conference papers and over 1400 papers in findings!
Congratulations to all authors!! 🎉🎉🎉
This includes over 1800 main conference papers and over 1400 papers in findings!
Congratulations to all authors!! 🎉🎉🎉
Reposted by Marzena Karpinska

The Echoes in AI paper showed quite the opposite with also a story continuation setup.
Additionally, we present evidence that both *syntactic* and *discourse* diversity measures show strong homogenization that lexical and cosine used in this paper do not capture.
Additionally, we present evidence that both *syntactic* and *discourse* diversity measures show strong homogenization that lexical and cosine used in this paper do not capture.



August 12, 2025 at 9:01 PM
The Echoes in AI paper showed quite the opposite with also a story continuation setup.
Additionally, we present evidence that both *syntactic* and *discourse* diversity measures show strong homogenization that lexical and cosine used in this paper do not capture.
Additionally, we present evidence that both *syntactic* and *discourse* diversity measures show strong homogenization that lexical and cosine used in this paper do not capture.
GPT-5 lands first place on NoCha, our long-context book understanding benchmark.
That said, this is a tiny improvement (~1%) over o1-preview, which was released almost one year ago. Have long-context models hit a wall?
Accuracy of human readers is >97%... Long way to go!
That said, this is a tiny improvement (~1%) over o1-preview, which was released almost one year ago. Have long-context models hit a wall?
Accuracy of human readers is >97%... Long way to go!
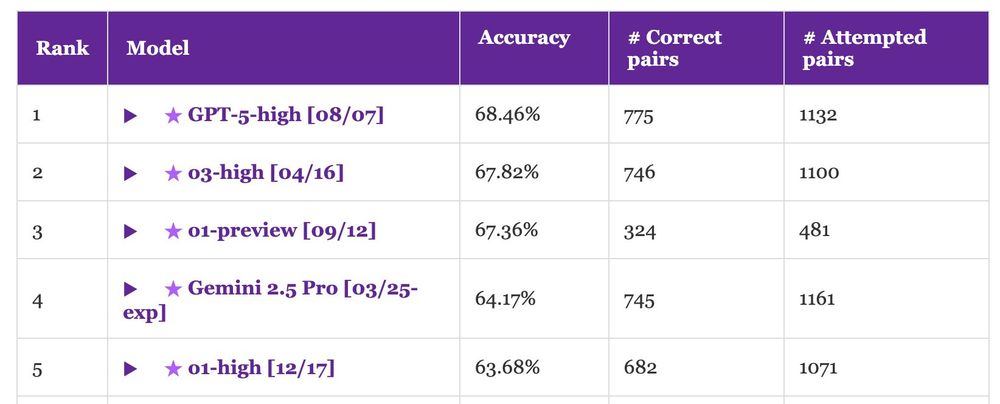
August 8, 2025 at 2:13 AM
GPT-5 lands first place on NoCha, our long-context book understanding benchmark.
That said, this is a tiny improvement (~1%) over o1-preview, which was released almost one year ago. Have long-context models hit a wall?
Accuracy of human readers is >97%... Long way to go!
That said, this is a tiny improvement (~1%) over o1-preview, which was released almost one year ago. Have long-context models hit a wall?
Accuracy of human readers is >97%... Long way to go!
Reposted by Marzena Karpinska

🗓️29 July, 4 PM: Automated main concept generation for narrative discourse assessment in aphasia. w/
@marisahudspeth.bsky.social, Polly Stokes, Jacquie Kurland, and @brenocon.bsky.social
📍Hall 4/5.
Come by to chat about argumentation, narrative texts, policy & law, and beyond! #ACL2025NLP
@marisahudspeth.bsky.social, Polly Stokes, Jacquie Kurland, and @brenocon.bsky.social
📍Hall 4/5.
Come by to chat about argumentation, narrative texts, policy & law, and beyond! #ACL2025NLP

July 28, 2025 at 10:57 AM
🗓️29 July, 4 PM: Automated main concept generation for narrative discourse assessment in aphasia. w/
@marisahudspeth.bsky.social, Polly Stokes, Jacquie Kurland, and @brenocon.bsky.social
📍Hall 4/5.
Come by to chat about argumentation, narrative texts, policy & law, and beyond! #ACL2025NLP
@marisahudspeth.bsky.social, Polly Stokes, Jacquie Kurland, and @brenocon.bsky.social
📍Hall 4/5.
Come by to chat about argumentation, narrative texts, policy & law, and beyond! #ACL2025NLP
Reposted by Marzena Karpinska
Excited to present two papers at #ACL2025!
🗓️30 July, 11 AM: 𝛿-Stance: A Large-Scale Real World Dataset of Stances in Legal Argumentation. w/ Douglas Rice and @brenocon.bsky.social
📍At Hall 4/5. 🧵👇
🗓️30 July, 11 AM: 𝛿-Stance: A Large-Scale Real World Dataset of Stances in Legal Argumentation. w/ Douglas Rice and @brenocon.bsky.social
📍At Hall 4/5. 🧵👇

July 28, 2025 at 10:57 AM
Excited to present two papers at #ACL2025!
🗓️30 July, 11 AM: 𝛿-Stance: A Large-Scale Real World Dataset of Stances in Legal Argumentation. w/ Douglas Rice and @brenocon.bsky.social
📍At Hall 4/5. 🧵👇
🗓️30 July, 11 AM: 𝛿-Stance: A Large-Scale Real World Dataset of Stances in Legal Argumentation. w/ Douglas Rice and @brenocon.bsky.social
📍At Hall 4/5. 🧵👇
Reposted by Marzena Karpinska

📣 Life update: Thrilled to announce that I’ll be starting as faculty at the Max Planck Institute for Software Systems this Fall!
I’ll be recruiting PhD students in the upcoming cycle, as well as research interns throughout the year: lasharavichander.github.io/contact.html
I’ll be recruiting PhD students in the upcoming cycle, as well as research interns throughout the year: lasharavichander.github.io/contact.html

July 22, 2025 at 4:12 AM
📣 Life update: Thrilled to announce that I’ll be starting as faculty at the Max Planck Institute for Software Systems this Fall!
I’ll be recruiting PhD students in the upcoming cycle, as well as research interns throughout the year: lasharavichander.github.io/contact.html
I’ll be recruiting PhD students in the upcoming cycle, as well as research interns throughout the year: lasharavichander.github.io/contact.html
Reposted by Marzena Karpinska
For EMNLP 2025’s special theme of "Advancing our Reach: Interdisciplinary Recontextualization of NLP", we are organizing a panel of experts, and would like input from the community at large as we prepare. Please take a moment to fill in this survey: forms.office.com/r/pWFFA0Gss1
July 17, 2025 at 8:23 PM
For EMNLP 2025’s special theme of "Advancing our Reach: Interdisciplinary Recontextualization of NLP", we are organizing a panel of experts, and would like input from the community at large as we prepare. Please take a moment to fill in this survey: forms.office.com/r/pWFFA0Gss1
Reposted by Marzena Karpinska

A new definition for AGI just dropped, and it is a bad one.

lord grant me the courage to write with the confidence a mediocre white man

July 12, 2025 at 6:04 PM
A new definition for AGI just dropped, and it is a bad one.

Is the needle-in-a-haystack test still meaningful given the giant green heatmaps in modern LLM papers?
We create ONERULER 💍, a multilingual long-context benchmark that allows for nonexistent needles. Turns out NIAH isn't so easy after all!
Our analysis across 26 languages 🧵👇
We create ONERULER 💍, a multilingual long-context benchmark that allows for nonexistent needles. Turns out NIAH isn't so easy after all!
Our analysis across 26 languages 🧵👇

July 8, 2025 at 7:13 PM
Reposted by Marzena Karpinska

What should Machine Translation research look like in the age of multilingual LLMs?
Here’s one answer from researchers across NLP/MT, Translation Studies, and HCI.
"An Interdisciplinary Approach to Human-Centered Machine Translation"
arxiv.org/abs/2506.13468
Here’s one answer from researchers across NLP/MT, Translation Studies, and HCI.
"An Interdisciplinary Approach to Human-Centered Machine Translation"
arxiv.org/abs/2506.13468

An Interdisciplinary Approach to Human-Centered Machine Translation
Machine Translation (MT) tools are widely used today, often in contexts where professional translators are not present. Despite progress in MT technology, a gap persists between system development and...
arxiv.org
June 18, 2025 at 12:08 PM
What should Machine Translation research look like in the age of multilingual LLMs?
Here’s one answer from researchers across NLP/MT, Translation Studies, and HCI.
"An Interdisciplinary Approach to Human-Centered Machine Translation"
arxiv.org/abs/2506.13468
Here’s one answer from researchers across NLP/MT, Translation Studies, and HCI.
"An Interdisciplinary Approach to Human-Centered Machine Translation"
arxiv.org/abs/2506.13468
Reposted by Marzena Karpinska

Extremely interesting new task that gives a model a literary text, plus a critical essay about it — with one quotation masked. Can the model figure out which quotation from the original work would support these claims? Best-performing models exceed human readers. #MLSky arxiv.org/abs/2506.030...

Literary Evidence Retrieval via Long-Context Language Models
How well do modern long-context language models understand literary fiction? We explore this question via the task of literary evidence retrieval, repurposing the RELiC dataset of That et al. (2022) t...
arxiv.org
June 4, 2025 at 3:51 PM
Extremely interesting new task that gives a model a literary text, plus a critical essay about it — with one quotation masked. Can the model figure out which quotation from the original work would support these claims? Best-performing models exceed human readers. #MLSky arxiv.org/abs/2506.030...