



Ken Liu
@kzliu.bsky.social
8/
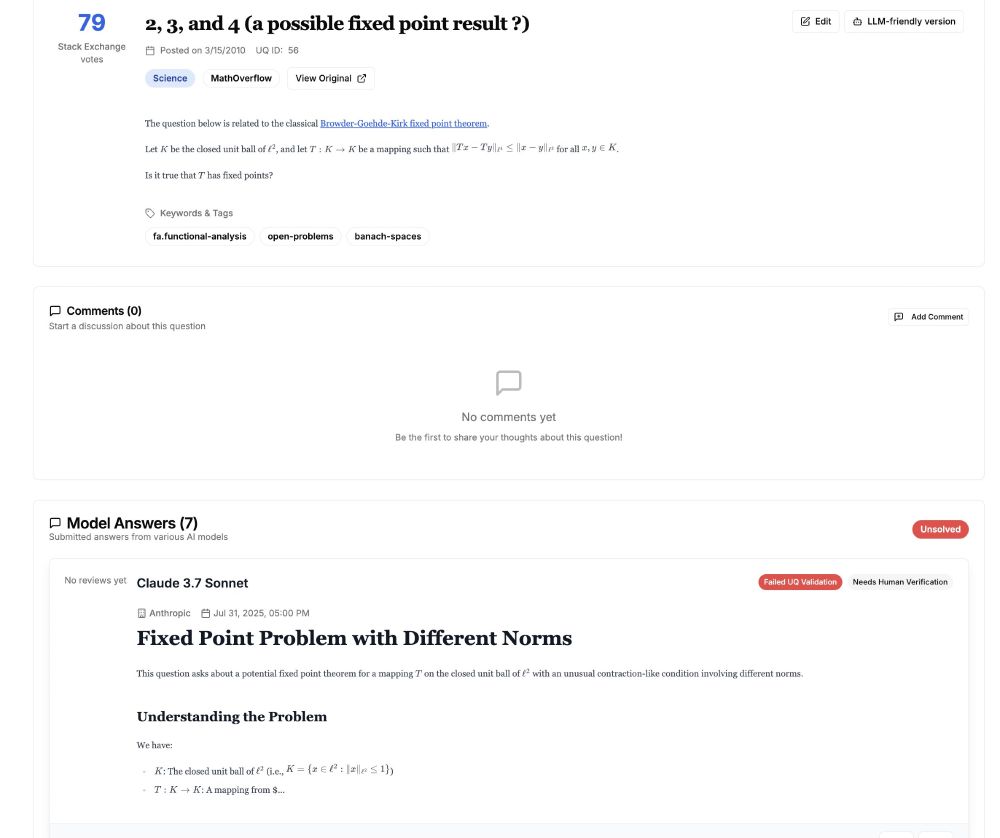
*UQ-Platform* (uq.stanford.edu) then continues where UQ-Validators leave off. It hosts the UQ-Dataset with AI answers and UQ-validation results, and experts can then rate AI answers, comment, and otherwise help resolve open questions -- just like Stack Exchange :). We need YOU to write reviews!
*UQ-Platform* (uq.stanford.edu) then continues where UQ-Validators leave off. It hosts the UQ-Dataset with AI answers and UQ-validation results, and experts can then rate AI answers, comment, and otherwise help resolve open questions -- just like Stack Exchange :). We need YOU to write reviews!
August 26, 2025 at 5:51 PM
8/
*UQ-Platform* (uq.stanford.edu) then continues where UQ-Validators leave off. It hosts the UQ-Dataset with AI answers and UQ-validation results, and experts can then rate AI answers, comment, and otherwise help resolve open questions -- just like Stack Exchange :). We need YOU to write reviews!
*UQ-Platform* (uq.stanford.edu) then continues where UQ-Validators leave off. It hosts the UQ-Dataset with AI answers and UQ-validation results, and experts can then rate AI answers, comment, and otherwise help resolve open questions -- just like Stack Exchange :). We need YOU to write reviews!
7/
*UQ-Validators* are simply LLMs (and compound LLM scaffolds) trying to pre-screen candidate answers to unsolved questions *without ground-truth answers*.
The key intuition is that it may be easier for LLMs to *validate* answers to hard questions (e.g. spotting mistakes) than to *generate* them.
*UQ-Validators* are simply LLMs (and compound LLM scaffolds) trying to pre-screen candidate answers to unsolved questions *without ground-truth answers*.
The key intuition is that it may be easier for LLMs to *validate* answers to hard questions (e.g. spotting mistakes) than to *generate* them.

August 26, 2025 at 5:51 PM
7/
*UQ-Validators* are simply LLMs (and compound LLM scaffolds) trying to pre-screen candidate answers to unsolved questions *without ground-truth answers*.
The key intuition is that it may be easier for LLMs to *validate* answers to hard questions (e.g. spotting mistakes) than to *generate* them.
*UQ-Validators* are simply LLMs (and compound LLM scaffolds) trying to pre-screen candidate answers to unsolved questions *without ground-truth answers*.
The key intuition is that it may be easier for LLMs to *validate* answers to hard questions (e.g. spotting mistakes) than to *generate* them.
6/
In contrast, we aim for UQ-Dataset to be difficult and realistic *by construction*: unsolved questions are often hard and naturally arise when humans seek answers, thus progress yields real-world value.
In exchange, we have to figure out how to evaluate models without answers...
In contrast, we aim for UQ-Dataset to be difficult and realistic *by construction*: unsolved questions are often hard and naturally arise when humans seek answers, thus progress yields real-world value.
In exchange, we have to figure out how to evaluate models without answers...

August 26, 2025 at 5:51 PM
6/
In contrast, we aim for UQ-Dataset to be difficult and realistic *by construction*: unsolved questions are often hard and naturally arise when humans seek answers, thus progress yields real-world value.
In exchange, we have to figure out how to evaluate models without answers...
In contrast, we aim for UQ-Dataset to be difficult and realistic *by construction*: unsolved questions are often hard and naturally arise when humans seek answers, thus progress yields real-world value.
In exchange, we have to figure out how to evaluate models without answers...
5/
UQ started with the observation that benchmark saturation has led to a *difficulty-realism tension*:
1. We contrive harder exams that begin to lose touch of real-world model usage
2. We build realistic evals (e.g. use human preferences) that became easy and/or hackable
UQ started with the observation that benchmark saturation has led to a *difficulty-realism tension*:
1. We contrive harder exams that begin to lose touch of real-world model usage
2. We build realistic evals (e.g. use human preferences) that became easy and/or hackable

August 26, 2025 at 5:51 PM
5/
UQ started with the observation that benchmark saturation has led to a *difficulty-realism tension*:
1. We contrive harder exams that begin to lose touch of real-world model usage
2. We build realistic evals (e.g. use human preferences) that became easy and/or hackable
UQ started with the observation that benchmark saturation has led to a *difficulty-realism tension*:
1. We contrive harder exams that begin to lose touch of real-world model usage
2. We build realistic evals (e.g. use human preferences) that became easy and/or hackable
4/
Here are some sample questions in the UQ-Dataset, which spans math, physics, CS theory, history, puzzles, scifi, and more; see uq.stanford.edu for full list!
Here are some sample questions in the UQ-Dataset, which spans math, physics, CS theory, history, puzzles, scifi, and more; see uq.stanford.edu for full list!


August 26, 2025 at 5:51 PM
4/
Here are some sample questions in the UQ-Dataset, which spans math, physics, CS theory, history, puzzles, scifi, and more; see uq.stanford.edu for full list!
Here are some sample questions in the UQ-Dataset, which spans math, physics, CS theory, history, puzzles, scifi, and more; see uq.stanford.edu for full list!
3/
Our main idea: rather than having static benchmarks scored once, can we evaluate LLMs *continuously and asynchronously* on real-world Qs with an actual need?
UQ-Dataset provides inputs → UQ-Validators screen outputs → UQ-Platform hosts live verification and model ranking.
Our main idea: rather than having static benchmarks scored once, can we evaluate LLMs *continuously and asynchronously* on real-world Qs with an actual need?
UQ-Dataset provides inputs → UQ-Validators screen outputs → UQ-Platform hosts live verification and model ranking.

August 26, 2025 at 5:51 PM
3/
Our main idea: rather than having static benchmarks scored once, can we evaluate LLMs *continuously and asynchronously* on real-world Qs with an actual need?
UQ-Dataset provides inputs → UQ-Validators screen outputs → UQ-Platform hosts live verification and model ranking.
Our main idea: rather than having static benchmarks scored once, can we evaluate LLMs *continuously and asynchronously* on real-world Qs with an actual need?
UQ-Dataset provides inputs → UQ-Validators screen outputs → UQ-Platform hosts live verification and model ranking.
New paper! We explore a radical paradigm for AI evals: assessing LLMs on *unsolved* questions.
Instead of artificially difficult exams where progress ≠ value, we assess LLMs on organic, unsolved problems via reference-free LLM validation & community verification. LLMs solved ~10/500 so far:
Instead of artificially difficult exams where progress ≠ value, we assess LLMs on organic, unsolved problems via reference-free LLM validation & community verification. LLMs solved ~10/500 so far:

August 26, 2025 at 5:51 PM
New paper! We explore a radical paradigm for AI evals: assessing LLMs on *unsolved* questions.
Instead of artificially difficult exams where progress ≠ value, we assess LLMs on organic, unsolved problems via reference-free LLM validation & community verification. LLMs solved ~10/500 so far:
Instead of artificially difficult exams where progress ≠ value, we assess LLMs on organic, unsolved problems via reference-free LLM validation & community verification. LLMs solved ~10/500 so far: