



Keyon Vafa
@keyonv.bsky.social
Postdoctoral fellow at Harvard Data Science Initiative | Former computer science PhD at Columbia University | ML + NLP + social sciences
https://keyonvafa.com
https://keyonvafa.com
Paper: arxiv.org/abs/2507.06952
Co-authors: Peter Chang, Ashesh Rambachan (@asheshrambachan.bsky.social), Sendhil Mullainathan (@sendhil.bsky.social)
Co-authors: Peter Chang, Ashesh Rambachan (@asheshrambachan.bsky.social), Sendhil Mullainathan (@sendhil.bsky.social)

What Has a Foundation Model Found? Using Inductive Bias to Probe for World Models
Foundation models are premised on the idea that sequence prediction can uncover deeper domain understanding, much like how Kepler's predictions of planetary motion later led to the discovery of Newton...
arxiv.org
July 14, 2025 at 1:50 PM
Paper: arxiv.org/abs/2507.06952
Co-authors: Peter Chang, Ashesh Rambachan (@asheshrambachan.bsky.social), Sendhil Mullainathan (@sendhil.bsky.social)
Co-authors: Peter Chang, Ashesh Rambachan (@asheshrambachan.bsky.social), Sendhil Mullainathan (@sendhil.bsky.social)
This is one way to evaluate world models. But there are many other interesting approaches!
Plug: If you're interested in more, check out the Workshop on Assessing World Models I'm co-organizing Friday at ICML www.worldmodelworkshop.org
Plug: If you're interested in more, check out the Workshop on Assessing World Models I'm co-organizing Friday at ICML www.worldmodelworkshop.org

ICML Workshop on Assessing World Models
Date: Friday, July 18 2025
Location: Ballroom B at ICML 2025 in Vancouver, Canada
www.worldmodelworkshop.org
July 14, 2025 at 1:50 PM
This is one way to evaluate world models. But there are many other interesting approaches!
Plug: If you're interested in more, check out the Workshop on Assessing World Models I'm co-organizing Friday at ICML www.worldmodelworkshop.org
Plug: If you're interested in more, check out the Workshop on Assessing World Models I'm co-organizing Friday at ICML www.worldmodelworkshop.org
Last year we proposed different tests that studied single tasks.
We now think that studying behavior on new tasks better captures what we want from foundation models: tools for new problems.
It's what separates Newton's laws from Kepler's predictions.
arxiv.org/abs/2406.03689
We now think that studying behavior on new tasks better captures what we want from foundation models: tools for new problems.
It's what separates Newton's laws from Kepler's predictions.
arxiv.org/abs/2406.03689
Evaluating the World Model Implicit in a Generative Model
Recent work suggests that large language models may implicitly learn world models. How should we assess this possibility? We formalize this question for the case where the underlying reality is govern...
arxiv.org
July 14, 2025 at 1:50 PM
Last year we proposed different tests that studied single tasks.
We now think that studying behavior on new tasks better captures what we want from foundation models: tools for new problems.
It's what separates Newton's laws from Kepler's predictions.
arxiv.org/abs/2406.03689
We now think that studying behavior on new tasks better captures what we want from foundation models: tools for new problems.
It's what separates Newton's laws from Kepler's predictions.
arxiv.org/abs/2406.03689
Summary:
1. We propose inductive bias probes: a model's inductive bias reveals its world model
2. Foundation models can have great predictions with poor world models
3. One reason world models are poor: models group together distinct states that have similar allowed next-tokens
1. We propose inductive bias probes: a model's inductive bias reveals its world model
2. Foundation models can have great predictions with poor world models
3. One reason world models are poor: models group together distinct states that have similar allowed next-tokens
July 14, 2025 at 1:50 PM
Summary:
1. We propose inductive bias probes: a model's inductive bias reveals its world model
2. Foundation models can have great predictions with poor world models
3. One reason world models are poor: models group together distinct states that have similar allowed next-tokens
1. We propose inductive bias probes: a model's inductive bias reveals its world model
2. Foundation models can have great predictions with poor world models
3. One reason world models are poor: models group together distinct states that have similar allowed next-tokens
Inductive bias probes can test this hypothesis more generally.
Models are much likelier to conflate two separate states when they share the same legal next-tokens.
Models are much likelier to conflate two separate states when they share the same legal next-tokens.

July 14, 2025 at 1:50 PM
Inductive bias probes can test this hypothesis more generally.
Models are much likelier to conflate two separate states when they share the same legal next-tokens.
Models are much likelier to conflate two separate states when they share the same legal next-tokens.
We fine-tune an Othello next-token prediction model to reconstruct boards.
Even when the model reconstructs boards incorrectly, the reconstructed boards often get the legal next moves right.
Models seem to construct "enough of" the board to calculate single next moves.
Even when the model reconstructs boards incorrectly, the reconstructed boards often get the legal next moves right.
Models seem to construct "enough of" the board to calculate single next moves.

July 14, 2025 at 1:50 PM
We fine-tune an Othello next-token prediction model to reconstruct boards.
Even when the model reconstructs boards incorrectly, the reconstructed boards often get the legal next moves right.
Models seem to construct "enough of" the board to calculate single next moves.
Even when the model reconstructs boards incorrectly, the reconstructed boards often get the legal next moves right.
Models seem to construct "enough of" the board to calculate single next moves.
If a foundation model's inductive bias isn't toward a given world model, what is it toward?
One hypothesis: models confuse sequences that belong to different states but have the same legal *next* tokens.
Example: Two different Othello boards can have the same legal next moves.
One hypothesis: models confuse sequences that belong to different states but have the same legal *next* tokens.
Example: Two different Othello boards can have the same legal next moves.
July 14, 2025 at 1:50 PM
If a foundation model's inductive bias isn't toward a given world model, what is it toward?
One hypothesis: models confuse sequences that belong to different states but have the same legal *next* tokens.
Example: Two different Othello boards can have the same legal next moves.
One hypothesis: models confuse sequences that belong to different states but have the same legal *next* tokens.
Example: Two different Othello boards can have the same legal next moves.
We also apply these probes to lattice problems (think gridworld).
Inductive biases are great when the number of states is small. But they deteriorate quickly.
Recurrent and state-space models like Mamba consistently have better inductive biases than transformers.
Inductive biases are great when the number of states is small. But they deteriorate quickly.
Recurrent and state-space models like Mamba consistently have better inductive biases than transformers.

July 14, 2025 at 1:50 PM
We also apply these probes to lattice problems (think gridworld).
Inductive biases are great when the number of states is small. But they deteriorate quickly.
Recurrent and state-space models like Mamba consistently have better inductive biases than transformers.
Inductive biases are great when the number of states is small. But they deteriorate quickly.
Recurrent and state-space models like Mamba consistently have better inductive biases than transformers.
Would more general models like LLMs do better?
We tried providing o3, Claude Sonnet 4, and Gemini 2.5 Pro with a small number of force magnitudes in-context w/o saying what they are.
These LLMs are explicitly trained on Newton's laws. But they can't get the rest of the forces.
We tried providing o3, Claude Sonnet 4, and Gemini 2.5 Pro with a small number of force magnitudes in-context w/o saying what they are.
These LLMs are explicitly trained on Newton's laws. But they can't get the rest of the forces.


July 14, 2025 at 1:50 PM
Would more general models like LLMs do better?
We tried providing o3, Claude Sonnet 4, and Gemini 2.5 Pro with a small number of force magnitudes in-context w/o saying what they are.
These LLMs are explicitly trained on Newton's laws. But they can't get the rest of the forces.
We tried providing o3, Claude Sonnet 4, and Gemini 2.5 Pro with a small number of force magnitudes in-context w/o saying what they are.
These LLMs are explicitly trained on Newton's laws. But they can't get the rest of the forces.
We then fine-tuned the model on a larger scale, to predict forces across 10K solar systems.
We used a symbolic regression to compare the recovered force law to Newton's law.
It not only recovered a nonsensical law—it recovered different laws for different galaxies.
We used a symbolic regression to compare the recovered force law to Newton's law.
It not only recovered a nonsensical law—it recovered different laws for different galaxies.

July 14, 2025 at 1:50 PM
We then fine-tuned the model on a larger scale, to predict forces across 10K solar systems.
We used a symbolic regression to compare the recovered force law to Newton's law.
It not only recovered a nonsensical law—it recovered different laws for different galaxies.
We used a symbolic regression to compare the recovered force law to Newton's law.
It not only recovered a nonsensical law—it recovered different laws for different galaxies.
To demonstrate, we fine-tuned the model to predict force vectors on a small dataset of planets in our solar system.
A model that understands Newtonian mechanics should get these. But the transformer struggles.
A model that understands Newtonian mechanics should get these. But the transformer struggles.
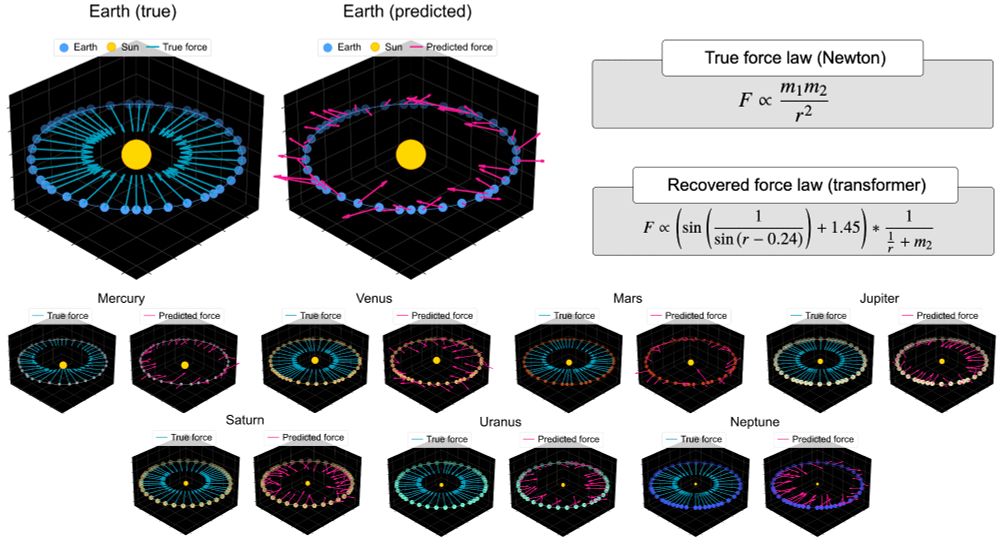
July 14, 2025 at 1:50 PM
To demonstrate, we fine-tuned the model to predict force vectors on a small dataset of planets in our solar system.
A model that understands Newtonian mechanics should get these. But the transformer struggles.
A model that understands Newtonian mechanics should get these. But the transformer struggles.
But has the model discovered Newton's laws?
When we fine-tune it to new tasks, its inductive bias isn't toward Newtonian states.
When it extrapolates, it makes similar predictions for orbits with very different states, and different predictions for orbits with similar states.
When we fine-tune it to new tasks, its inductive bias isn't toward Newtonian states.
When it extrapolates, it makes similar predictions for orbits with very different states, and different predictions for orbits with similar states.

July 14, 2025 at 1:50 PM
But has the model discovered Newton's laws?
When we fine-tune it to new tasks, its inductive bias isn't toward Newtonian states.
When it extrapolates, it makes similar predictions for orbits with very different states, and different predictions for orbits with similar states.
When we fine-tune it to new tasks, its inductive bias isn't toward Newtonian states.
When it extrapolates, it makes similar predictions for orbits with very different states, and different predictions for orbits with similar states.
We apply these probes to orbital, lattice, and Othello problems.
Starting with orbits: we encode solar systems as sequences and train a transformer on 10M solar systems (20B tokens)
The model makes accurate predictions many timesteps ahead. Predictions for our solar system:
Starting with orbits: we encode solar systems as sequences and train a transformer on 10M solar systems (20B tokens)
The model makes accurate predictions many timesteps ahead. Predictions for our solar system:
July 14, 2025 at 1:50 PM
We apply these probes to orbital, lattice, and Othello problems.
Starting with orbits: we encode solar systems as sequences and train a transformer on 10M solar systems (20B tokens)
The model makes accurate predictions many timesteps ahead. Predictions for our solar system:
Starting with orbits: we encode solar systems as sequences and train a transformer on 10M solar systems (20B tokens)
The model makes accurate predictions many timesteps ahead. Predictions for our solar system:
We propose a method to measure these inductive biases. We call it an inductive bias probe.
Two steps:
1. Fit a foundation model to many new, very small synthetic datasets
2. Analyze patterns in the functions it learns to find the model's inductive bias
Two steps:
1. Fit a foundation model to many new, very small synthetic datasets
2. Analyze patterns in the functions it learns to find the model's inductive bias

July 14, 2025 at 1:50 PM
We propose a method to measure these inductive biases. We call it an inductive bias probe.
Two steps:
1. Fit a foundation model to many new, very small synthetic datasets
2. Analyze patterns in the functions it learns to find the model's inductive bias
Two steps:
1. Fit a foundation model to many new, very small synthetic datasets
2. Analyze patterns in the functions it learns to find the model's inductive bias
Newton's laws are a kind of foundation model. They provide a place to start when working on new problems.
A good foundation model should do the same.
The No Free Lunch Theorem motivates a test: Every foundation model has an inductive bias. This bias reveals its world model.
A good foundation model should do the same.
The No Free Lunch Theorem motivates a test: Every foundation model has an inductive bias. This bias reveals its world model.
July 14, 2025 at 1:50 PM
Newton's laws are a kind of foundation model. They provide a place to start when working on new problems.
A good foundation model should do the same.
The No Free Lunch Theorem motivates a test: Every foundation model has an inductive bias. This bias reveals its world model.
A good foundation model should do the same.
The No Free Lunch Theorem motivates a test: Every foundation model has an inductive bias. This bias reveals its world model.
If you only care about orbits, Newton didn't add much. His laws give the same predictions.
But Newton's laws went beyond orbits: the same laws explain pendulums, cannonballs, and rockets.
This motivates our framework: Predictions apply to one task. World models generalize to many
But Newton's laws went beyond orbits: the same laws explain pendulums, cannonballs, and rockets.
This motivates our framework: Predictions apply to one task. World models generalize to many
July 14, 2025 at 1:50 PM
If you only care about orbits, Newton didn't add much. His laws give the same predictions.
But Newton's laws went beyond orbits: the same laws explain pendulums, cannonballs, and rockets.
This motivates our framework: Predictions apply to one task. World models generalize to many
But Newton's laws went beyond orbits: the same laws explain pendulums, cannonballs, and rockets.
This motivates our framework: Predictions apply to one task. World models generalize to many
Perhaps the most influential world model had its start as a predictive model.
Before we had Newton's laws of gravity, we had Kepler's predictions of planetary orbits.
Kepler's predictions led to Newton's laws. So what did Newton add?
Before we had Newton's laws of gravity, we had Kepler's predictions of planetary orbits.
Kepler's predictions led to Newton's laws. So what did Newton add?

July 14, 2025 at 1:50 PM
Perhaps the most influential world model had its start as a predictive model.
Before we had Newton's laws of gravity, we had Kepler's predictions of planetary orbits.
Kepler's predictions led to Newton's laws. So what did Newton add?
Before we had Newton's laws of gravity, we had Kepler's predictions of planetary orbits.
Kepler's predictions led to Newton's laws. So what did Newton add?
Our paper aims to answer two questions:
1. What's the difference between prediction and world models?
2. Are there straightforward metrics that can test this distinction?
Our paper is about AI. But it's helpful to go back 400 years to answer these questions.
1. What's the difference between prediction and world models?
2. Are there straightforward metrics that can test this distinction?
Our paper is about AI. But it's helpful to go back 400 years to answer these questions.

July 14, 2025 at 1:50 PM
Our paper aims to answer two questions:
1. What's the difference between prediction and world models?
2. Are there straightforward metrics that can test this distinction?
Our paper is about AI. But it's helpful to go back 400 years to answer these questions.
1. What's the difference between prediction and world models?
2. Are there straightforward metrics that can test this distinction?
Our paper is about AI. But it's helpful to go back 400 years to answer these questions.