




Kartik Chandra
@kartikchandra.bsky.social
This is *so* cool!
Just for fun, I re-implemented the rational belief updating computational model for Experiments 1 + 2 in memo. github.com/kach/memo/bl...
Here's the main model for the "revision" condition, and its predictions with some reasonable parameter settings (should look like fig 2B).
Just for fun, I re-implemented the rational belief updating computational model for Experiments 1 + 2 in memo. github.com/kach/memo/bl...
Here's the main model for the "revision" condition, and its predictions with some reasonable parameter settings (should look like fig 2B).


October 31, 2025 at 12:23 PM
This is *so* cool!
Just for fun, I re-implemented the rational belief updating computational model for Experiments 1 + 2 in memo. github.com/kach/memo/bl...
Here's the main model for the "revision" condition, and its predictions with some reasonable parameter settings (should look like fig 2B).
Just for fun, I re-implemented the rational belief updating computational model for Experiments 1 + 2 in memo. github.com/kach/memo/bl...
Here's the main model for the "revision" condition, and its predictions with some reasonable parameter settings (should look like fig 2B).
Congratulations, Charley! I'm so excited to see how your lab will grow and evolve over the coming years. :)
October 1, 2025 at 11:21 PM
Congratulations, Charley! I'm so excited to see how your lab will grow and evolve over the coming years. :)
The full, uncropped picture explains what is going on here: the sun is reflected by two buildings with different window tints. The reflection from the blue building casts the yellow shadow, and vice versa. (Studying graphics reminds me just how overwhelmingly beautiful the everyday visual world is…)

August 13, 2025 at 5:36 AM
The full, uncropped picture explains what is going on here: the sun is reflected by two buildings with different window tints. The reflection from the blue building casts the yellow shadow, and vice versa. (Studying graphics reminds me just how overwhelmingly beautiful the everyday visual world is…)
We've planned a fun, interactive session with something for everything: whether you're a curious beginner looking to get started, or a seasoned expert looking to push the frontiers of what's possible. There will be games, live-coding, flash talks, and more. Max, Dae and I can't wait to see you! :)
July 18, 2025 at 1:56 PM
We've planned a fun, interactive session with something for everything: whether you're a curious beginner looking to get started, or a seasoned expert looking to push the frontiers of what's possible. There will be games, live-coding, flash talks, and more. Max, Dae and I can't wait to see you! :)
If you're curious what memo is: it's a programming language specialized for social cognition and theory-of-mind. It lets you write models concisely, using special syntax like "Kartik knows" and "Max chooses," and it compiles to fast GPU code. Lots of CogSci '25 papers use memo! github.com/kach/memo
July 18, 2025 at 1:56 PM
If you're curious what memo is: it's a programming language specialized for social cognition and theory-of-mind. It lets you write models concisely, using special syntax like "Kartik knows" and "Max chooses," and it compiles to fast GPU code. Lots of CogSci '25 papers use memo! github.com/kach/memo
(The *real* puzzle: how come our visual systems make such incredible inferences from shadows, and yet we barely notice such glaring inconsistencies unless we go looking for them? I just read Casati and Cavanagh's book "The Visual World of Shadows," which has made me fall in love with this question…)
June 5, 2025 at 2:27 PM
(The *real* puzzle: how come our visual systems make such incredible inferences from shadows, and yet we barely notice such glaring inconsistencies unless we go looking for them? I just read Casati and Cavanagh's book "The Visual World of Shadows," which has made me fall in love with this question…)


Hi there! Thanks for the kind words.
I think everything should be linked from my homepage here: cs.stanford.edu/~kach/
And you can still subscribe to the RSS feed for new posts.
I think everything should be linked from my homepage here: cs.stanford.edu/~kach/
And you can still subscribe to the RSS feed for new posts.
February 3, 2025 at 4:43 PM
Hi there! Thanks for the kind words.
I think everything should be linked from my homepage here: cs.stanford.edu/~kach/
And you can still subscribe to the RSS feed for new posts.
I think everything should be linked from my homepage here: cs.stanford.edu/~kach/
And you can still subscribe to the RSS feed for new posts.
I thought I would share these incantations in case anyone else is having the same realization today, and is up for an adventure. :)
See also: pandoc.org/MANUAL.html
See also: pandoc.org/MANUAL.html
January 31, 2025 at 1:56 PM
I thought I would share these incantations in case anyone else is having the same realization today, and is up for an adventure. :)
See also: pandoc.org/MANUAL.html
See also: pandoc.org/MANUAL.html
(1) First, you can convert your LaTeX to plain text like this:
pandoc --wrap=none main.tex -o main.txt
(2) But this does not automatically format references. For that, you can run this additional command:
pandoc --wrap=none --bibliography=refs.bib --citeproc main.txt | pandoc -t plain --wrap=none
pandoc --wrap=none main.tex -o main.txt
(2) But this does not automatically format references. For that, you can run this additional command:
pandoc --wrap=none --bibliography=refs.bib --citeproc main.txt | pandoc -t plain --wrap=none
January 31, 2025 at 1:55 PM
(1) First, you can convert your LaTeX to plain text like this:
pandoc --wrap=none main.tex -o main.txt
(2) But this does not automatically format references. For that, you can run this additional command:
pandoc --wrap=none --bibliography=refs.bib --citeproc main.txt | pandoc -t plain --wrap=none
pandoc --wrap=none main.tex -o main.txt
(2) But this does not automatically format references. For that, you can run this additional command:
pandoc --wrap=none --bibliography=refs.bib --citeproc main.txt | pandoc -t plain --wrap=none
Yes! As one example of the impact SGI sponsorships have, I got the opportunity to attend SGI 2024 in Boston thanks to a generous industry sponsorship. I really hope other students can have that same opportunity in future years!
December 18, 2024 at 5:47 PM
Yes! As one example of the impact SGI sponsorships have, I got the opportunity to attend SGI 2024 in Boston thanks to a generous industry sponsorship. I really hope other students can have that same opportunity in future years!
(I don't think it was just that we students were hungry and/or easy to bribe. I think the professor's gesture made us feel like the class was a community of friends who were there for more than simply giving/getting grades. After that, showing up every day felt like the obvious natural thing to do!)
December 4, 2024 at 11:39 AM
(I don't think it was just that we students were hungry and/or easy to bribe. I think the professor's gesture made us feel like the class was a community of friends who were there for more than simply giving/getting grades. After that, showing up every day felt like the obvious natural thing to do!)
Possibly-helpful anecdote: my undergrad complexity theory professor once went shopping for a new carpet at the mall. Next to the carpet store was a bakery, so he spontaneously decided to buy cupcakes for everyone in class the next day. From then on, he got near-perfect attendance for every lecture…
December 4, 2024 at 11:33 AM
Possibly-helpful anecdote: my undergrad complexity theory professor once went shopping for a new carpet at the mall. Next to the carpet store was a bakery, so he spontaneously decided to buy cupcakes for everyone in class the next day. From then on, he got near-perfect attendance for every lecture…
There's much more to say about this—especially about why we think these ideas are important to graphics. For more, see our paper arxiv.org/abs/2409.13507 or Matt's upcoming talk at SIGGRAPH Asia.
In the meantime, enjoy a video where every sound effect is a vocal imitation produced by our method! :)
In the meantime, enjoy a video where every sound effect is a vocal imitation produced by our method! :)
November 30, 2024 at 8:29 PM
There's much more to say about this—especially about why we think these ideas are important to graphics. For more, see our paper arxiv.org/abs/2409.13507 or Matt's upcoming talk at SIGGRAPH Asia.
In the meantime, enjoy a video where every sound effect is a vocal imitation produced by our method! :)
In the meantime, enjoy a video where every sound effect is a vocal imitation produced by our method! :)
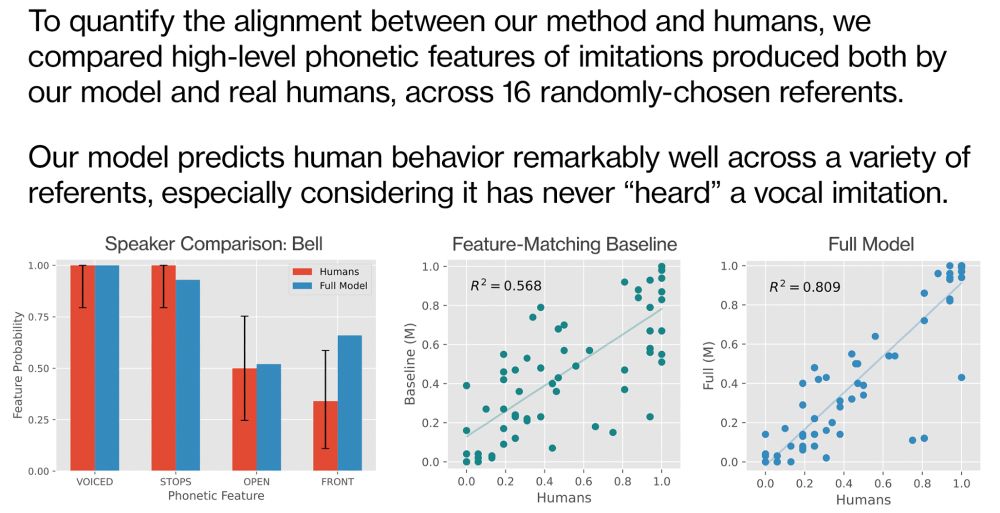
When compared to actual vocal imitations produced by actual humans, our model predicts people's behavior quite well…
But we never "trained" our model on any dataset of human vocal imitations! Human-like imitations emerged simply from encoding basic principles of human communication into our model.
But we never "trained" our model on any dataset of human vocal imitations! Human-like imitations emerged simply from encoding basic principles of human communication into our model.
November 30, 2024 at 8:29 PM
When compared to actual vocal imitations produced by actual humans, our model predicts people's behavior quite well…
But we never "trained" our model on any dataset of human vocal imitations! Human-like imitations emerged simply from encoding basic principles of human communication into our model.
But we never "trained" our model on any dataset of human vocal imitations! Human-like imitations emerged simply from encoding basic principles of human communication into our model.