



Kabir Ahuja
@kabirahuja2431.bsky.social
PhD student @uwnlp.bsky.social
I had always wanted to work on something that can combine my love for fiction and NLP research, making this project a lot of fun. Huge thanks to the wonderful @melaniesclar.bsky.social and @tsvetshop.bsky.social!
We welcome any feedback and questions -- don't hesitate to reach out!
16/16
We welcome any feedback and questions -- don't hesitate to reach out!
16/16

April 22, 2025 at 6:50 PM
I had always wanted to work on something that can combine my love for fiction and NLP research, making this project a lot of fun. Huge thanks to the wonderful @melaniesclar.bsky.social and @tsvetshop.bsky.social!
We welcome any feedback and questions -- don't hesitate to reach out!
16/16
We welcome any feedback and questions -- don't hesitate to reach out!
16/16
But how can story summaries have plot holes? Upon close inspection we find LLMs often omit crucial details in the summary that make subsequent events illogical or inconsistent. This highlights weaknesses in summarization—a task many consider "solved" with current LLMs.
13/n
13/n

April 22, 2025 at 6:50 PM
But how can story summaries have plot holes? Upon close inspection we find LLMs often omit crucial details in the summary that make subsequent events illogical or inconsistent. This highlights weaknesses in summarization—a task many consider "solved" with current LLMs.
13/n
13/n
Our results show LLM-generated content contains significantly more plot holes than human-authored stories: 50%+ higher detection rates for summaries and 100%+ increase for contemporary adaptations of classics.
12/n
12/n

April 22, 2025 at 6:50 PM
Our results show LLM-generated content contains significantly more plot holes than human-authored stories: 50%+ higher detection rates for summaries and 100%+ increase for contemporary adaptations of classics.
12/n
12/n
What mistakes do models make while assessing plot holes? Our analysis shows they:
- Misinterpret character motivations
- Incorrectly track entity states
- Miss genre conventions (especially in fantasy)
- Misinterpret story rules Examples 👇🏻
10/n
- Misinterpret character motivations
- Incorrectly track entity states
- Miss genre conventions (especially in fantasy)
- Misinterpret story rules Examples 👇🏻
10/n




April 22, 2025 at 6:50 PM
What mistakes do models make while assessing plot holes? Our analysis shows they:
- Misinterpret character motivations
- Incorrectly track entity states
- Miss genre conventions (especially in fantasy)
- Misinterpret story rules Examples 👇🏻
10/n
- Misinterpret character motivations
- Incorrectly track entity states
- Miss genre conventions (especially in fantasy)
- Misinterpret story rules Examples 👇🏻
10/n
Does extra test time compute help? Mostly no. Increasing reasoning effort for o1 and o3-mini shows no improvements. Claude-3.7-Sonnet's extended thinking helps, but still underperforms models using <50% of the test time compute.
9/n
9/n


April 22, 2025 at 6:50 PM
Does extra test time compute help? Mostly no. Increasing reasoning effort for o1 and o3-mini shows no improvements. Claude-3.7-Sonnet's extended thinking helps, but still underperforms models using <50% of the test time compute.
9/n
9/n
Yet on FlawedFictionsLong (our benchmark with longer stories), even the best models barely outperform trivial baselines. And these stories are still under 4000 words—far shorter than novels or screenplays where plot holes typically occur.
8/n
8/n

April 22, 2025 at 6:50 PM
Yet on FlawedFictionsLong (our benchmark with longer stories), even the best models barely outperform trivial baselines. And these stories are still under 4000 words—far shorter than novels or screenplays where plot holes typically occur.
8/n
8/n
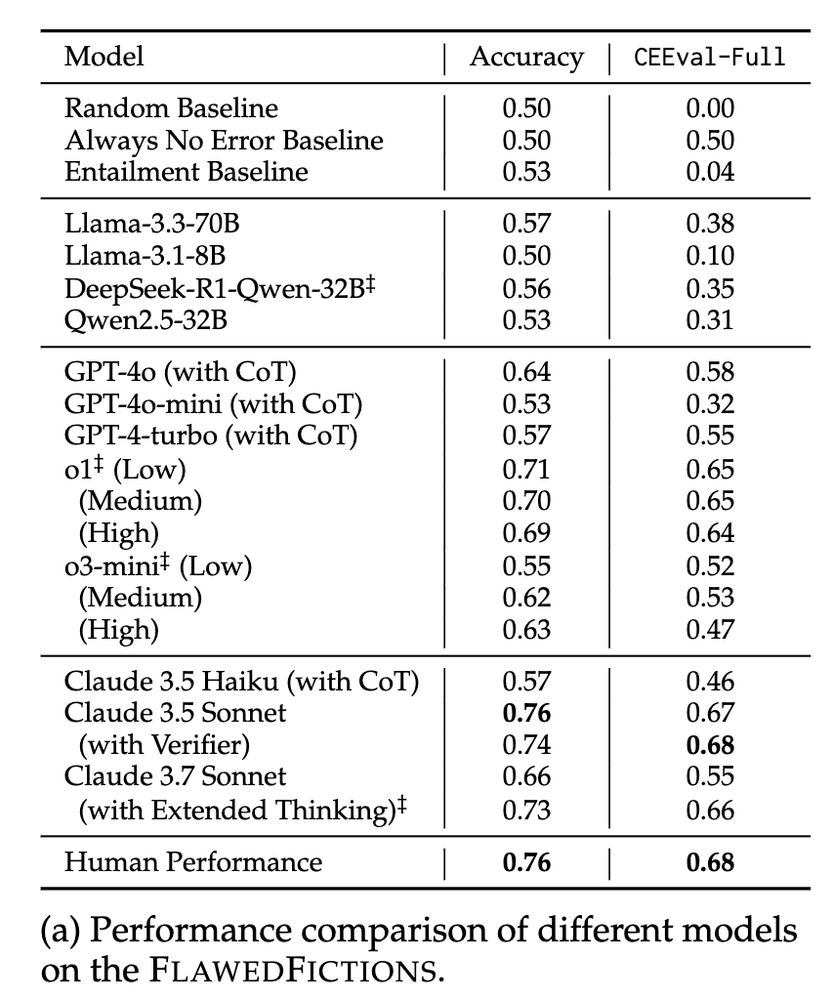
We find that most open-weight models and proprietary LLMs like GPT-4o-mini, GPT-4o, and Claude-Haiku struggle on the task, often only slightly improving over trivial baselines. Advanced models like Claude-3.5-Sonnet and o1 fare better, approaching human performance.
7/n
7/n
April 22, 2025 at 6:50 PM
We find that most open-weight models and proprietary LLMs like GPT-4o-mini, GPT-4o, and Claude-Haiku struggle on the task, often only slightly improving over trivial baselines. Advanced models like Claude-3.5-Sonnet and o1 fare better, approaching human performance.
7/n
7/n
Using FlawedFictionsMaker + human verification, we created FlawedFictions - a benchmark for plot hole detection that tests: a) identifying if a story contains a plot hole, and b) localizing both the error and the contradicted fact in the text
5/n
5/n

April 22, 2025 at 6:50 PM
Using FlawedFictionsMaker + human verification, we created FlawedFictions - a benchmark for plot hole detection that tests: a) identifying if a story contains a plot hole, and b) localizing both the error and the contradicted fact in the text
5/n
5/n
We introduce FlawedFictionsMaker an algorithm to controllably generate plot holes in stories by extracting facts from a story's first act and contradicting them later in the story.
E.g. If Watson has a left arm injury, we edit it to become a knee injury in later mentions.
4/n
E.g. If Watson has a left arm injury, we edit it to become a knee injury in later mentions.
4/n

April 22, 2025 at 6:50 PM
We introduce FlawedFictionsMaker an algorithm to controllably generate plot holes in stories by extracting facts from a story's first act and contradicting them later in the story.
E.g. If Watson has a left arm injury, we edit it to become a knee injury in later mentions.
4/n
E.g. If Watson has a left arm injury, we edit it to become a knee injury in later mentions.
4/n
📢 New Paper!
Tired 😴 of reasoning benchmarks full of math & code? In our work we consider the problem of reasoning for plot holes in stories -- inconsistencies in a storyline that break the internal logic or rules of a story’s world 🌎
W @melaniesclar.bsky.social, and @tsvetshop.bsky.social
1/n
Tired 😴 of reasoning benchmarks full of math & code? In our work we consider the problem of reasoning for plot holes in stories -- inconsistencies in a storyline that break the internal logic or rules of a story’s world 🌎
W @melaniesclar.bsky.social, and @tsvetshop.bsky.social
1/n

April 22, 2025 at 6:50 PM
📢 New Paper!
Tired 😴 of reasoning benchmarks full of math & code? In our work we consider the problem of reasoning for plot holes in stories -- inconsistencies in a storyline that break the internal logic or rules of a story’s world 🌎
W @melaniesclar.bsky.social, and @tsvetshop.bsky.social
1/n
Tired 😴 of reasoning benchmarks full of math & code? In our work we consider the problem of reasoning for plot holes in stories -- inconsistencies in a storyline that break the internal logic or rules of a story’s world 🌎
W @melaniesclar.bsky.social, and @tsvetshop.bsky.social
1/n