



Juliette Bertrand
@juliettebertrand.bsky.social
Reposted by Juliette Bertrand

Scaling 4D Representations
Self-supervised learning from video does scale! In our latest work, we scaled masked auto-encoding models to 22B params, boosting performance on pose estimation, tracking & more.
Paper: arxiv.org/abs/2412.15212
Code & models: github.com/google-deepmind/representations4d
Self-supervised learning from video does scale! In our latest work, we scaled masked auto-encoding models to 22B params, boosting performance on pose estimation, tracking & more.
Paper: arxiv.org/abs/2412.15212
Code & models: github.com/google-deepmind/representations4d

July 10, 2025 at 11:52 AM
Scaling 4D Representations
Self-supervised learning from video does scale! In our latest work, we scaled masked auto-encoding models to 22B params, boosting performance on pose estimation, tracking & more.
Paper: arxiv.org/abs/2412.15212
Code & models: github.com/google-deepmind/representations4d
Self-supervised learning from video does scale! In our latest work, we scaled masked auto-encoding models to 22B params, boosting performance on pose estimation, tracking & more.
Paper: arxiv.org/abs/2412.15212
Code & models: github.com/google-deepmind/representations4d
Reposted by Juliette Bertrand

We have an open internship position on socially aware navigation, human aware world models etc.
At @naverlabseurope.bsky.social in Grenoble (Meylan), France.
careers.werecruit.io/en/naver-lab...
At @naverlabseurope.bsky.social in Grenoble (Meylan), France.
careers.werecruit.io/en/naver-lab...

May 21, 2025 at 12:51 PM
We have an open internship position on socially aware navigation, human aware world models etc.
At @naverlabseurope.bsky.social in Grenoble (Meylan), France.
careers.werecruit.io/en/naver-lab...
At @naverlabseurope.bsky.social in Grenoble (Meylan), France.
careers.werecruit.io/en/naver-lab...
Reposted by Juliette Bertrand

The PAISS summer school is back with an incredible line of speakers (and more to come). Spread the word !

May 5, 2025 at 4:34 PM
The PAISS summer school is back with an incredible line of speakers (and more to come). Spread the word !
Reposted by Juliette Bertrand

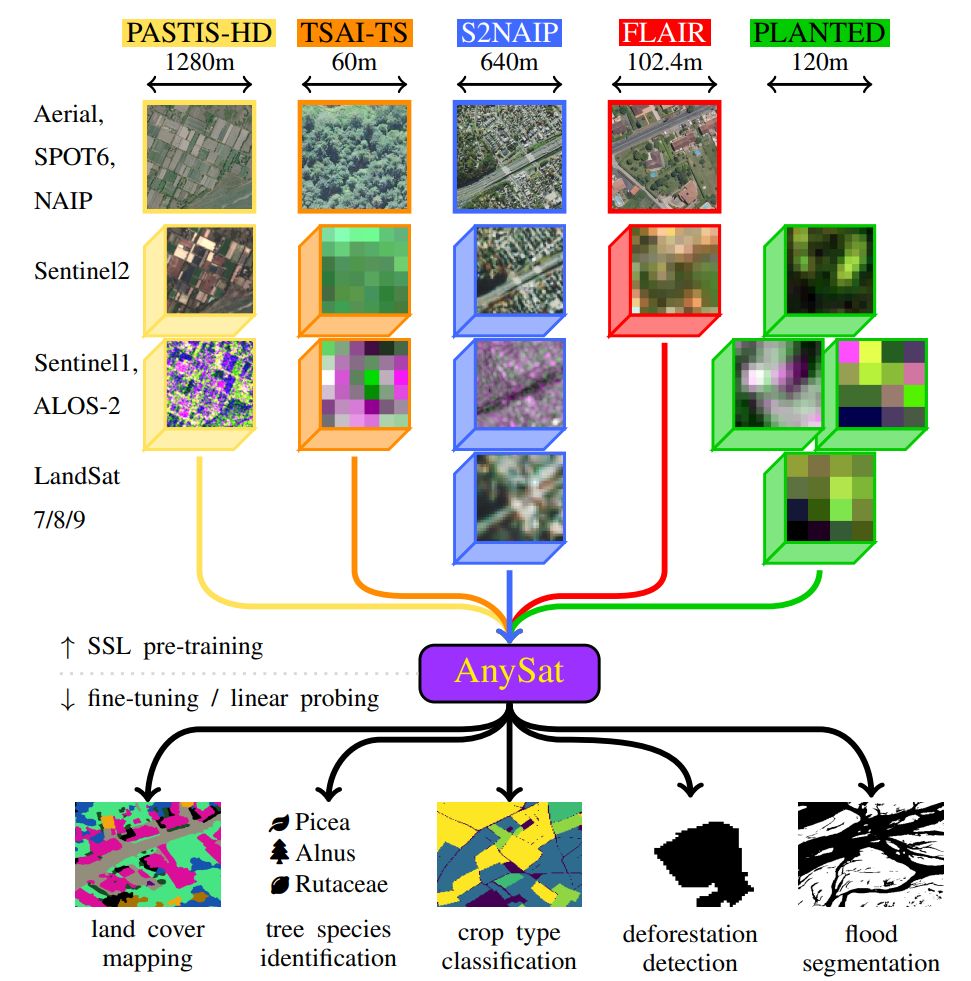
AnySat has been accepted as a ✨ highlight at #CVPR2025! See you in Nashville 🎉
We’ll also be presenting this work at:
📍 @egu.eu on 02/04 in Vienna
📍 @esa.int / NASA Workshop on Foundation Models on 05/04 in Rome
We’ll also be presenting this work at:
📍 @egu.eu on 02/04 in Vienna
📍 @esa.int / NASA Workshop on Foundation Models on 05/04 in Rome

#CVPR2025 Sat June 14 (PM) ✨ Highlight
🛰️ AnySat: One Earth Observation Model for Many Resolutions, Scales, and Modalities
@gastruc.bsky.social @nicaogr.bsky.social @loicland.bsky.social
📄 pdf: arxiv.org/abs/2412.14123
🌐 webpage: gastruc.github.io/anysat
🛰️ AnySat: One Earth Observation Model for Many Resolutions, Scales, and Modalities
@gastruc.bsky.social @nicaogr.bsky.social @loicland.bsky.social
📄 pdf: arxiv.org/abs/2412.14123
🌐 webpage: gastruc.github.io/anysat
April 30, 2025 at 1:49 PM
Reposted by Juliette Bertrand

We are happy to share LPOSS: Label Propagation Over Patches and Pixels for Open-vocabulary Semantic Segmentation.
LPOSS is a training-free method for open-vocabulary semantic segmentation using Vision-Language Models.
LPOSS is a training-free method for open-vocabulary semantic segmentation using Vision-Language Models.

March 27, 2025 at 2:02 PM
We are happy to share LPOSS: Label Propagation Over Patches and Pixels for Open-vocabulary Semantic Segmentation.
LPOSS is a training-free method for open-vocabulary semantic segmentation using Vision-Language Models.
LPOSS is a training-free method for open-vocabulary semantic segmentation using Vision-Language Models.
Reposted by Juliette Bertrand

ILIAS is a large-scale test dataset for evaluation on Instance-Level Image retrieval At Scale. It is designed to support future research in image-to-image and text-to-image retrieval for particular objects and serves as a benchmark for evaluating foundation models and retrieval techniques.

February 27, 2025 at 2:48 PM
ILIAS is a large-scale test dataset for evaluation on Instance-Level Image retrieval At Scale. It is designed to support future research in image-to-image and text-to-image retrieval for particular objects and serves as a benchmark for evaluating foundation models and retrieval techniques.
Reposted by Juliette Bertrand

Welcome to NAVER LABS Europe on Bluesky! We chose 'LABS blue' to kickoff our posts & we'd appreciate it if you could share this one widely tinyurl.com/2nt9jdnv 😊 #hiring #jobs #internships

February 21, 2025 at 3:58 PM
Welcome to NAVER LABS Europe on Bluesky! We chose 'LABS blue' to kickoff our posts & we'd appreciate it if you could share this one widely tinyurl.com/2nt9jdnv 😊 #hiring #jobs #internships
Reposted by Juliette Bertrand

(1/3) Happy to share LUDVIG: Learning-free Uplifting of 2D Visual features to Gaussian Splatting scenes, that uplifts visual features from models such as DINOv2 (left) & CLIP (mid) to 3DGS scenes. Joint work w. @dlarlus.bsky.social @jmairal.bsky.social
Webpage & code: juliettemarrie.github.io/ludvig
Webpage & code: juliettemarrie.github.io/ludvig
January 31, 2025 at 9:59 AM
(1/3) Happy to share LUDVIG: Learning-free Uplifting of 2D Visual features to Gaussian Splatting scenes, that uplifts visual features from models such as DINOv2 (left) & CLIP (mid) to 3DGS scenes. Joint work w. @dlarlus.bsky.social @jmairal.bsky.social
Webpage & code: juliettemarrie.github.io/ludvig
Webpage & code: juliettemarrie.github.io/ludvig
Reposted by Juliette Bertrand

Physics IQ Benchmark: Do generative video models learn physical principles from watching videos?
TL;DR: comprehensive benchmark dataset; various physical principles (fluid dynamics, optics, solid mechanics, magnetism and thermodynamics); Performed on recent video generators
TL;DR: comprehensive benchmark dataset; various physical principles (fluid dynamics, optics, solid mechanics, magnetism and thermodynamics); Performed on recent video generators
January 21, 2025 at 2:28 PM
Physics IQ Benchmark: Do generative video models learn physical principles from watching videos?
TL;DR: comprehensive benchmark dataset; various physical principles (fluid dynamics, optics, solid mechanics, magnetism and thermodynamics); Performed on recent video generators
TL;DR: comprehensive benchmark dataset; various physical principles (fluid dynamics, optics, solid mechanics, magnetism and thermodynamics); Performed on recent video generators
Reposted by Juliette Bertrand

Outstanding Finalist 2: “DINOv2: Learning Robust Visual Features without Supervision," by Maxime Oquab, Timothée Darcet, Théo Moutakanni et al. 5/n openreview.net/forum?id=a68...

DINOv2: Learning Robust Visual Features without Supervision
The recent breakthroughs in natural language processing for model pretraining on large quantities of data have opened the way for similar foundation models in computer vision. These models could...
openreview.net
January 8, 2025 at 5:41 PM
Outstanding Finalist 2: “DINOv2: Learning Robust Visual Features without Supervision," by Maxime Oquab, Timothée Darcet, Théo Moutakanni et al. 5/n openreview.net/forum?id=a68...