



Jouni Sirén
@jltsiren.bsky.social
Researcher at UCSC Genomics Institute. Space-efficient data structures and pangenome graphs.
Our latest vg release introduces GBZ v2 with better compression for sequences. I originally assumed that the total sequence length in a pangenome graph would be similar to the size of the genome. This does not hold in the full HPRC graphs due to unaligned centromeres.
Release vg 1.72.0 - Littlefoot · vgteam/vg
Don't forget to mark the static binary executable:
chmod +x vg
Docker Image: quay.io/vgteam/vg:v1.72.0
Buildable Source Tarball: vg-v1.72.0.tar.gz
Includes source for vg and all submodules. Use th...
github.com
February 10, 2026 at 10:50 PM
Our latest vg release introduces GBZ v2 with better compression for sequences. I originally assumed that the total sequence length in a pangenome graph would be similar to the size of the genome. This does not hold in the full HPRC graphs due to unaligned centromeres.
Reposted by Jouni Sirén

Looking for a postdoc to build my new lab at TGen (Phoenix, AZ) focused on pangenome methods for cancer and complex disease. Full stack — from pangenome assembly and compression to association studies and somatic variant discovery. Reach out if interested! guarracinolab.github.io#join

Guarracino Lab | Pangenome Research
We develop methods to build and analyze pangenomes, with applications in cancer and complex disease. Translational Genomics Research Institute, Phoenix, AZ.
guarracinolab.github.io
February 6, 2026 at 4:02 PM
Looking for a postdoc to build my new lab at TGen (Phoenix, AZ) focused on pangenome methods for cancer and complex disease. Full stack — from pangenome assembly and compression to association studies and somatic variant discovery. Reach out if interested! guarracinolab.github.io#join
Reposted by Jouni Sirén
I am looking for a postdoc to develop high-performance algorithms in computational genomics. Email or DM me if interested. For more information, see hlilab.github.io/vacancies. RTs appreciated!
HLi Lab - Vacancies
Openings
hlilab.github.io
January 14, 2026 at 3:44 PM
I am looking for a postdoc to develop high-performance algorithms in computational genomics. Email or DM me if interested. For more information, see hlilab.github.io/vacancies. RTs appreciated!
Reposted by Jouni Sirén

First time seeing this and it is really great! abseil.io/fast/hints.h...
abseil / Performance Hints
An open-source collection of core C++ library code
abseil.io
December 20, 2025 at 3:04 AM
First time seeing this and it is really great! abseil.io/fast/hints.h...
VG will soon start adding headers to the GAF files it generates. The specifics are still uncertain, but if you maintain a GAF parser, it may be a good idea to skip lines starting with "@". Here is a draft specification for the vg flavor of GAF.
github.com
October 31, 2025 at 3:27 AM
VG will soon start adding headers to the GAF files it generates. The specifics are still uncertain, but if you maintain a GAF parser, it may be a good idea to skip lines starting with "@". Here is a draft specification for the vg flavor of GAF.
Reposted by Jouni Sirén

1/6 Movi 2 is here: faster and more space-efficient for pangenome queries. Its fastest mode uses half the memory of Movi 1 while running ~30% faster. github.com/mohsenzakeri...

GitHub - mohsenzakeri/Movi: Fast, Cache-Efficient, and Scalable Queries on Pangenomes
Fast, Cache-Efficient, and Scalable Queries on Pangenomes - mohsenzakeri/Movi
github.com
October 21, 2025 at 8:00 PM
1/6 Movi 2 is here: faster and more space-efficient for pangenome queries. Its fastest mode uses half the memory of Movi 1 while running ~30% faster. github.com/mohsenzakeri...
Reposted by Jouni Sirén

For the weekend crowd. I'm hiring a postdoc! If you're interested in algorithms, data structures and high-dimensional inference, and if you want to invent new methods for genomics and implement them in high-performance, robust and easy-to-use software, do I have a lab for you; ours!
Hi bioinformatics, genomics and CS friends! Please help me spread the word. I'm hiring a postdoc! Come work on cutting edge method development in algorithmic genomics with me and my group at @umdscience.bsky.social! 🖥️🧬
And it's posted! If you're interested and eligible, please consider applying through the UMD portal: umd.wd1.myworkdayjobs.com/en-US/UMCP/j....
If you're a PI working in algorithmic genomics (& you can recommend my lab to your top graduating students ;P), please let them know!
If you're a PI working in algorithmic genomics (& you can recommend my lab to your top graduating students ;P), please let them know!
October 11, 2025 at 1:10 PM
For the weekend crowd. I'm hiring a postdoc! If you're interested in algorithms, data structures and high-dimensional inference, and if you want to invent new methods for genomics and implement them in high-performance, robust and easy-to-use software, do I have a lab for you; ours!
Reposted by Jouni Sirén

🦒Long read giraffe is out!🦒
Mapping long reads to pangenome graphs is ~10x faster than with GraphAligner, with veeery slightly better mapping accuracy, short variant calling, and SV genotyping than GraphAligner or Minimap2
Mapping long reads to pangenome graphs is ~10x faster than with GraphAligner, with veeery slightly better mapping accuracy, short variant calling, and SV genotyping than GraphAligner or Minimap2

Rapid, accurate long- and short-read mapping to large pangenome graphs with vg Giraffe https://www.biorxiv.org/content/10.1101/2025.09.29.678807v1
October 2, 2025 at 6:28 AM
🦒Long read giraffe is out!🦒
Mapping long reads to pangenome graphs is ~10x faster than with GraphAligner, with veeery slightly better mapping accuracy, short variant calling, and SV genotyping than GraphAligner or Minimap2
Mapping long reads to pangenome graphs is ~10x faster than with GraphAligner, with veeery slightly better mapping accuracy, short variant calling, and SV genotyping than GraphAligner or Minimap2
Reposted by Jouni Sirén

We are glad to announce that the next workshop “Data Structures in Bioinformatics” (DSB 2026) will take place in Venice, Italy, on *February 18-19*, 2026. dsb-meeting.github.io/DSB2026/ Book the dates! #DSB26
DSB 2026 Venice - February 18-19
Workshop Data Structures in Bioinformatics
dsb-meeting.github.io
September 1, 2025 at 6:10 PM
We are glad to announce that the next workshop “Data Structures in Bioinformatics” (DSB 2026) will take place in Venice, Italy, on *February 18-19*, 2026. dsb-meeting.github.io/DSB2026/ Book the dates! #DSB26
GBZ-base has been a side project for me for a couple of years. It's basically a GBZ graph stored in SQLite instead of a custom file format. You can convert a GBZ graph to GBZ-base quickly and then extract subgraphs around nodes / reference positions on a laptop. 1/n

GitHub - jltsiren/gbz-base: Prototype for an immutable pangenome graph in SQLite
Prototype for an immutable pangenome graph in SQLite - jltsiren/gbz-base
github.com
August 28, 2025 at 12:49 AM
GBZ-base has been a side project for me for a couple of years. It's basically a GBZ graph stored in SQLite instead of a custom file format. You can convert a GBZ graph to GBZ-base quickly and then extract subgraphs around nodes / reference positions on a laptop. 1/n

There was a workshop on 25 years of the FM-index and the CSA after SEA. I would have liked to attend, but I had other commitments. The invited speakers were Giovanni Manzini and Roberto Grossi, as the other purpose of the workshop was to present them Festschrifts for their 60th birthdays. 1/6
SEA 2025
regindex.github.io
August 8, 2025 at 9:49 AM
There was a workshop on 25 years of the FM-index and the CSA after SEA. I would have liked to attend, but I had other commitments. The invited speakers were Giovanni Manzini and Roberto Grossi, as the other purpose of the workshop was to present them Festschrifts for their 60th birthdays. 1/6
A new preprint on indexing pangenome graphs using an FM-index of the haplotypes and a tag array. Joint work with Parsa Eskandar and @benedictpaten.bsky.social.

Lossless Pangenome Indexing Using Tag Arrays
Pangenome graphs represent the genomic variation by encoding multiple haplotypes within a unified graph structure. However, efficient and lossless indexing of such structures remains challenging due t...
www.biorxiv.org
May 15, 2025 at 8:22 PM
A new preprint on indexing pangenome graphs using an FM-index of the haplotypes and a tag array. Joint work with Parsa Eskandar and @benedictpaten.bsky.social.
We use personalized references with our Giraffe aligner. Each chromosome is partitioned into a sequence of blocks. We sample the most relevant haplotypes in each block using kmer counts. Mapping to this personalized reference improves variant calling accuracy. www.nature.com/articles/s41...
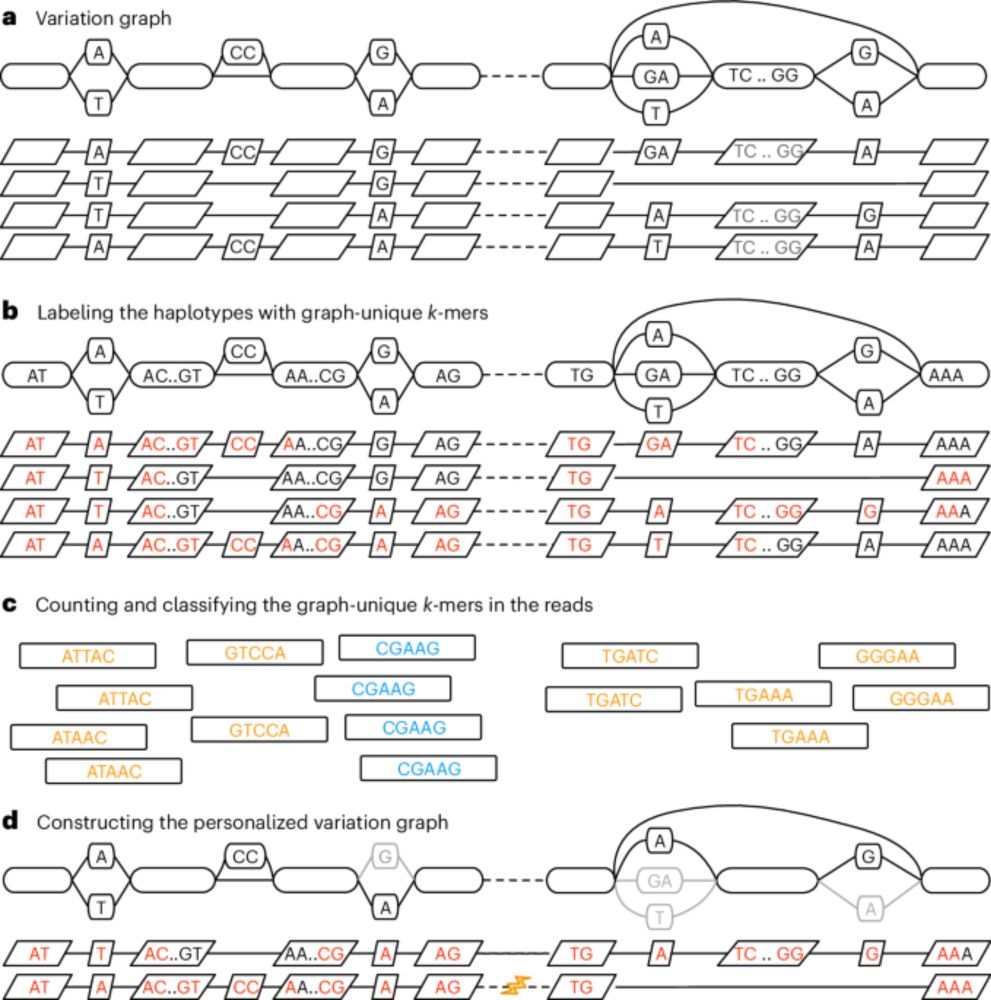
Personalized pangenome references - Nature Methods
This work introduces a k-mer-based approach to customizing a pangenome reference, making it more relevant to a new sample of interest. This method enhances the accuracy of genotyping small variants an...
www.nature.com
March 4, 2025 at 11:00 PM
We use personalized references with our Giraffe aligner. Each chromosome is partitioned into a sequence of blocks. We sample the most relevant haplotypes in each block using kmer counts. Mapping to this personalized reference improves variant calling accuracy. www.nature.com/articles/s41...
Coming up soon in vg: faster GAF sorting. The old algorithm was spending too much time parsing and serializing alignments. The new algorithm just deals with blobs and integer keys. With that and some algorithmic improvements, you can now expect to sort 30x short reads in 15-20 minutes on a laptop.
January 25, 2025 at 3:05 AM
Coming up soon in vg: faster GAF sorting. The old algorithm was spending too much time parsing and serializing alignments. The new algorithm just deals with blobs and integer keys. With that and some algorithmic improvements, you can now expect to sort 30x short reads in 15-20 minutes on a laptop.