




Jesseba Fernando
@jesseba.bsky.social
PhD Student @nunetsi.bsky.social
Put me in the middle of nowhere with coffee and I'm happy
jesseba.github.io
Put me in the middle of nowhere with coffee and I'm happy
jesseba.github.io
Packed room at our satellite!!

September 3, 2025 at 10:42 AM
Packed room at our satellite!!
Super, super excited to be here at the sixth annual conference on the Mathematics of Neuroscience and AI!

May 28, 2025 at 7:55 AM
Super, super excited to be here at the sixth annual conference on the Mathematics of Neuroscience and AI!
11/ Finally, we asked: Does the RS behave like a dynamical system?
To test this, we teleported RS vectors to different positions in PCA space and observed their evolution.
Result? Early layers exhibit attractor-like behavior—pushing activations back toward their “natural” trajectory.
To test this, we teleported RS vectors to different positions in PCA space and observed their evolution.
Result? Early layers exhibit attractor-like behavior—pushing activations back toward their “natural” trajectory.

February 21, 2025 at 3:05 PM
11/ Finally, we asked: Does the RS behave like a dynamical system?
To test this, we teleported RS vectors to different positions in PCA space and observed their evolution.
Result? Early layers exhibit attractor-like behavior—pushing activations back toward their “natural” trajectory.
To test this, we teleported RS vectors to different positions in PCA space and observed their evolution.
Result? Early layers exhibit attractor-like behavior—pushing activations back toward their “natural” trajectory.
10/ To visualize global RS behavior, we trained a Compressing Autoencoder (CAE)—squashing activations into 2D.
The CAE finds low-dimensional population dynamics, which showed that early layers are harder to reconstruct, while later layers become lower-dimensional and more structured.
The CAE finds low-dimensional population dynamics, which showed that early layers are harder to reconstruct, while later layers become lower-dimensional and more structured.

February 21, 2025 at 3:05 PM
10/ To visualize global RS behavior, we trained a Compressing Autoencoder (CAE)—squashing activations into 2D.
The CAE finds low-dimensional population dynamics, which showed that early layers are harder to reconstruct, while later layers become lower-dimensional and more structured.
The CAE finds low-dimensional population dynamics, which showed that early layers are harder to reconstruct, while later layers become lower-dimensional and more structured.
9/ Looking at individual unit dynamics, we found rotational trajectories in activation space!
Some units spin around a fixed point, others spiral outward. On average, RS units circle ~10 times over 64 layers.
Some units spin around a fixed point, others spiral outward. On average, RS units circle ~10 times over 64 layers.

February 21, 2025 at 3:05 PM
9/ Looking at individual unit dynamics, we found rotational trajectories in activation space!
Some units spin around a fixed point, others spiral outward. On average, RS units circle ~10 times over 64 layers.
Some units spin around a fixed point, others spiral outward. On average, RS units circle ~10 times over 64 layers.
8/ And here’s something even weirder: mutual information drops in early layers, then slowly climbs back up. Why? We’re not sure—perhaps early layers are quite predictable from one to the next, but in a nonlinear way...
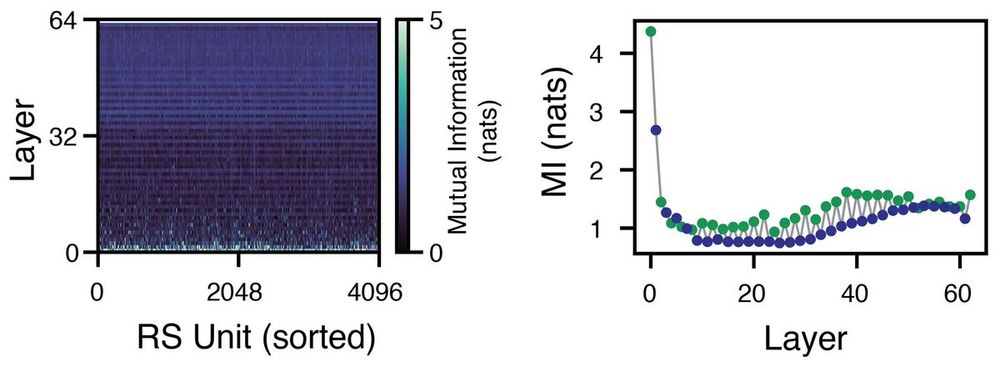
February 21, 2025 at 3:05 PM
8/ And here’s something even weirder: mutual information drops in early layers, then slowly climbs back up. Why? We’re not sure—perhaps early layers are quite predictable from one to the next, but in a nonlinear way...
7/ Zooming out: the cosine similarity of the RS vector between layers increases.
Translation: The model’s internal representations become more aligned as we move deeper through the model. But they also accelerate!
Translation: The model’s internal representations become more aligned as we move deeper through the model. But they also accelerate!

February 21, 2025 at 3:05 PM
7/ Zooming out: the cosine similarity of the RS vector between layers increases.
Translation: The model’s internal representations become more aligned as we move deeper through the model. But they also accelerate!
Translation: The model’s internal representations become more aligned as we move deeper through the model. But they also accelerate!
6/ Second surprise: RS activations are highly correlated layer to layer.
A given unit’s activation is highly correlated across layers—especially within a layer (attention to MLP) vs. across layers.
A given unit’s activation is highly correlated across layers—especially within a layer (attention to MLP) vs. across layers.

February 21, 2025 at 3:05 PM
6/ Second surprise: RS activations are highly correlated layer to layer.
A given unit’s activation is highly correlated across layers—especially within a layer (attention to MLP) vs. across layers.
A given unit’s activation is highly correlated across layers—especially within a layer (attention to MLP) vs. across layers.
5/ First surprise: RS activations increase in density over layers.
Early layers are sparse, later layers are dense. Why? There’s no a priori reason for this—blocks could just as easily write balancing negative values. But they don’t.
Early layers are sparse, later layers are dense. Why? There’s no a priori reason for this—blocks could just as easily write balancing negative values. But they don’t.

February 21, 2025 at 3:05 PM
5/ First surprise: RS activations increase in density over layers.
Early layers are sparse, later layers are dense. Why? There’s no a priori reason for this—blocks could just as easily write balancing negative values. But they don’t.
Early layers are sparse, later layers are dense. Why? There’s no a priori reason for this—blocks could just as easily write balancing negative values. But they don’t.
2/ @guitchounts.bsky.social
and I went on a little side-quest in which we took a page out of neuroscience to see if we can understand AI—LLMs in this case—a little better. 🧵
and I went on a little side-quest in which we took a page out of neuroscience to see if we can understand AI—LLMs in this case—a little better. 🧵

February 21, 2025 at 3:05 PM
2/ @guitchounts.bsky.social
and I went on a little side-quest in which we took a page out of neuroscience to see if we can understand AI—LLMs in this case—a little better. 🧵
and I went on a little side-quest in which we took a page out of neuroscience to see if we can understand AI—LLMs in this case—a little better. 🧵