




Jérémie Beucler
@jeremiebeucler.bsky.social
PhD student with Wim de Neys & Lucie Charles at LaPsyDE; MSc in Cog Sciences at ENS - interested in reasoning & metacognition
https://jeremie-beucler.github.io/
https://jeremie-beucler.github.io/
8/10
We also re-analyzed existing base-rate stimuli from past research using our method. The results revealed a large, previously unnoticed variability in belief strength, which could be problematic in some cases.
We also re-analyzed existing base-rate stimuli from past research using our method. The results revealed a large, previously unnoticed variability in belief strength, which could be problematic in some cases.

October 16, 2025 at 4:17 PM
8/10
We also re-analyzed existing base-rate stimuli from past research using our method. The results revealed a large, previously unnoticed variability in belief strength, which could be problematic in some cases.
We also re-analyzed existing base-rate stimuli from past research using our method. The results revealed a large, previously unnoticed variability in belief strength, which could be problematic in some cases.
7/10
This method allows us to create a massive database of over 100,000 base-rate items, each with an associated belief strength value.
Here is an example of every possible items for one single adjective out of 66 ("Arrogant")! Best to be a kindergarten teacher than a politician in this case. 🤭
This method allows us to create a massive database of over 100,000 base-rate items, each with an associated belief strength value.
Here is an example of every possible items for one single adjective out of 66 ("Arrogant")! Best to be a kindergarten teacher than a politician in this case. 🤭

October 16, 2025 at 4:17 PM
7/10
This method allows us to create a massive database of over 100,000 base-rate items, each with an associated belief strength value.
Here is an example of every possible items for one single adjective out of 66 ("Arrogant")! Best to be a kindergarten teacher than a politician in this case. 🤭
This method allows us to create a massive database of over 100,000 base-rate items, each with an associated belief strength value.
Here is an example of every possible items for one single adjective out of 66 ("Arrogant")! Best to be a kindergarten teacher than a politician in this case. 🤭
6/10
And it works really well! LLM-generated ratings showed a very strong correlation with human judgments.
More importantly, our belief-strength measure robustly predicted participants' actual choices in a separate base-rate neglect experiment!
And it works really well! LLM-generated ratings showed a very strong correlation with human judgments.
More importantly, our belief-strength measure robustly predicted participants' actual choices in a separate base-rate neglect experiment!

October 16, 2025 at 4:17 PM
6/10
And it works really well! LLM-generated ratings showed a very strong correlation with human judgments.
More importantly, our belief-strength measure robustly predicted participants' actual choices in a separate base-rate neglect experiment!
And it works really well! LLM-generated ratings showed a very strong correlation with human judgments.
More importantly, our belief-strength measure robustly predicted participants' actual choices in a separate base-rate neglect experiment!
3/10
We argue that measuring “belief strength” is a major bottleneck in reasoning research, which mostly relies on conflict vs. no-conflict items.
It requires costly human ratings and is rarely done parametrically, limiting the development of theoretical & computational models of biased reasoning.
We argue that measuring “belief strength” is a major bottleneck in reasoning research, which mostly relies on conflict vs. no-conflict items.
It requires costly human ratings and is rarely done parametrically, limiting the development of theoretical & computational models of biased reasoning.

October 16, 2025 at 4:17 PM
3/10
We argue that measuring “belief strength” is a major bottleneck in reasoning research, which mostly relies on conflict vs. no-conflict items.
It requires costly human ratings and is rarely done parametrically, limiting the development of theoretical & computational models of biased reasoning.
We argue that measuring “belief strength” is a major bottleneck in reasoning research, which mostly relies on conflict vs. no-conflict items.
It requires costly human ratings and is rarely done parametrically, limiting the development of theoretical & computational models of biased reasoning.
1/10
🚨 New preprint: Using Large Language Models to Estimate Belief Strength in Reasoning 🚨
When asked: "There are 995 politicians and 5 nurses. Person 'L' is kind. Is Person 'L' more likely to be a politician or a nurse?", most people will answer "nurse", neglecting the base-rate info.
A 🧵👇
🚨 New preprint: Using Large Language Models to Estimate Belief Strength in Reasoning 🚨
When asked: "There are 995 politicians and 5 nurses. Person 'L' is kind. Is Person 'L' more likely to be a politician or a nurse?", most people will answer "nurse", neglecting the base-rate info.
A 🧵👇

October 16, 2025 at 4:17 PM
1/10
🚨 New preprint: Using Large Language Models to Estimate Belief Strength in Reasoning 🚨
When asked: "There are 995 politicians and 5 nurses. Person 'L' is kind. Is Person 'L' more likely to be a politician or a nurse?", most people will answer "nurse", neglecting the base-rate info.
A 🧵👇
🚨 New preprint: Using Large Language Models to Estimate Belief Strength in Reasoning 🚨
When asked: "There are 995 politicians and 5 nurses. Person 'L' is kind. Is Person 'L' more likely to be a politician or a nurse?", most people will answer "nurse", neglecting the base-rate info.
A 🧵👇
Curious about the mechanisms behind biased reasoning and metacognition? 🤔
📍 Come see our poster at #CCN2025, Aug 12, 1:30–4:30pm
We show how a biased drift-diffusion model can explain choice, RT and confidence in a base-rate neglect task, revealing why more deliberation doesn’t always fix bias.
📍 Come see our poster at #CCN2025, Aug 12, 1:30–4:30pm
We show how a biased drift-diffusion model can explain choice, RT and confidence in a base-rate neglect task, revealing why more deliberation doesn’t always fix bias.

August 11, 2025 at 1:06 PM
Curious about the mechanisms behind biased reasoning and metacognition? 🤔
📍 Come see our poster at #CCN2025, Aug 12, 1:30–4:30pm
We show how a biased drift-diffusion model can explain choice, RT and confidence in a base-rate neglect task, revealing why more deliberation doesn’t always fix bias.
📍 Come see our poster at #CCN2025, Aug 12, 1:30–4:30pm
We show how a biased drift-diffusion model can explain choice, RT and confidence in a base-rate neglect task, revealing why more deliberation doesn’t always fix bias.
6/8
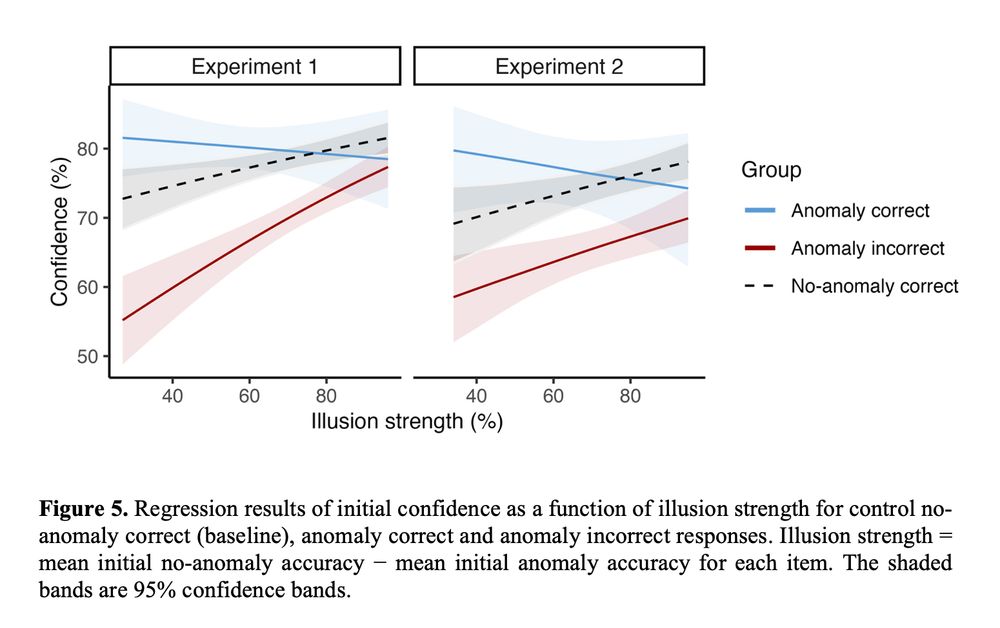
Finding #3: The strength of the illusion is key! As the semantic overlap gets stronger (e.g., "Moses" is closer to "Noah" than "Goliath" is), confidence in incorrect answers tended to increase, while confidence in correct answers tended to decrease. 📈📉
Finding #3: The strength of the illusion is key! As the semantic overlap gets stronger (e.g., "Moses" is closer to "Noah" than "Goliath" is), confidence in incorrect answers tended to increase, while confidence in correct answers tended to decrease. 📈📉
August 6, 2025 at 10:24 AM
6/8
Finding #3: The strength of the illusion is key! As the semantic overlap gets stronger (e.g., "Moses" is closer to "Noah" than "Goliath" is), confidence in incorrect answers tended to increase, while confidence in correct answers tended to decrease. 📈📉
Finding #3: The strength of the illusion is key! As the semantic overlap gets stronger (e.g., "Moses" is closer to "Noah" than "Goliath" is), confidence in incorrect answers tended to increase, while confidence in correct answers tended to decrease. 📈📉
5/8
Finding #2: Even when participants got it wrong and fell for the illusion, they showed a significant error sensitivity (lower confidence). Interestingly, this effect was not affected by load and deadline, suggesting this error sensitivity is intuitive.
Finding #2: Even when participants got it wrong and fell for the illusion, they showed a significant error sensitivity (lower confidence). Interestingly, this effect was not affected by load and deadline, suggesting this error sensitivity is intuitive.

August 6, 2025 at 10:24 AM
5/8
Finding #2: Even when participants got it wrong and fell for the illusion, they showed a significant error sensitivity (lower confidence). Interestingly, this effect was not affected by load and deadline, suggesting this error sensitivity is intuitive.
Finding #2: Even when participants got it wrong and fell for the illusion, they showed a significant error sensitivity (lower confidence). Interestingly, this effect was not affected by load and deadline, suggesting this error sensitivity is intuitive.
4/8
Finding #1: You don't always need to be slow to be right! 🐢 A significant number of participants intuitively spotted the anomaly from the start, without needing extra time and resources to deliberate. 🐇 Sound intuitive reasoning does happen.
Finding #1: You don't always need to be slow to be right! 🐢 A significant number of participants intuitively spotted the anomaly from the start, without needing extra time and resources to deliberate. 🐇 Sound intuitive reasoning does happen.

August 6, 2025 at 10:24 AM
4/8
Finding #1: You don't always need to be slow to be right! 🐢 A significant number of participants intuitively spotted the anomaly from the start, without needing extra time and resources to deliberate. 🐇 Sound intuitive reasoning does happen.
Finding #1: You don't always need to be slow to be right! 🐢 A significant number of participants intuitively spotted the anomaly from the start, without needing extra time and resources to deliberate. 🐇 Sound intuitive reasoning does happen.
3/8
To test this, we ran 4 experiments with over 500 participants! We used a two-response paradigm: first, a quick intuitive answer under time pressure & cognitive load. Then, a final, deliberated response with no constraints. Here are the main results:
To test this, we ran 4 experiments with over 500 participants! We used a two-response paradigm: first, a quick intuitive answer under time pressure & cognitive load. Then, a final, deliberated response with no constraints. Here are the main results:

August 6, 2025 at 10:24 AM
3/8
To test this, we ran 4 experiments with over 500 participants! We used a two-response paradigm: first, a quick intuitive answer under time pressure & cognitive load. Then, a final, deliberated response with no constraints. Here are the main results:
To test this, we ran 4 experiments with over 500 participants! We used a two-response paradigm: first, a quick intuitive answer under time pressure & cognitive load. Then, a final, deliberated response with no constraints. Here are the main results:
2/8
These semantic illusions are often used to test for deliberate "System 2" thinking (e.g., in the verbal Cognitive Reflection Test). The classic theory? We intuitively fall for the illusion & need slow, effortful deliberation to correct the mistake. But is it really that simple?
These semantic illusions are often used to test for deliberate "System 2" thinking (e.g., in the verbal Cognitive Reflection Test). The classic theory? We intuitively fall for the illusion & need slow, effortful deliberation to correct the mistake. But is it really that simple?

August 6, 2025 at 10:24 AM
2/8
These semantic illusions are often used to test for deliberate "System 2" thinking (e.g., in the verbal Cognitive Reflection Test). The classic theory? We intuitively fall for the illusion & need slow, effortful deliberation to correct the mistake. But is it really that simple?
These semantic illusions are often used to test for deliberate "System 2" thinking (e.g., in the verbal Cognitive Reflection Test). The classic theory? We intuitively fall for the illusion & need slow, effortful deliberation to correct the mistake. But is it really that simple?
1/8
New (and first) paper accepted at JEP:LMC 🎉
Ever fallen for this type of questions: "How many animals of each kind did Moses take on the Ark?" Most say "Two," forgetting it was Noah, and not Moses, who took the animals on the Ark. But what’s really going on here? 🧵
New (and first) paper accepted at JEP:LMC 🎉
Ever fallen for this type of questions: "How many animals of each kind did Moses take on the Ark?" Most say "Two," forgetting it was Noah, and not Moses, who took the animals on the Ark. But what’s really going on here? 🧵

August 6, 2025 at 10:24 AM
1/8
New (and first) paper accepted at JEP:LMC 🎉
Ever fallen for this type of questions: "How many animals of each kind did Moses take on the Ark?" Most say "Two," forgetting it was Noah, and not Moses, who took the animals on the Ark. But what’s really going on here? 🧵
New (and first) paper accepted at JEP:LMC 🎉
Ever fallen for this type of questions: "How many animals of each kind did Moses take on the Ark?" Most say "Two," forgetting it was Noah, and not Moses, who took the animals on the Ark. But what’s really going on here? 🧵