



Jason Corso
@jasoncorso.bsky.social
Professor at Michigan | Voxel51 Co-Founder and Chief Scientist | Creator, Builder, Writer, Coder, Human
definition of "video model"????????
October 3, 2025 at 7:28 PM
definition of "video model"????????
Quit by Annie Duke ...a real life decision making read.

August 8, 2025 at 12:19 PM
Quit by Annie Duke ...a real life decision making read.
Awesome! What type of work is he looking for?
August 6, 2025 at 11:50 AM
Awesome! What type of work is he looking for?
Sure, here I am thinking, yes, but, umm, where did June 2020 go.... :)
July 2, 2025 at 2:37 PM
Sure, here I am thinking, yes, but, umm, where did June 2020 go.... :)
The world according to Elon. 🤦
June 21, 2025 at 6:41 PM
The world according to Elon. 🤦
- Understanding the tradeoffs of confidence thresholds enables better tuning of auto-labeling pipelines, prioritizing overall model effectiveness over superficial label cleanliness.
Read the full paper from the @Voxel51 team: arxiv.org/abs/2506.02359
Read the full paper from the @Voxel51 team: arxiv.org/abs/2506.02359

Auto-Labeling Data for Object Detection
Great labels make great models. However, traditional labeling approaches for tasks like object detection have substantial costs at scale. Furthermore, alternatives to fully-supervised object detection...
arxiv.org
June 4, 2025 at 4:27 PM
- Understanding the tradeoffs of confidence thresholds enables better tuning of auto-labeling pipelines, prioritizing overall model effectiveness over superficial label cleanliness.
Read the full paper from the @Voxel51 team: arxiv.org/abs/2506.02359
Read the full paper from the @Voxel51 team: arxiv.org/abs/2506.02359
💡Why this matters:
- Annotating large visual datasets can be done 100,000x cheaper and 5,000x faster with public, off-the-shelf models while maintaining quality.
- Highly accurate models can be trained at a fraction of the time and cost of those trained from human labels.
- Annotating large visual datasets can be done 100,000x cheaper and 5,000x faster with public, off-the-shelf models while maintaining quality.
- Highly accurate models can be trained at a fraction of the time and cost of those trained from human labels.
June 4, 2025 at 4:27 PM
💡Why this matters:
- Annotating large visual datasets can be done 100,000x cheaper and 5,000x faster with public, off-the-shelf models while maintaining quality.
- Highly accurate models can be trained at a fraction of the time and cost of those trained from human labels.
- Annotating large visual datasets can be done 100,000x cheaper and 5,000x faster with public, off-the-shelf models while maintaining quality.
- Highly accurate models can be trained at a fraction of the time and cost of those trained from human labels.
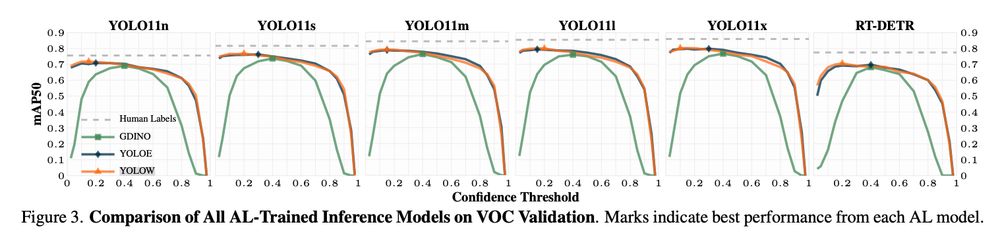
High-confidence labels (0.8–0.9), while appearing cleaner, consistently harmed downstream performance due to reduced recall.
Understanding this balance enables better tuning of auto-labeling pipelines, prioritizing overall model effectiveness over superficial label cleanliness.
Understanding this balance enables better tuning of auto-labeling pipelines, prioritizing overall model effectiveness over superficial label cleanliness.
June 4, 2025 at 4:27 PM
High-confidence labels (0.8–0.9), while appearing cleaner, consistently harmed downstream performance due to reduced recall.
Understanding this balance enables better tuning of auto-labeling pipelines, prioritizing overall model effectiveness over superficial label cleanliness.
Understanding this balance enables better tuning of auto-labeling pipelines, prioritizing overall model effectiveness over superficial label cleanliness.
📊 Higher confidence threshold isn’t always better.
This is an interesting one. Somewhat counterintuitively, setting a relatively low confidence level (ɑ ≈ 0.2) for auto labels maximized the precision and recall of downstream models trained from auto-labeled data.
This is an interesting one. Somewhat counterintuitively, setting a relatively low confidence level (ɑ ≈ 0.2) for auto labels maximized the precision and recall of downstream models trained from auto-labeled data.
June 4, 2025 at 4:27 PM
📊 Higher confidence threshold isn’t always better.
This is an interesting one. Somewhat counterintuitively, setting a relatively low confidence level (ɑ ≈ 0.2) for auto labels maximized the precision and recall of downstream models trained from auto-labeled data.
This is an interesting one. Somewhat counterintuitively, setting a relatively low confidence level (ɑ ≈ 0.2) for auto labels maximized the precision and recall of downstream models trained from auto-labeled data.
📊For less-represented classes, models trained from auto labels sometimes performed even better.
The image below compares a human-labeled image (left) with an auto-labeled one (right). Humans are clearly, umm, lazy here :)
The image below compares a human-labeled image (left) with an auto-labeled one (right). Humans are clearly, umm, lazy here :)

June 4, 2025 at 4:27 PM
📊For less-represented classes, models trained from auto labels sometimes performed even better.
The image below compares a human-labeled image (left) with an auto-labeled one (right). Humans are clearly, umm, lazy here :)
The image below compares a human-labeled image (left) with an auto-labeled one (right). Humans are clearly, umm, lazy here :)
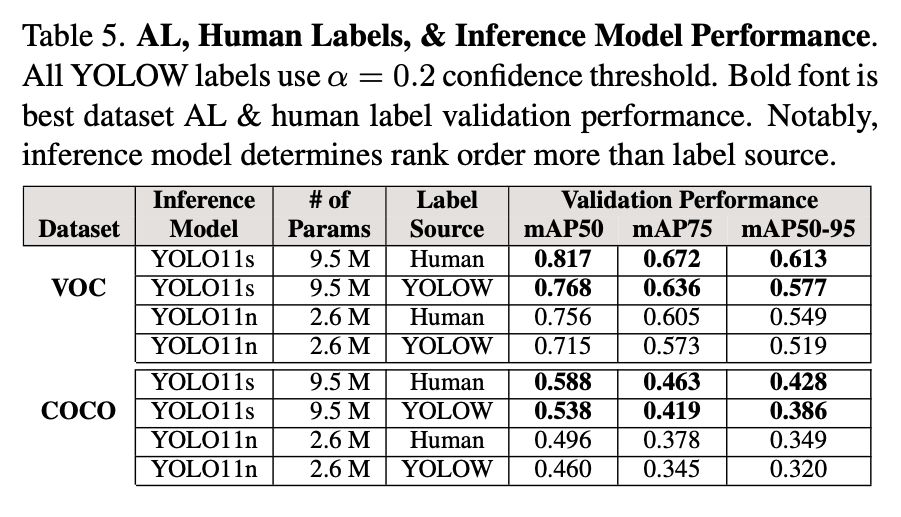
On COCO, auto-labeled models reached mAP50 of 0.538 compared to 0.588 for human-labeled counterparts, demonstrating competitive real-world performance.
June 4, 2025 at 4:27 PM
On COCO, auto-labeled models reached mAP50 of 0.538 compared to 0.588 for human-labeled counterparts, demonstrating competitive real-world performance.
📊 Comparable accuracy to human labels.
The mean average precision (mAP) of inference models trained from auto labels approached those trained from human labels.
On VOC, auto-labeled models achieved mAP50 scores of 0.768, closely matching the 0.817 achieved with human-labeled data.
The mean average precision (mAP) of inference models trained from auto labels approached those trained from human labels.
On VOC, auto-labeled models achieved mAP50 scores of 0.768, closely matching the 0.817 achieved with human-labeled data.
June 4, 2025 at 4:27 PM
📊 Comparable accuracy to human labels.
The mean average precision (mAP) of inference models trained from auto labels approached those trained from human labels.
On VOC, auto-labeled models achieved mAP50 scores of 0.768, closely matching the 0.817 achieved with human-labeled data.
The mean average precision (mAP) of inference models trained from auto labels approached those trained from human labels.
On VOC, auto-labeled models achieved mAP50 scores of 0.768, closely matching the 0.817 achieved with human-labeled data.
The findings:
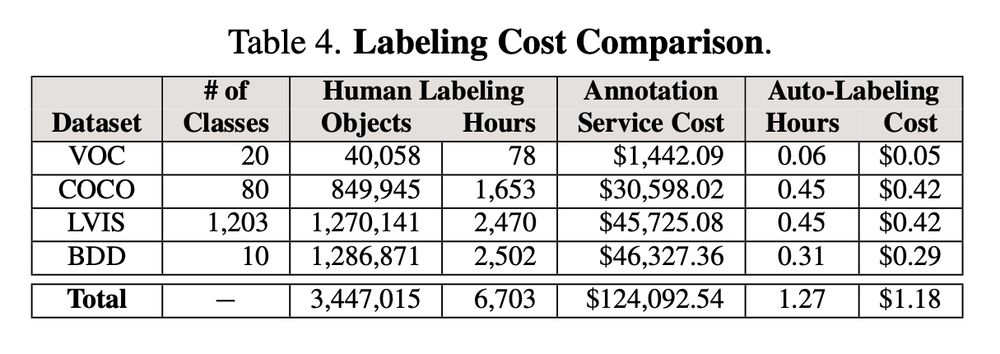
📊 Massive cost and time savings.
Using Verified Auto Labeling costs $1.18 and 1 hour in @NVIDIA L40S GPU time, vs. over $124,092 and 6,703 hours for human annotation.
Read our blog to dive deeper: link.voxel51.com/verified-auto-labeling-tw/
📊 Massive cost and time savings.
Using Verified Auto Labeling costs $1.18 and 1 hour in @NVIDIA L40S GPU time, vs. over $124,092 and 6,703 hours for human annotation.
Read our blog to dive deeper: link.voxel51.com/verified-auto-labeling-tw/
June 4, 2025 at 4:27 PM
The findings:
📊 Massive cost and time savings.
Using Verified Auto Labeling costs $1.18 and 1 hour in @NVIDIA L40S GPU time, vs. over $124,092 and 6,703 hours for human annotation.
Read our blog to dive deeper: link.voxel51.com/verified-auto-labeling-tw/
📊 Massive cost and time savings.
Using Verified Auto Labeling costs $1.18 and 1 hour in @NVIDIA L40S GPU time, vs. over $124,092 and 6,703 hours for human annotation.
Read our blog to dive deeper: link.voxel51.com/verified-auto-labeling-tw/
- Trained downstream inference models on both the auto-labeled and human-labeled data and compared their performances
- Translated our research into a new annotation tool called Verified Auto Labeling
- Translated our research into a new annotation tool called Verified Auto Labeling
June 4, 2025 at 4:27 PM
- Trained downstream inference models on both the auto-labeled and human-labeled data and compared their performances
- Translated our research into a new annotation tool called Verified Auto Labeling
- Translated our research into a new annotation tool called Verified Auto Labeling
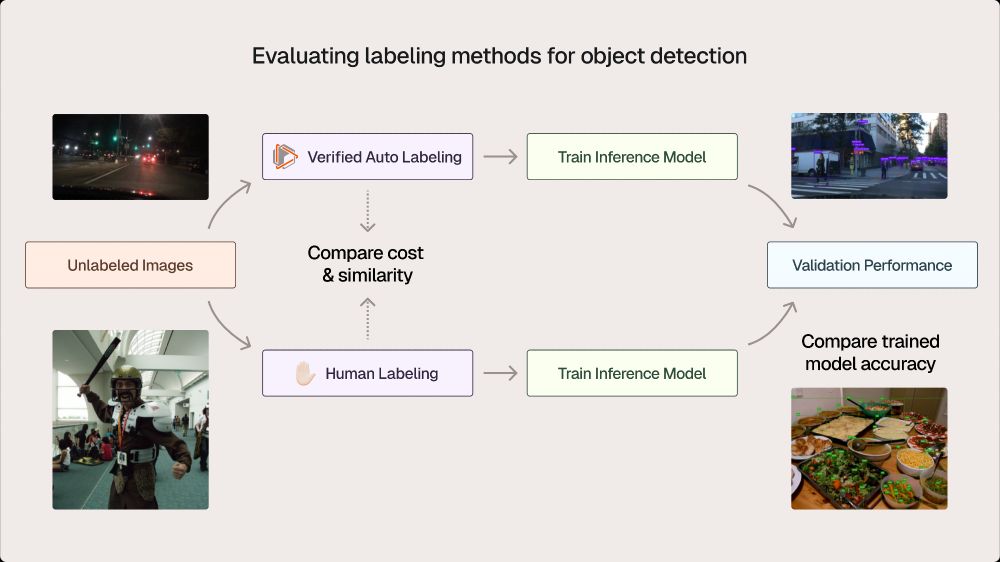
🛠 What we did:
- Used off-the-shelf foundation models to label several benchmark datasets
- Evaluated these labels relative to the human-annotated ground truth
- Used off-the-shelf foundation models to label several benchmark datasets
- Evaluated these labels relative to the human-annotated ground truth
June 4, 2025 at 4:27 PM
🛠 What we did:
- Used off-the-shelf foundation models to label several benchmark datasets
- Evaluated these labels relative to the human-annotated ground truth
- Used off-the-shelf foundation models to label several benchmark datasets
- Evaluated these labels relative to the human-annotated ground truth
Annotation is frequently a critical bottleneck in computer vision, often driving data labeling costs into the millions.
Our goal with this experiment was to quantitatively evaluate how well zero-shot approaches perform and identify the parameters and configurations that unlock optimal results.
Our goal with this experiment was to quantitatively evaluate how well zero-shot approaches perform and identify the parameters and configurations that unlock optimal results.
June 4, 2025 at 4:27 PM
Annotation is frequently a critical bottleneck in computer vision, often driving data labeling costs into the millions.
Our goal with this experiment was to quantitatively evaluate how well zero-shot approaches perform and identify the parameters and configurations that unlock optimal results.
Our goal with this experiment was to quantitatively evaluate how well zero-shot approaches perform and identify the parameters and configurations that unlock optimal results.
The nightmare continues. And AAAI of all communities.
May 17, 2025 at 1:02 PM
The nightmare continues. And AAAI of all communities.
What's happening is awful. Is anyone aware of a law firm that has stepped up to cohesively collate responses against these illegal actions? Individual universities will likely handle things wildly differently, and, oh, have you heard? they're distracted now with other illegalities
April 19, 2025 at 1:34 PM
What's happening is awful. Is anyone aware of a law firm that has stepped up to cohesively collate responses against these illegal actions? Individual universities will likely handle things wildly differently, and, oh, have you heard? they're distracted now with other illegalities
be ready to debug debug debug.
April 17, 2025 at 1:21 PM
be ready to debug debug debug.