




Ivan Zhou
@ivanzhou.bsky.social
AI research @Databricks Mosaic
Previously AI @Uber, Stanford, LandingAI
https://www.ivanzhou.me
I train models in PyTorch and Jax 👨🏻💻
I love computer vision in many ways 📸
Previously AI @Uber, Stanford, LandingAI
https://www.ivanzhou.me
I train models in PyTorch and Jax 👨🏻💻
I love computer vision in many ways 📸
Reposted by Ivan Zhou

The hardest part about finetuning is that people don't have labeled data. Today, @databricks.bsky.social introduced TAO, a new finetuning method that only needs inputs, no labels necessary. Best of all, it actually beats supervised finetuning on labeled data. www.databricks.com/blog/tao-usi...

TAO: Using test-time compute to train efficient LLMs without labeled data
LIFT fine-tunes LLMs without labels using reinforcement learning, boosting performance on enterprise tasks.
www.databricks.com
March 25, 2025 at 5:19 PM
The hardest part about finetuning is that people don't have labeled data. Today, @databricks.bsky.social introduced TAO, a new finetuning method that only needs inputs, no labels necessary. Best of all, it actually beats supervised finetuning on labeled data. www.databricks.com/blog/tao-usi...
Reposted by Ivan Zhou

Two years ago at Mosaic we had an idea for an "RLXF as a service"
One year and an acquisition later, the prototypes went into preview at Databricks
Today we share some results and findings of "what does it take to actually do enterprise RL and put it into a real product"
One year and an acquisition later, the prototypes went into preview at Databricks
Today we share some results and findings of "what does it take to actually do enterprise RL and put it into a real product"
The hardest part about finetuning is that people don't have labeled data. Today, @databricks.bsky.social introduced TAO, a new finetuning method that only needs inputs, no labels necessary. Best of all, it actually beats supervised finetuning on labeled data. www.databricks.com/blog/tao-usi...
TAO: Using test-time compute to train efficient LLMs without labeled data
LIFT fine-tunes LLMs without labels using reinforcement learning, boosting performance on enterprise tasks.
www.databricks.com
March 25, 2025 at 8:05 PM
Two years ago at Mosaic we had an idea for an "RLXF as a service"
One year and an acquisition later, the prototypes went into preview at Databricks
Today we share some results and findings of "what does it take to actually do enterprise RL and put it into a real product"
One year and an acquisition later, the prototypes went into preview at Databricks
Today we share some results and findings of "what does it take to actually do enterprise RL and put it into a real product"
The vibe of sunset time in DC



March 14, 2025 at 12:04 PM
The vibe of sunset time in DC
Profiling code and hunting for 10x latency gains is pure joy 👨🏻💻
March 5, 2025 at 4:39 AM
Profiling code and hunting for 10x latency gains is pure joy 👨🏻💻
DeepSeek's inference system overview is truly impressive. However, we should not overinterpret its eye popping profit margin. The key takeaway is that with high traffic volumes, you can create extremely large batch sizes to maximize GPU utilization. The reported 545% profit margin comes with caveats
March 2, 2025 at 6:25 AM
DeepSeek's inference system overview is truly impressive. However, we should not overinterpret its eye popping profit margin. The key takeaway is that with high traffic volumes, you can create extremely large batch sizes to maximize GPU utilization. The reported 545% profit margin comes with caveats
New open source OCR VLM!

Introducing olmOCR, our open-source tool to extract clean plain text from PDFs!
Built for scale, olmOCR handles many document types with high throughput. Run it on your own GPU for free—at over 3000 token/s, equivalent to $190 per million pages, or 1/32 the cost of GPT-4o!
Built for scale, olmOCR handles many document types with high throughput. Run it on your own GPU for free—at over 3000 token/s, equivalent to $190 per million pages, or 1/32 the cost of GPT-4o!
February 26, 2025 at 12:56 AM
New open source OCR VLM!
Reposted by Ivan Zhou

We're probably a little too obsessed with zero-shot retrieval. If you have documents (you do), then you can generate synthetic data, and finetune your embedding. Blog post lead by @jacobianneuro.bsky.social shows how well this works in practice.
www.databricks.com/blog/improvi...
www.databricks.com/blog/improvi...
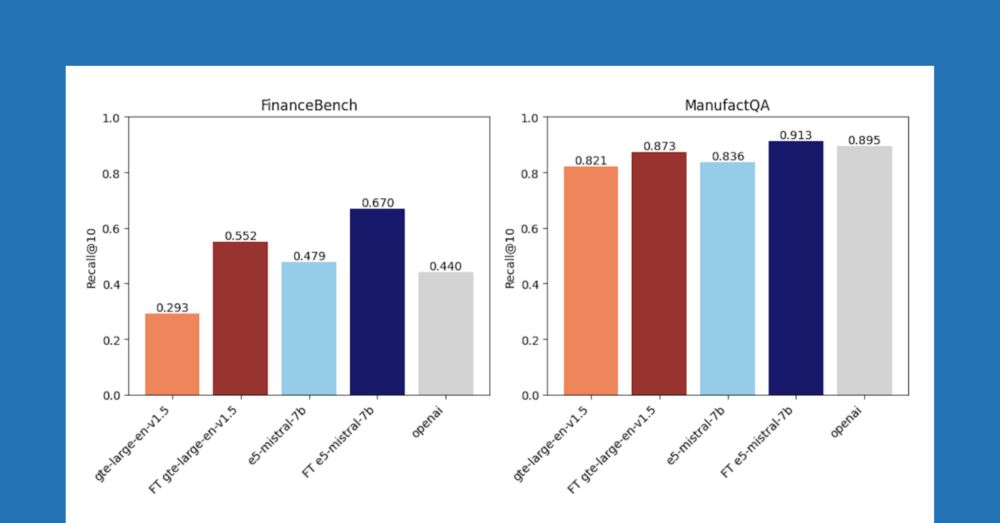
Improving Retrieval and RAG with Embedding Model Finetuning
Fine-tune embedding models on Databricks to enhance retrieval and RAG accuracy with synthetic data—no manual labeling required.
www.databricks.com
February 26, 2025 at 12:48 AM
We're probably a little too obsessed with zero-shot retrieval. If you have documents (you do), then you can generate synthetic data, and finetune your embedding. Blog post lead by @jacobianneuro.bsky.social shows how well this works in practice.
www.databricks.com/blog/improvi...
www.databricks.com/blog/improvi...
Reposted by Ivan Zhou

Making LLMs run efficiently can feel scary, but scaling isn’t magic, it’s math! We wanted to demystify the “systems view” of LLMs and wrote a little textbook called “How To Scale Your Model” which we’re releasing today. 1/n
February 4, 2025 at 6:54 PM
Making LLMs run efficiently can feel scary, but scaling isn’t magic, it’s math! We wanted to demystify the “systems view” of LLMs and wrote a little textbook called “How To Scale Your Model” which we’re releasing today. 1/n
It's remarkable to see the brightest minds and top talents from the US, China, and numerous other countries are all working to push AI's frontiers—advancing reasoning, efficiency, applications, etc.
While competition certainly exists, I'm finding more collaborative spirit in this coopetition state.
While competition certainly exists, I'm finding more collaborative spirit in this coopetition state.
January 28, 2025 at 12:23 AM
It's remarkable to see the brightest minds and top talents from the US, China, and numerous other countries are all working to push AI's frontiers—advancing reasoning, efficiency, applications, etc.
While competition certainly exists, I'm finding more collaborative spirit in this coopetition state.
While competition certainly exists, I'm finding more collaborative spirit in this coopetition state.
Qwen 2.5 VL seems to have great emphasis on document image analysis -- layout detection, special html output format, localization of objects -- and the performance on docvqa seems to be very strong.
Another big day for Chinese openly licensed model releases today. Here's Qwen 2.5 VL, the latest vision-LLM from Qwen with a 7B model that benchmarks comparably to GPT-4o mini simonwillison.net/2025/Jan/27/...
Qwen2.5 VL! Qwen2.5 VL! Qwen2.5 VL!
Hot on the heels of yesterday's [Qwen2.5-1M](https://simonwillison.net/2025/Jan/26/qwen25-1m/), here's Qwen2.5 VL (with an excitable announcement title) - the latest in Qwen's series of vision LLMs. T...
simonwillison.net
January 27, 2025 at 11:57 PM
Qwen 2.5 VL seems to have great emphasis on document image analysis -- layout detection, special html output format, localization of objects -- and the performance on docvqa seems to be very strong.
Reposted by Ivan Zhou

Alibaba's Qwen group just shipped Qwen2.5-7B-Instruct-1M and Qwen2.5-14B-Instruct-1M - two Apache 2 licensed LLMs with an impressive 1 million token context limit!
Here are my notes, including my so-far unsuccessful attempts to run large context prompts on my Mac simonwillison.net/2025/Jan/26/...
Here are my notes, including my so-far unsuccessful attempts to run large context prompts on my Mac simonwillison.net/2025/Jan/26/...
Qwen2.5-1M: Deploy Your Own Qwen with Context Length up to 1M Tokens
Very significant new release from Alibaba's Qwen team. Their openly licensed (sometimes Apache 2, sometimes Qwen license, I've had trouble keeping up) Qwen 2.5 LLM previously had an input token …
simonwillison.net
January 26, 2025 at 6:56 PM
Alibaba's Qwen group just shipped Qwen2.5-7B-Instruct-1M and Qwen2.5-14B-Instruct-1M - two Apache 2 licensed LLMs with an impressive 1 million token context limit!
Here are my notes, including my so-far unsuccessful attempts to run large context prompts on my Mac simonwillison.net/2025/Jan/26/...
Here are my notes, including my so-far unsuccessful attempts to run large context prompts on my Mac simonwillison.net/2025/Jan/26/...
Reposted by Ivan Zhou

I don’t care when “AGI” arrives I’m just out here having a good time with AI anyways.
January 21, 2025 at 4:15 PM
I don’t care when “AGI” arrives I’m just out here having a good time with AI anyways.
I was reading @natolambert.bsky.social's RLHF book when I came across an unexpected chapter about his experience working with data labeling vendors: rlhfbook.com/c/06-prefere...). He shared several realistic, frustrating stories and data points. I strongly resonated with his experiences.
The Basics of Reinforcement Learning from Human Feedback
The Basics of Reinforcement Learning from Human Feedback
rlhfbook.com
December 8, 2024 at 1:46 AM
I was reading @natolambert.bsky.social's RLHF book when I came across an unexpected chapter about his experience working with data labeling vendors: rlhfbook.com/c/06-prefere...). He shared several realistic, frustrating stories and data points. I strongly resonated with his experiences.
My girlfriend and I recently traveled to Europe for a conference as well as a vacation. We had a great time walking and exploring each of the cities that we visited. Here I am sharing my favorite photos captured in the trip:
www.ivanzhou.me/blog/2024/12...
www.ivanzhou.me/blog/2024/12...

From Vienna to Paris: A Collection of My Favorite Travel Photos in Europe — Ivan Zhou
My girlfriend and I recently traveled to Europe for a conference as well as a vacation. We went to Munich, Vienna, Rome, and Paris. We had a great time walking and exploring each of the cities that we...
www.ivanzhou.me
December 2, 2024 at 3:30 AM
My girlfriend and I recently traveled to Europe for a conference as well as a vacation. We had a great time walking and exploring each of the cities that we visited. Here I am sharing my favorite photos captured in the trip:
www.ivanzhou.me/blog/2024/12...
www.ivanzhou.me/blog/2024/12...
I’m traveling in Vienna now and I found ChatGPT to be a fabulous travel companion. I can tap into its knowledge to learn about Austrian history and ask questions about historical figures or moments.




November 21, 2024 at 10:54 AM
I’m traveling in Vienna now and I found ChatGPT to be a fabulous travel companion. I can tap into its knowledge to learn about Austrian history and ask questions about historical figures or moments.
I gave a presentation at the Ray Summit on my work building Multimodal Foundation Models for Document Automation at Uber. It is always a great pleasure to publicly share what I have been building over the past year!
www.ivanzhou.me/blog/2024/11...
www.ivanzhou.me/blog/2024/11...

My Ray Summit Talk - Building Multi-Modal Foundation Models for Document Automation — Ivan Zhou
I gave a presentation at the Ray Summit on my work building Multimodal Foundation Models for Document Automation at Uber. Over the past year, my team at Uber have invested in pretraining foundation mo...
www.ivanzhou.me
November 20, 2024 at 5:07 PM
I gave a presentation at the Ray Summit on my work building Multimodal Foundation Models for Document Automation at Uber. It is always a great pleasure to publicly share what I have been building over the past year!
www.ivanzhou.me/blog/2024/11...
www.ivanzhou.me/blog/2024/11...