




Jay Patel
@infotainment.bsky.social
🎷 vibe adulting
#HCI #PeerReview #SciPub
#toolsforthought #ResearchSynthesis
#OpenScience #MetaSci #FoSci
🔎 Research: ethnography of peer review
🧑🏫 Teaching: Stats, DataViz
🐢 UMD: College of Info
🌐 PhD Candidate: Info Studies / HCI + Data
🏝️ OASISlab
#HCI #PeerReview #SciPub
#toolsforthought #ResearchSynthesis
#OpenScience #MetaSci #FoSci
🔎 Research: ethnography of peer review
🧑🏫 Teaching: Stats, DataViz
🐢 UMD: College of Info
🌐 PhD Candidate: Info Studies / HCI + Data
🏝️ OASISlab
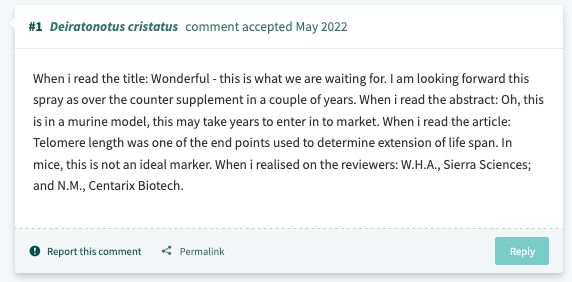
Hands down, the best PubPeer comment I've read in a while.
November 10, 2025 at 11:12 PM
Hands down, the best PubPeer comment I've read in a while.
While reading a data science conference paper today, I noticed an interesting transparency statement.
Is this common to data mining conferences?
I like this sort of statement; it reminds me a bit of the 21-word solution. #metascience
Is this common to data mining conferences?
I like this sort of statement; it reminds me a bit of the 21-word solution. #metascience

November 7, 2025 at 2:47 AM
While reading a data science conference paper today, I noticed an interesting transparency statement.
Is this common to data mining conferences?
I like this sort of statement; it reminds me a bit of the 21-word solution. #metascience
Is this common to data mining conferences?
I like this sort of statement; it reminds me a bit of the 21-word solution. #metascience
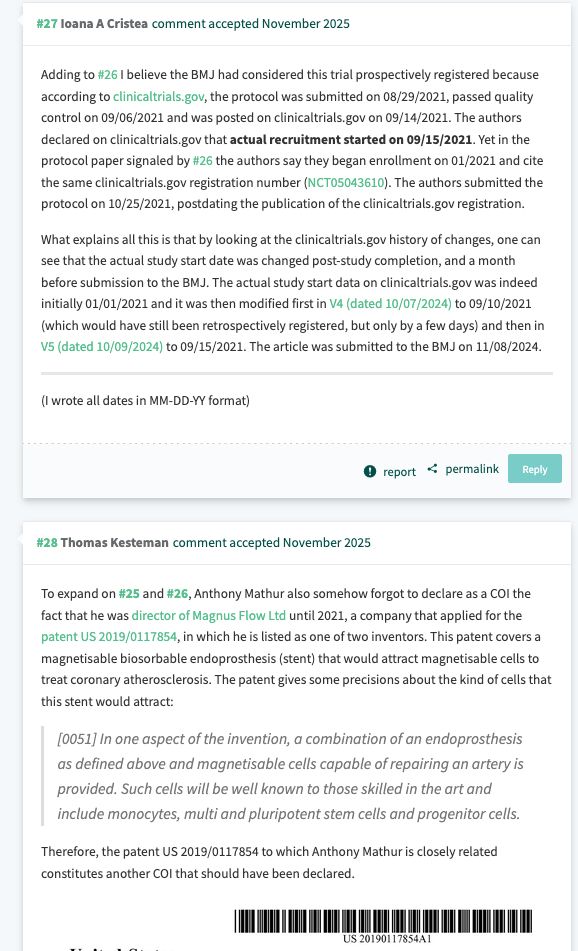
And just over the past day or so, even more commentary point to conflict of interest issues (didn't declare a key patent) and issues with changing the clinical trial registration dates to make it seem as if the data were collected after declaring the study plan/registration.
November 5, 2025 at 9:55 PM
And just over the past day or so, even more commentary point to conflict of interest issues (didn't declare a key patent) and issues with changing the clinical trial registration dates to make it seem as if the data were collected after declaring the study plan/registration.
Hey, @gracewade.bsky.social why is this article continuously posted on BSky? The number of issues documented by academic researchers is worth reporting.
The story should be one of errors/potential fraud instead of a breakthrough, right?
pubpeer.com/publications...
Author reply in the thread:
The story should be one of errors/potential fraud instead of a breakthrough, right?
pubpeer.com/publications...
Author reply in the thread:

November 5, 2025 at 9:19 PM
Hey, @gracewade.bsky.social why is this article continuously posted on BSky? The number of issues documented by academic researchers is worth reporting.
The story should be one of errors/potential fraud instead of a breakthrough, right?
pubpeer.com/publications...
Author reply in the thread:
The story should be one of errors/potential fraud instead of a breakthrough, right?
pubpeer.com/publications...
Author reply in the thread:
So how did you prompt it then? Typically, prompts starting with "You are an expert X with expertise in domains A,B, and C..." is effective.
The Google white paper that was published a while ago can be helpful: cloud.google.com/discover/wha...
Section: Strategies for writing better prompts
The Google white paper that was published a while ago can be helpful: cloud.google.com/discover/wha...
Section: Strategies for writing better prompts

November 4, 2025 at 8:22 PM
So how did you prompt it then? Typically, prompts starting with "You are an expert X with expertise in domains A,B, and C..." is effective.
The Google white paper that was published a while ago can be helpful: cloud.google.com/discover/wha...
Section: Strategies for writing better prompts
The Google white paper that was published a while ago can be helpful: cloud.google.com/discover/wha...
Section: Strategies for writing better prompts
I did both in my master's thesis under supervision by a mentor. What are the stats on reporting this? Would be nice to know.
apastyle.apa.org/jars/quant-t...
APA JARS-QUANT reporting guidelines mention diagnostics:
apastyle.apa.org/jars/quant-t...
APA JARS-QUANT reporting guidelines mention diagnostics:

November 4, 2025 at 7:25 PM
I did both in my master's thesis under supervision by a mentor. What are the stats on reporting this? Would be nice to know.
apastyle.apa.org/jars/quant-t...
APA JARS-QUANT reporting guidelines mention diagnostics:
apastyle.apa.org/jars/quant-t...
APA JARS-QUANT reporting guidelines mention diagnostics:
Dear Reviewer 2: Go F’ Yourself.
Another gem in the #peerreview literature, a joke paper, finds that it's Reviewer #3 who's the real problem.
The paper even has a credulous PubPeer comment!
Paper: doi:10.1111/ssqu.12824s
PubPeer: pubpeer.com/publications/80F9ACFE1DC2E6510A4CC3D2D841C1
Another gem in the #peerreview literature, a joke paper, finds that it's Reviewer #3 who's the real problem.
The paper even has a credulous PubPeer comment!
Paper: doi:10.1111/ssqu.12824s
PubPeer: pubpeer.com/publications/80F9ACFE1DC2E6510A4CC3D2D841C1

October 17, 2025 at 11:58 PM
Dear Reviewer 2: Go F’ Yourself.
Another gem in the #peerreview literature, a joke paper, finds that it's Reviewer #3 who's the real problem.
The paper even has a credulous PubPeer comment!
Paper: doi:10.1111/ssqu.12824s
PubPeer: pubpeer.com/publications/80F9ACFE1DC2E6510A4CC3D2D841C1
Another gem in the #peerreview literature, a joke paper, finds that it's Reviewer #3 who's the real problem.
The paper even has a credulous PubPeer comment!
Paper: doi:10.1111/ssqu.12824s
PubPeer: pubpeer.com/publications/80F9ACFE1DC2E6510A4CC3D2D841C1
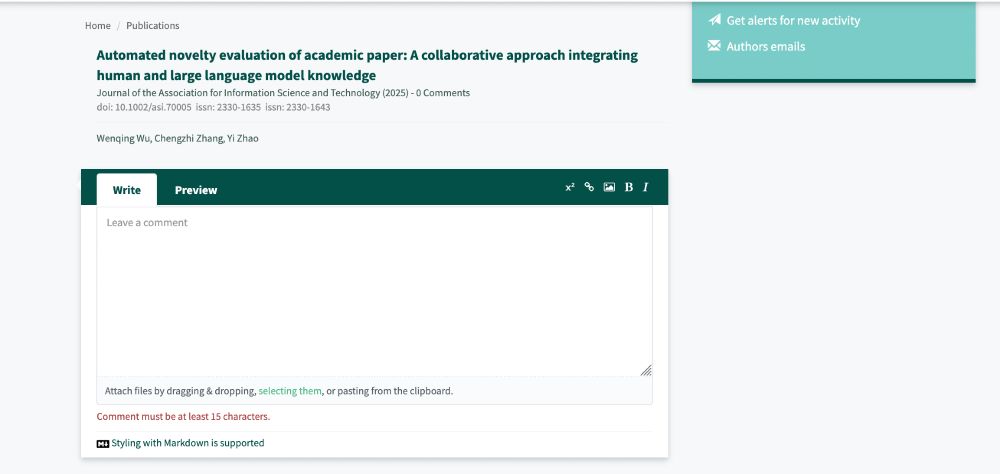
Yes! Left is a blank PubPeer page where I submitted a comment (awaiting moderation, then never accepted). Right is Paperstars with the same comment.

October 1, 2025 at 5:30 PM
Yes! Left is a blank PubPeer page where I submitted a comment (awaiting moderation, then never accepted). Right is Paperstars with the same comment.
But did you get a photo?

September 4, 2025 at 6:07 PM
But did you get a photo?

August 17, 2025 at 7:29 PM
Fourth find: Disclaimers abound. Might as well place them in reporting guidelines for standard communication given how popular they are.

August 15, 2025 at 1:16 AM
Fourth find: Disclaimers abound. Might as well place them in reporting guidelines for standard communication given how popular they are.
Round 3, folks! This time in red text at the bottom of the first page.

August 14, 2025 at 1:27 AM
Round 3, folks! This time in red text at the bottom of the first page.
Yes, the first screenshot is about OpenReviewer. I read that paper recently and was able to run the HuggingFace demo: huggingface.co/spaces/maxid...
Maybe try again?
The second screenshot is Liang et al. 2024: ai.nejm.org/doi/abs/10.1...
Maybe try again?
The second screenshot is Liang et al. 2024: ai.nejm.org/doi/abs/10.1...

August 13, 2025 at 9:46 PM
Yes, the first screenshot is about OpenReviewer. I read that paper recently and was able to run the HuggingFace demo: huggingface.co/spaces/maxid...
Maybe try again?
The second screenshot is Liang et al. 2024: ai.nejm.org/doi/abs/10.1...
Maybe try again?
The second screenshot is Liang et al. 2024: ai.nejm.org/doi/abs/10.1...
BINGO! I call BINGO! How many variants can I find?

August 13, 2025 at 3:48 AM
BINGO! I call BINGO! How many variants can I find?
"Can Large Language Models" returns 8k+ hits on Google Scholar.
"Should Large Language Models" returns 73 hits.
Before asking can...?, ask should...? and you'll save yourself a year's worth of research in some cases.
"Should Large Language Models" returns 73 hits.
Before asking can...?, ask should...? and you'll save yourself a year's worth of research in some cases.


August 13, 2025 at 2:25 AM
"Can Large Language Models" returns 8k+ hits on Google Scholar.
"Should Large Language Models" returns 73 hits.
Before asking can...?, ask should...? and you'll save yourself a year's worth of research in some cases.
"Should Large Language Models" returns 73 hits.
Before asking can...?, ask should...? and you'll save yourself a year's worth of research in some cases.
AI researchers love to add disclaimers about the importance of humans in research activities, but I don't see much use for this kind of thing in practice.
Those who use their tools will do so as they like.
Disclaimers won't matter much in the long-run.
Those who use their tools will do so as they like.
Disclaimers won't matter much in the long-run.

August 12, 2025 at 9:05 PM
AI researchers love to add disclaimers about the importance of humans in research activities, but I don't see much use for this kind of thing in practice.
Those who use their tools will do so as they like.
Disclaimers won't matter much in the long-run.
Those who use their tools will do so as they like.
Disclaimers won't matter much in the long-run.
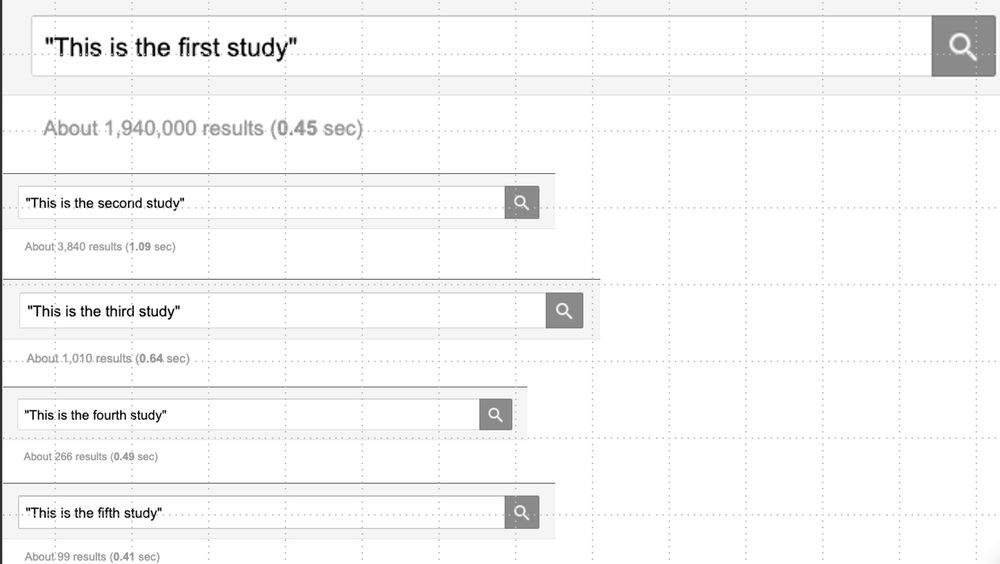
"This is the first study..." in a paper makes me fume. 😤
On Google Scholar, it returns almost 2 million hits.
"This is the second study..." returns 3,840 hits.
That's a difference of ~520X.
I'm more likely to believe the latter claim.
📖 If you make a novelty claim, then back it up.
On Google Scholar, it returns almost 2 million hits.
"This is the second study..." returns 3,840 hits.
That's a difference of ~520X.
I'm more likely to believe the latter claim.
📖 If you make a novelty claim, then back it up.
July 29, 2025 at 11:44 PM
"This is the first study..." in a paper makes me fume. 😤
On Google Scholar, it returns almost 2 million hits.
"This is the second study..." returns 3,840 hits.
That's a difference of ~520X.
I'm more likely to believe the latter claim.
📖 If you make a novelty claim, then back it up.
On Google Scholar, it returns almost 2 million hits.
"This is the second study..." returns 3,840 hits.
That's a difference of ~520X.
I'm more likely to believe the latter claim.
📖 If you make a novelty claim, then back it up.
This is how you enforce reporting guidelines: @neuripsconf.bsky.social does it right.
❌ Desk reject failure to comply
Which other venues do this sort of thing? #metascience
❌ Desk reject failure to comply
Which other venues do this sort of thing? #metascience

July 29, 2025 at 12:50 AM
This is how you enforce reporting guidelines: @neuripsconf.bsky.social does it right.
❌ Desk reject failure to comply
Which other venues do this sort of thing? #metascience
❌ Desk reject failure to comply
Which other venues do this sort of thing? #metascience
My new favorite motto and insignia for slow and open (aka slowpen) science:
"Festina lente"
(Latin translation: Make haste slowly)
"Festina lente"
(Latin translation: Make haste slowly)

July 23, 2025 at 5:58 PM
My new favorite motto and insignia for slow and open (aka slowpen) science:
"Festina lente"
(Latin translation: Make haste slowly)
"Festina lente"
(Latin translation: Make haste slowly)
If you want to run a study on LLMs' abilities, please prompt engineer thoroughly.
This is the laziest and most honest method I've seen in my review so far:
"Whether this could have influenced the results remains currently unknown... Prompt designing is also time-consuming..."
This is the laziest and most honest method I've seen in my review so far:
"Whether this could have influenced the results remains currently unknown... Prompt designing is also time-consuming..."

July 22, 2025 at 12:04 AM
If you want to run a study on LLMs' abilities, please prompt engineer thoroughly.
This is the laziest and most honest method I've seen in my review so far:
"Whether this could have influenced the results remains currently unknown... Prompt designing is also time-consuming..."
This is the laziest and most honest method I've seen in my review so far:
"Whether this could have influenced the results remains currently unknown... Prompt designing is also time-consuming..."
3. Sorting and filtering by sentiment would be nice on the X/Bluesky pages.

July 11, 2025 at 10:13 PM
3. Sorting and filtering by sentiment would be nice on the X/Bluesky pages.
2. The colored squares indicating sentiment for the X and Bluesky tabs could be more prominent. I missed them for the first minute or two on the page.

July 11, 2025 at 10:13 PM
2. The colored squares indicating sentiment for the X and Bluesky tabs could be more prominent. I missed them for the first minute or two on the page.
@altmetric.com The sentiment analysis feature is wonderful for researchers.
A few thoughts from my recent use to consider:
1. Can I view a feed of papers/posts by sentiment category (e.g. only papers with post > 10% negative)? That'd be useful to find problematic papers.
A few thoughts from my recent use to consider:
1. Can I view a feed of papers/posts by sentiment category (e.g. only papers with post > 10% negative)? That'd be useful to find problematic papers.

July 11, 2025 at 10:13 PM
@altmetric.com The sentiment analysis feature is wonderful for researchers.
A few thoughts from my recent use to consider:
1. Can I view a feed of papers/posts by sentiment category (e.g. only papers with post > 10% negative)? That'd be useful to find problematic papers.
A few thoughts from my recent use to consider:
1. Can I view a feed of papers/posts by sentiment category (e.g. only papers with post > 10% negative)? That'd be useful to find problematic papers.
Who watches the AI agent benchmarks?
❌ 7/10 contain shortcuts or impossible tasks.
❌ 7/10 fail outcome validity.
❌ 8/10 fail to disclose known issues.
preprint: arxiv.org/abs/2507.02825
blog: ddkang.substack.com/p/ai-agent-b...
❌ 7/10 contain shortcuts or impossible tasks.
❌ 7/10 fail outcome validity.
❌ 8/10 fail to disclose known issues.
preprint: arxiv.org/abs/2507.02825
blog: ddkang.substack.com/p/ai-agent-b...

July 11, 2025 at 9:18 PM
Who watches the AI agent benchmarks?
❌ 7/10 contain shortcuts or impossible tasks.
❌ 7/10 fail outcome validity.
❌ 8/10 fail to disclose known issues.
preprint: arxiv.org/abs/2507.02825
blog: ddkang.substack.com/p/ai-agent-b...
❌ 7/10 contain shortcuts or impossible tasks.
❌ 7/10 fail outcome validity.
❌ 8/10 fail to disclose known issues.
preprint: arxiv.org/abs/2507.02825
blog: ddkang.substack.com/p/ai-agent-b...
July 10, 2025 at 10:00 PM