



Iain Cheeseman
@iaincheeseman.bsky.social
Whitehead Institute and Department of Biology, MIT. Lover of cell biology and cell division. Aspiring to do good science and do good.
Reposted by Iain Cheeseman

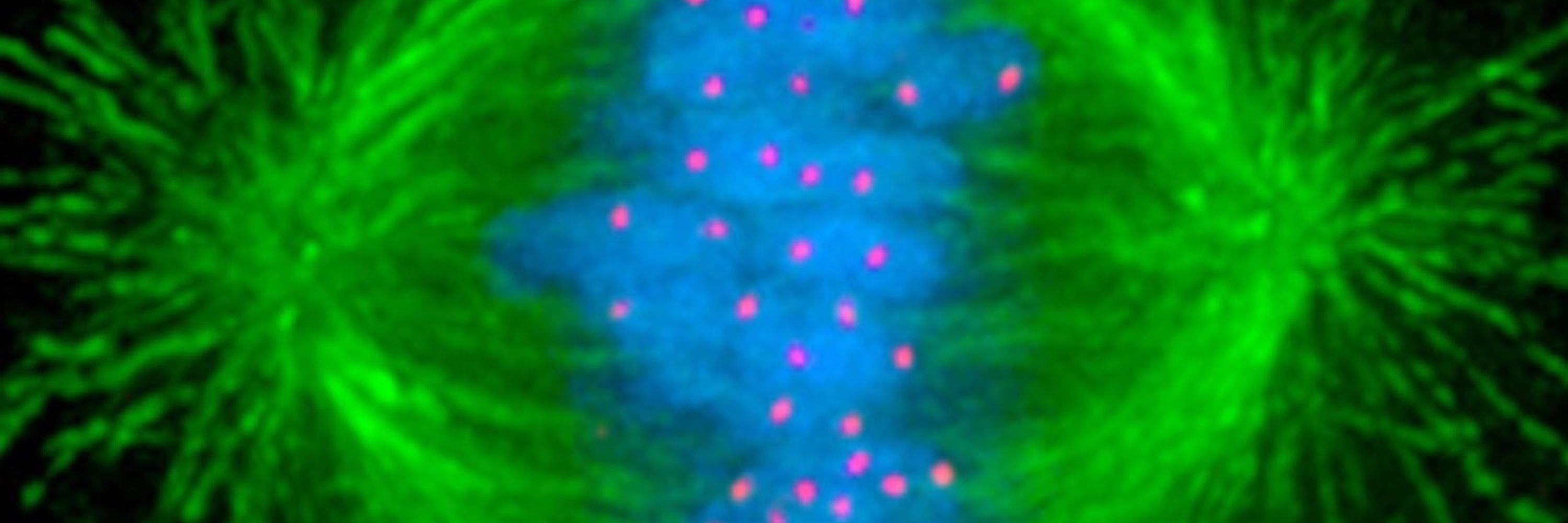
4. A new publication in @natsmb.nature.com from ACS postdoctoral fellow Dr. Eric M. Smith and past ACS grantee Dr. @iaincheeseman.bsky.social at the #WhiteheadInstitute revealing two newly identified, unique subunits of the RNase MRP complex.
Read the paper here: lnkd.in/eTNkJhBW
Read the paper here: lnkd.in/eTNkJhBW
November 7, 2025 at 11:47 PM
4. A new publication in @natsmb.nature.com from ACS postdoctoral fellow Dr. Eric M. Smith and past ACS grantee Dr. @iaincheeseman.bsky.social at the #WhiteheadInstitute revealing two newly identified, unique subunits of the RNase MRP complex.
Read the paper here: lnkd.in/eTNkJhBW
Read the paper here: lnkd.in/eTNkJhBW
Reposted by Iain Cheeseman

This was not the first example of writing to my bosses or other leaders to express my candid views that they were making or were about to make a serious mistake (nor will it be the last).
As a leader, I have also appreciated it when others did the same to (for) me.
/fin
As a leader, I have also appreciated it when others did the same to (for) me.
/fin

elmo from sesame street is standing in front of a wall and saying at least i tell the truth .
ALT: elmo from sesame street is standing in front of a wall and saying at least i tell the truth .
media.tenor.com
October 23, 2025 at 12:55 AM
This was not the first example of writing to my bosses or other leaders to express my candid views that they were making or were about to make a serious mistake (nor will it be the last).
As a leader, I have also appreciated it when others did the same to (for) me.
/fin
As a leader, I have also appreciated it when others did the same to (for) me.
/fin
I believe that this is only possible for open access or PMC deposited papers - a limitation for our world in general. Regardless of this tool, I do hope that the world continues to move to a more open publication environment with a continued plug for preprinting all work.
October 21, 2025 at 12:43 PM
I believe that this is only possible for open access or PMC deposited papers - a limitation for our world in general. Regardless of this tool, I do hope that the world continues to move to a more open publication environment with a continued plug for preprinting all work.
I really value this discussion and dialogue as we all work to consider the impacts (good and bad) of these new capabilities. One minor clarification. The new PubMed integration is not for training data. Instead, it is essentially a tool that gives Claude the ability to search PubMed and access info.
October 21, 2025 at 12:10 PM
I really value this discussion and dialogue as we all work to consider the impacts (good and bad) of these new capabilities. One minor clarification. The new PubMed integration is not for training data. Instead, it is essentially a tool that gives Claude the ability to search PubMed and access info.
It was actually my deep frustration with GO terms and their limitations that caused us to move in this direction. We were inspired by this work from Ideker/Pratt. Ultimately, these are starting points for us to help guide choices for downstream experiments.
www.nature.com/articles/s41...
www.nature.com/articles/s41...

Evaluation of large language models for discovery of gene set function - Nature Methods
Large language models show potential in suggesting common functions for a gene set.
www.nature.com
October 21, 2025 at 11:51 AM
It was actually my deep frustration with GO terms and their limitations that caused us to move in this direction. We were inspired by this work from Ideker/Pratt. Ultimately, these are starting points for us to help guide choices for downstream experiments.
www.nature.com/articles/s41...
www.nature.com/articles/s41...
For me, the most critical use case has been our large-scale cell biology screens. Data on 5k genes. 250 clusters that group functionally related proteins (novel players, new connections). But which do we pursue? Easy for me for mitosis, but it takes me hours to decide for Golgi function, etc
October 21, 2025 at 11:16 AM
For me, the most critical use case has been our large-scale cell biology screens. Data on 5k genes. 250 clusters that group functionally related proteins (novel players, new connections). But which do we pursue? Easy for me for mitosis, but it takes me hours to decide for Golgi function, etc
I regularly read ~20 journals, review ~24 papers/year, search PubMed/bioRxiv/Google Scholar daily, check Bsky, etc. I still miss lots of things - increasingly true as we move into new research areas. AI is just a tool, but it speeds this search and points me to papers/findings I didn't see otherwise
October 21, 2025 at 11:02 AM
I regularly read ~20 journals, review ~24 papers/year, search PubMed/bioRxiv/Google Scholar daily, check Bsky, etc. I still miss lots of things - increasingly true as we move into new research areas. AI is just a tool, but it speeds this search and points me to papers/findings I didn't see otherwise
To clarify, this is not a default setting. You have to enable this functionality. See the last post in the thread.
October 21, 2025 at 12:04 AM
To clarify, this is not a default setting. You have to enable this functionality. See the last post in the thread.
Reposted by Iain Cheeseman

To be honest, just use Perplexity.ai - faster, mostly accurate citations, and it uses the "best" model for the task (or tries to). I still stand by cross-validation using multiple LLMs if you are going down this road. In the end, expert knowledge of the user is the best filter...

a man in a suit and tie is sitting in front of a window .
ALT: a man in a suit and tie is sitting in front of a window .
media.tenor.com
October 20, 2025 at 7:02 PM
To be honest, just use Perplexity.ai - faster, mostly accurate citations, and it uses the "best" model for the task (or tries to). I still stand by cross-validation using multiple LLMs if you are going down this road. In the end, expert knowledge of the user is the best filter...
For full text, this will definitely only be things that have an open access or PMC version, and I agree that it is a limitation. And of course, part of a larger conversation.
October 20, 2025 at 7:32 PM
For full text, this will definitely only be things that have an open access or PMC version, and I agree that it is a limitation. And of course, part of a larger conversation.
These are my own opinions. I don't have any investments in any AI company, etc. I don't receive any money from them. I did get beta access to the PubMed tool and we have a small "grant" that provides tokens so we can use Claude for a scientific tool we developed. See:
www.biorxiv.org/content/10.1...
www.biorxiv.org/content/10.1...

Brieflow: An Integrated Computational Pipeline for High-Throughput Analysis of Optical Pooled Screening Data
Optical pooled screening (OPS) has emerged as a powerful technique for functional genomics, enabling researchers to link genetic perturbations with complex cellular morphological phenotypes at unprece...
www.biorxiv.org
October 20, 2025 at 6:43 PM
These are my own opinions. I don't have any investments in any AI company, etc. I don't receive any money from them. I did get beta access to the PubMed tool and we have a small "grant" that provides tokens so we can use Claude for a scientific tool we developed. See:
www.biorxiv.org/content/10.1...
www.biorxiv.org/content/10.1...
Curious if you could share an example. I have been trying to test out things and break it, and haven't seen this myself (I always require a PMID or DOI, which I have been able to verify thus far). Thanks!
October 20, 2025 at 6:35 PM
Curious if you could share an example. I have been trying to test out things and break it, and haven't seen this myself (I always require a PMID or DOI, which I have been able to verify thus far). Thanks!
Completely agree! PubMed is an amazing resource, but not one that we should take for granted.
October 20, 2025 at 6:34 PM
Completely agree! PubMed is an amazing resource, but not one that we should take for granted.
I don't believe that this is for training data. Instead, this instructs Claude (and gives it the capabilities) to search PubMed dynamically, returning the latest and up-to-date results, and incorporating these into its analysis of your question. But I agree about the value of supporting PubMed.
October 20, 2025 at 6:25 PM
I don't believe that this is for training data. Instead, this instructs Claude (and gives it the capabilities) to search PubMed dynamically, returning the latest and up-to-date results, and incorporating these into its analysis of your question. But I agree about the value of supporting PubMed.