




Harry Thasarathan
@hthasarathan.bsky.social
PhD student @YorkUniversity @LassondeSchool, I work on computer vision and interpretability.
🌌🛰️🔭Want to explore universal visual features? Check out our interactive demo of concepts learned from our #ICML2025 paper "Universal Sparse Autoencoders: Interpretable Cross-Model Concept Alignment".
Come see our poster at 4pm on Tuesday in East Exhibition hall A-B, E-1208!
Come see our poster at 4pm on Tuesday in East Exhibition hall A-B, E-1208!
July 15, 2025 at 2:36 AM
🌌🛰️🔭Want to explore universal visual features? Check out our interactive demo of concepts learned from our #ICML2025 paper "Universal Sparse Autoencoders: Interpretable Cross-Model Concept Alignment".
Come see our poster at 4pm on Tuesday in East Exhibition hall A-B, E-1208!
Come see our poster at 4pm on Tuesday in East Exhibition hall A-B, E-1208!
Our method reveals model-specific features too: DinoV2 (left) shows specialized geometric concepts (depth, perspective), while SigLIP (right) captures unique text-aware visual concepts.
This opens new paths for understanding model differences!
(7/9)
This opens new paths for understanding model differences!
(7/9)


February 7, 2025 at 3:15 PM
Our method reveals model-specific features too: DinoV2 (left) shows specialized geometric concepts (depth, perspective), while SigLIP (right) captures unique text-aware visual concepts.
This opens new paths for understanding model differences!
(7/9)
This opens new paths for understanding model differences!
(7/9)
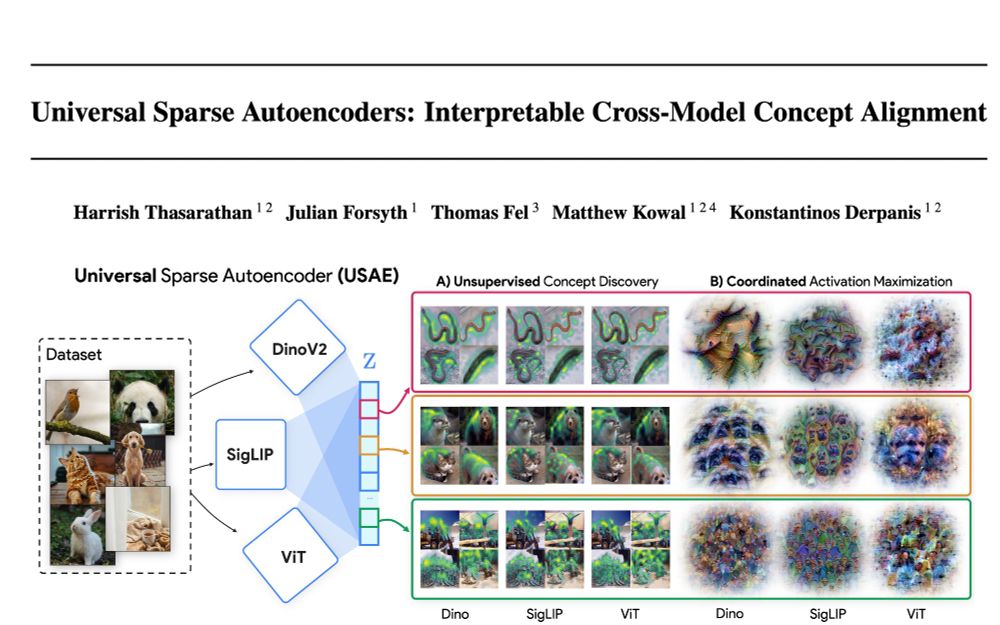
Using coordinated activation maximization on universal concepts, we can visualize how each model independently represents the same concept allowing us to further explore model similarities and differences. Below are concepts visualized for DinoV2, SigLIP, and ViT.
(6/9)
(6/9)


February 7, 2025 at 3:15 PM
Using coordinated activation maximization on universal concepts, we can visualize how each model independently represents the same concept allowing us to further explore model similarities and differences. Below are concepts visualized for DinoV2, SigLIP, and ViT.
(6/9)
(6/9)
Using co-firing and firing entropy metrics, we uncover universal features ranging from basic primitives (colors, textures) to complex abstractions (object interactions, hierarchical compositions). We find that universal concepts are important for reconstructing model activations!
(5/9)
(5/9)

February 7, 2025 at 3:15 PM
Using co-firing and firing entropy metrics, we uncover universal features ranging from basic primitives (colors, textures) to complex abstractions (object interactions, hierarchical compositions). We find that universal concepts are important for reconstructing model activations!
(5/9)
(5/9)
Previous approaches found universal features by post-hoc mining or similarity analysis - but this scales poorly. Our solution: extend Sparse Autoencoders to learn a shared concept space directly, encoding one model's activations and reconstructing all others from this unified vocabulary.
(4/9)
(4/9)

February 7, 2025 at 3:15 PM
Previous approaches found universal features by post-hoc mining or similarity analysis - but this scales poorly. Our solution: extend Sparse Autoencoders to learn a shared concept space directly, encoding one model's activations and reconstructing all others from this unified vocabulary.
(4/9)
(4/9)
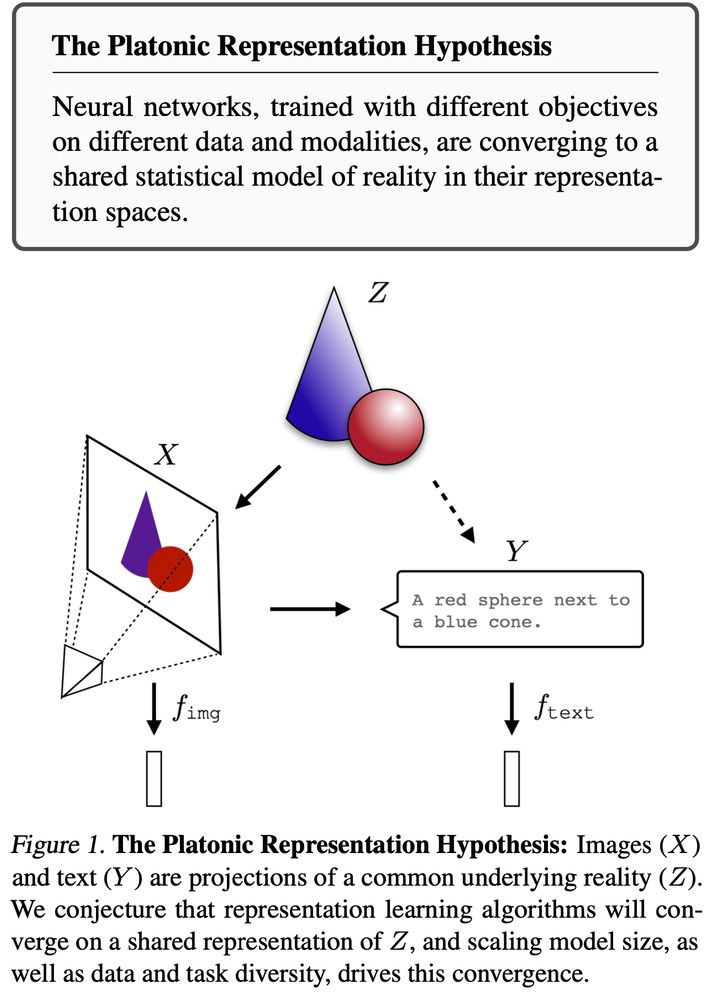
Vision models (backbones & foundation models alike) seem to learn transferable features that are relevant across many tasks. Recent work even suggests we are converging towards the same "Platonic" representation of the world. (Image from arxiv.org/abs/2405.07987)
(2/9)
(2/9)
February 7, 2025 at 3:15 PM
Vision models (backbones & foundation models alike) seem to learn transferable features that are relevant across many tasks. Recent work even suggests we are converging towards the same "Platonic" representation of the world. (Image from arxiv.org/abs/2405.07987)
(2/9)
(2/9)
🌌🛰️🔭Wanna know which features are universal vs unique in your models and how to find them? Excited to share our preprint: "Universal Sparse Autoencoders: Interpretable Cross-Model Concept Alignment"!
arxiv.org/abs/2502.03714
(1/9)
arxiv.org/abs/2502.03714
(1/9)
February 7, 2025 at 3:15 PM
🌌🛰️🔭Wanna know which features are universal vs unique in your models and how to find them? Excited to share our preprint: "Universal Sparse Autoencoders: Interpretable Cross-Model Concept Alignment"!
arxiv.org/abs/2502.03714
(1/9)
arxiv.org/abs/2502.03714
(1/9)