



Hayoung Jung
@hayoungjung.bsky.social
PhD student at @princetoncitp.bsky.social. Previously @uwcse.bsky.social
website: hayoungjung.me
website: hayoungjung.me
I am at #EMNLP2025🇨🇳 to present our main paper *MythTriage: Scalable Detection of Opioid Use Disorder Myths on a Video-Sharing Platform*! Come by to discuss details!
🏦 Location: Hall C
⏲️Time: 11AM-12:30PM
🔗 Paper: aclanthology.org/2025.emnlp-m...
📁 Repo: github.com/hayoungjungg...
🏦 Location: Hall C
⏲️Time: 11AM-12:30PM
🔗 Paper: aclanthology.org/2025.emnlp-m...
📁 Repo: github.com/hayoungjungg...

November 4, 2025 at 6:22 AM
I am at #EMNLP2025🇨🇳 to present our main paper *MythTriage: Scalable Detection of Opioid Use Disorder Myths on a Video-Sharing Platform*! Come by to discuss details!
🏦 Location: Hall C
⏲️Time: 11AM-12:30PM
🔗 Paper: aclanthology.org/2025.emnlp-m...
📁 Repo: github.com/hayoungjungg...
🏦 Location: Hall C
⏲️Time: 11AM-12:30PM
🔗 Paper: aclanthology.org/2025.emnlp-m...
📁 Repo: github.com/hayoungjungg...
📊Finding #3: YouTube’s recommendation continued surfacing myth-supporting content.
➡️12.7% of recs from myth videos led to more myths initially—rising to 22% at deeper levels.
⚠️ Moderation should target these rec pathways that reinforce harmful myths.
➡️12.7% of recs from myth videos led to more myths initially—rising to 22% at deeper levels.
⚠️ Moderation should target these rec pathways that reinforce harmful myths.

September 8, 2025 at 6:13 PM
📊Finding #3: YouTube’s recommendation continued surfacing myth-supporting content.
➡️12.7% of recs from myth videos led to more myths initially—rising to 22% at deeper levels.
⚠️ Moderation should target these rec pathways that reinforce harmful myths.
➡️12.7% of recs from myth videos led to more myths initially—rising to 22% at deeper levels.
⚠️ Moderation should target these rec pathways that reinforce harmful myths.
📊 Finding #2: How you filter your search results matters! Switching from “Relevance” to “Upload Date” or “Rating” increases exposure to myths—echoing the same patterns seen in my COVID-19 misinformation audit: ojs.aaai.org/index.php/IC...
😬A few clicks can change your exposure to myths!
😬A few clicks can change your exposure to myths!

September 8, 2025 at 6:13 PM
📊 Finding #2: How you filter your search results matters! Switching from “Relevance” to “Upload Date” or “Rating” increases exposure to myths—echoing the same patterns seen in my COVID-19 misinformation audit: ojs.aaai.org/index.php/IC...
😬A few clicks can change your exposure to myths!
😬A few clicks can change your exposure to myths!
🫶Thanks to MythTriage, we present the first large-scale study of OUD-related myths on YouTube!
📊 Finding #1: Nearly 20% of YouTube search results support OUD myths, while 30% oppose.
😰Despite more opposing, myth-supporting content is widespread—and risks shaping how people understand treatment.
📊 Finding #1: Nearly 20% of YouTube search results support OUD myths, while 30% oppose.
😰Despite more opposing, myth-supporting content is widespread—and risks shaping how people understand treatment.

September 8, 2025 at 6:13 PM
🫶Thanks to MythTriage, we present the first large-scale study of OUD-related myths on YouTube!
📊 Finding #1: Nearly 20% of YouTube search results support OUD myths, while 30% oppose.
😰Despite more opposing, myth-supporting content is widespread—and risks shaping how people understand treatment.
📊 Finding #1: Nearly 20% of YouTube search results support OUD myths, while 30% oppose.
😰Despite more opposing, myth-supporting content is widespread—and risks shaping how people understand treatment.
⚙️So how does MythTriage perform?
📊 Achieves 0.68-0.86 macro F1 and defers only 5-67% of the examples to the costly LLM.
In practice, MythTriage:
💸 Cuts financial costs by 98% vs experts and by 94% vs LLM labeling
⏱️ Cuts time costs by 96% vs experts & by 76% vs LLM labeling
📊 Achieves 0.68-0.86 macro F1 and defers only 5-67% of the examples to the costly LLM.
In practice, MythTriage:
💸 Cuts financial costs by 98% vs experts and by 94% vs LLM labeling
⏱️ Cuts time costs by 96% vs experts & by 76% vs LLM labeling

September 8, 2025 at 6:13 PM
⚙️So how does MythTriage perform?
📊 Achieves 0.68-0.86 macro F1 and defers only 5-67% of the examples to the costly LLM.
In practice, MythTriage:
💸 Cuts financial costs by 98% vs experts and by 94% vs LLM labeling
⏱️ Cuts time costs by 96% vs experts & by 76% vs LLM labeling
📊 Achieves 0.68-0.86 macro F1 and defers only 5-67% of the examples to the costly LLM.
In practice, MythTriage:
💸 Cuts financial costs by 98% vs experts and by 94% vs LLM labeling
⏱️ Cuts time costs by 96% vs experts & by 76% vs LLM labeling
🚀 Our solution: MythTriage
👉 Uses lightweight DeBERTa for routine cases
👉 Defers harder ones to GPT-4o (high-performing but costly)
The trick? We distilled DeBERTa on GPT-4o’s synthetic labels—achieving strong performance without massive expert-labeled data.
👉 Uses lightweight DeBERTa for routine cases
👉 Defers harder ones to GPT-4o (high-performing but costly)
The trick? We distilled DeBERTa on GPT-4o’s synthetic labels—achieving strong performance without massive expert-labeled data.

September 8, 2025 at 6:13 PM
🚀 Our solution: MythTriage
👉 Uses lightweight DeBERTa for routine cases
👉 Defers harder ones to GPT-4o (high-performing but costly)
The trick? We distilled DeBERTa on GPT-4o’s synthetic labels—achieving strong performance without massive expert-labeled data.
👉 Uses lightweight DeBERTa for routine cases
👉 Defers harder ones to GPT-4o (high-performing but costly)
The trick? We distilled DeBERTa on GPT-4o’s synthetic labels—achieving strong performance without massive expert-labeled data.
🩺 To rigorously detect OUD myths in our datasets, we collaborated closely with clinical experts to:
✅Validate eight pervasive myths on OUD (see examples below!)
✅Create and refine annotation guidelines
✅Build a gold-standard dataset: 310 videos labeled across 8 myths (~2.5K expert labels).
✅Validate eight pervasive myths on OUD (see examples below!)
✅Create and refine annotation guidelines
✅Build a gold-standard dataset: 310 videos labeled across 8 myths (~2.5K expert labels).


September 8, 2025 at 6:13 PM
🩺 To rigorously detect OUD myths in our datasets, we collaborated closely with clinical experts to:
✅Validate eight pervasive myths on OUD (see examples below!)
✅Create and refine annotation guidelines
✅Build a gold-standard dataset: 310 videos labeled across 8 myths (~2.5K expert labels).
✅Validate eight pervasive myths on OUD (see examples below!)
✅Create and refine annotation guidelines
✅Build a gold-standard dataset: 310 videos labeled across 8 myths (~2.5K expert labels).
To measure the scale and prevalence of myths on YouTube, we curated opioid and OUD search queries based on real-world search interests. Using these queries, we built two datasets on YouTube:
1️⃣ OUD Search Dataset: 2.9K search results
2️⃣ OUD Recs Dataset: 343K video recommendations
1️⃣ OUD Search Dataset: 2.9K search results
2️⃣ OUD Recs Dataset: 343K video recommendations

September 8, 2025 at 6:13 PM
To measure the scale and prevalence of myths on YouTube, we curated opioid and OUD search queries based on real-world search interests. Using these queries, we built two datasets on YouTube:
1️⃣ OUD Search Dataset: 2.9K search results
2️⃣ OUD Recs Dataset: 343K video recommendations
1️⃣ OUD Search Dataset: 2.9K search results
2️⃣ OUD Recs Dataset: 343K video recommendations
🚨YouTube is a key source of health info, but it’s also rife with dangerous myths on opioid use disorder (OUD), a leading cause of death in the U.S.
To understand the scale of such misinformation, our #EMNLP2025 paper introduces MythTriage, a scalable system to detect OUD myth🧵
To understand the scale of such misinformation, our #EMNLP2025 paper introduces MythTriage, a scalable system to detect OUD myth🧵

September 8, 2025 at 6:13 PM
🚨YouTube is a key source of health info, but it’s also rife with dangerous myths on opioid use disorder (OUD), a leading cause of death in the U.S.
To understand the scale of such misinformation, our #EMNLP2025 paper introduces MythTriage, a scalable system to detect OUD myth🧵
To understand the scale of such misinformation, our #EMNLP2025 paper introduces MythTriage, a scalable system to detect OUD myth🧵
8/ SA bots encountered significantly more misinformation in the default Relevance filter.
Since most users will likely engage with SERPs in this default settings, users in SA 🇿🇦 face a higher likelihood of misinformation exposure, raising public health risks.
Since most users will likely engage with SERPs in this default settings, users in SA 🇿🇦 face a higher likelihood of misinformation exposure, raising public health risks.

January 16, 2025 at 1:38 AM
8/ SA bots encountered significantly more misinformation in the default Relevance filter.
Since most users will likely engage with SERPs in this default settings, users in SA 🇿🇦 face a higher likelihood of misinformation exposure, raising public health risks.
Since most users will likely engage with SERPs in this default settings, users in SA 🇿🇦 face a higher likelihood of misinformation exposure, raising public health risks.
6/ Alarmingly, two topics—Biological Weapon and Lab Leak Theory—were riddled with misinformation across all search filters. Interestingly, while 3 topics opposed misinfo under the default Relevance filter, switching to filters like Upload Date revealed SERPs packed with misinfo.

January 16, 2025 at 1:36 AM
6/ Alarmingly, two topics—Biological Weapon and Lab Leak Theory—were riddled with misinformation across all search filters. Interestingly, while 3 topics opposed misinfo under the default Relevance filter, switching to filters like Upload Date revealed SERPs packed with misinfo.
5/ The disparity was especially pronounced in topics like:
📡 5G Claims
💉 Vaccine Content Claims
💻 Bill Gates Claims
Effect sizes suggest 🇿🇦 users are at greater risk of encountering misinformative search results than 🇺🇸 users.
📡 5G Claims
💉 Vaccine Content Claims
💻 Bill Gates Claims
Effect sizes suggest 🇿🇦 users are at greater risk of encountering misinformative search results than 🇺🇸 users.
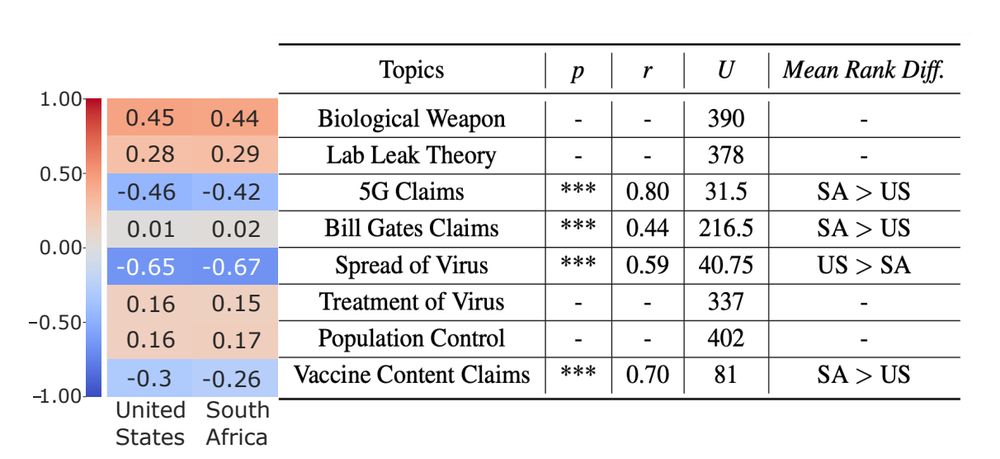
January 16, 2025 at 1:36 AM
5/ The disparity was especially pronounced in topics like:
📡 5G Claims
💉 Vaccine Content Claims
💻 Bill Gates Claims
Effect sizes suggest 🇿🇦 users are at greater risk of encountering misinformative search results than 🇺🇸 users.
📡 5G Claims
💉 Vaccine Content Claims
💻 Bill Gates Claims
Effect sizes suggest 🇿🇦 users are at greater risk of encountering misinformative search results than 🇺🇸 users.
4/ We analyzed misinformation bias scores in search engine result pages (SERPs) across both countries. Higher scores reflect a greater prevalence of misinfo in the SERPs⚠️ Bots in SA faced significantly more misinformation in top-10 results, which account for 95% of user traffic

January 16, 2025 at 1:35 AM
4/ We analyzed misinformation bias scores in search engine result pages (SERPs) across both countries. Higher scores reflect a greater prevalence of misinfo in the SERPs⚠️ Bots in SA faced significantly more misinformation in top-10 results, which account for 95% of user traffic
2/ To fill this gap, we conducted a large-scale geolocation-based audit of YouTube Search, comparing results in the US🇺🇸 and SA🇿🇦—countries heavily impacted by the pandemic in the Global North and South.

January 16, 2025 at 1:35 AM
2/ To fill this gap, we conducted a large-scale geolocation-based audit of YouTube Search, comparing results in the US🇺🇸 and SA🇿🇦—countries heavily impacted by the pandemic in the Global North and South.
How does YouTube’s search algorithm handle COVID🦠 misinfo in the United States🇺🇸(US) and South Africa🇿🇦(SA)?
In our #icwsm '25 paper w/ @prerna6.bsky.social @tanumitra.bsky.social, we found bots in SA received significantly more misinfo in top-10 search results, which accounts for 95% of user traffic
In our #icwsm '25 paper w/ @prerna6.bsky.social @tanumitra.bsky.social, we found bots in SA received significantly more misinfo in top-10 search results, which accounts for 95% of user traffic

January 16, 2025 at 1:34 AM
How does YouTube’s search algorithm handle COVID🦠 misinfo in the United States🇺🇸(US) and South Africa🇿🇦(SA)?
In our #icwsm '25 paper w/ @prerna6.bsky.social @tanumitra.bsky.social, we found bots in SA received significantly more misinfo in top-10 search results, which accounts for 95% of user traffic
In our #icwsm '25 paper w/ @prerna6.bsky.social @tanumitra.bsky.social, we found bots in SA received significantly more misinfo in top-10 search results, which accounts for 95% of user traffic