



Kanishk Gandhi
@gandhikanishk.bsky.social
PhD Student Stanford w/ Noah Goodman, studying reasoning, discovery, and interaction. Trying to build machines that understand people.
StanfordNLP, Stanford AI Lab
StanfordNLP, Stanford AI Lab
13/13 Paper at arxiv.org/abs/2503.01307

Cognitive Behaviors that Enable Self-Improving Reasoners, or, Four Habits of Highly Effective STaRs
Test-time inference has emerged as a powerful paradigm for enabling language models to ``think'' longer and more carefully about complex challenges, much like skilled human experts. While reinforcemen...
arxiv.org
March 4, 2025 at 6:15 PM
13/13 Paper at arxiv.org/abs/2503.01307
12/13 Would also like to thank Charlie Snell, Dimitris Papailiopoulos, Eric Zelikman, Alex Havrilla, Rafael Rafaelov, @upiter.bsky.social and Archit Sharma for discussions about the magic and woes of RL training with LLMs.
March 4, 2025 at 6:15 PM
12/13 Would also like to thank Charlie Snell, Dimitris Papailiopoulos, Eric Zelikman, Alex Havrilla, Rafael Rafaelov, @upiter.bsky.social and Archit Sharma for discussions about the magic and woes of RL training with LLMs.
11/13 Work with amazing collaborators Ayush Chakravarthy, Anikait Singh, Nathan Lile and @noahdgoodman.bsky.social
March 4, 2025 at 6:15 PM
11/13 Work with amazing collaborators Ayush Chakravarthy, Anikait Singh, Nathan Lile and @noahdgoodman.bsky.social
10/13 This paper gives us some clues as to what facilitated self-improvement in the recent generation of LLMs and what kind of data enables it. The key lies in exploration of the right behaviors!
March 4, 2025 at 6:15 PM
10/13 This paper gives us some clues as to what facilitated self-improvement in the recent generation of LLMs and what kind of data enables it. The key lies in exploration of the right behaviors!
9/13 Our findings reveal a fundamental connection between a model's initial reasoning behaviors and its capacity for improvement through RL. Models that explore verification, backtracking, subgoals, and backward chaining are primed for success.
March 4, 2025 at 6:15 PM
9/13 Our findings reveal a fundamental connection between a model's initial reasoning behaviors and its capacity for improvement through RL. Models that explore verification, backtracking, subgoals, and backward chaining are primed for success.
8/13 By curating an extended pretraining set to amplify them, we enable Llama to match Qwen's improvement.

March 4, 2025 at 6:15 PM
8/13 By curating an extended pretraining set to amplify them, we enable Llama to match Qwen's improvement.
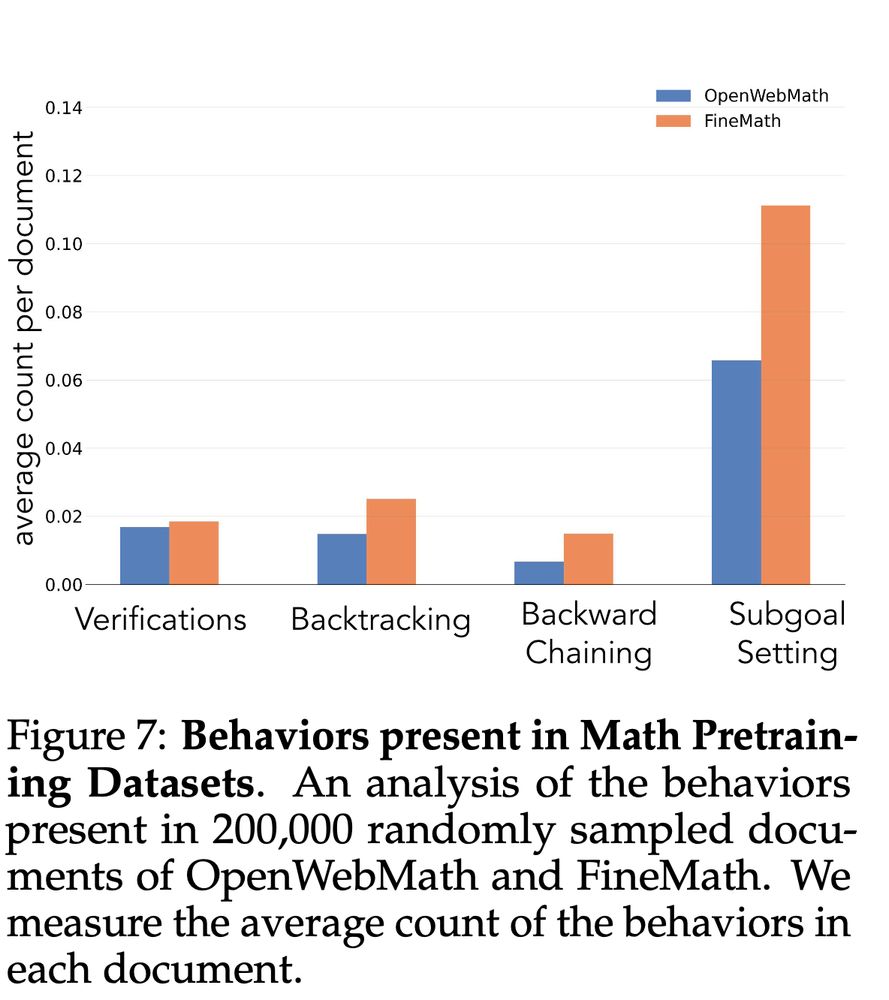
7/13 Can we apply these insights to pretraining? We analyze math pretraining sets like OpenWebMath & FineMath, finding these key behaviors are quite rare.
March 4, 2025 at 6:15 PM
7/13 Can we apply these insights to pretraining? We analyze math pretraining sets like OpenWebMath & FineMath, finding these key behaviors are quite rare.
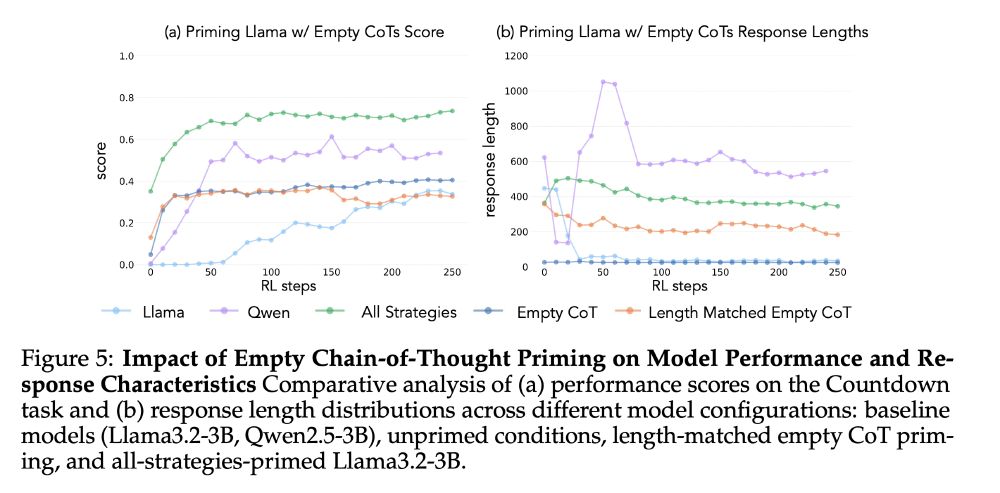
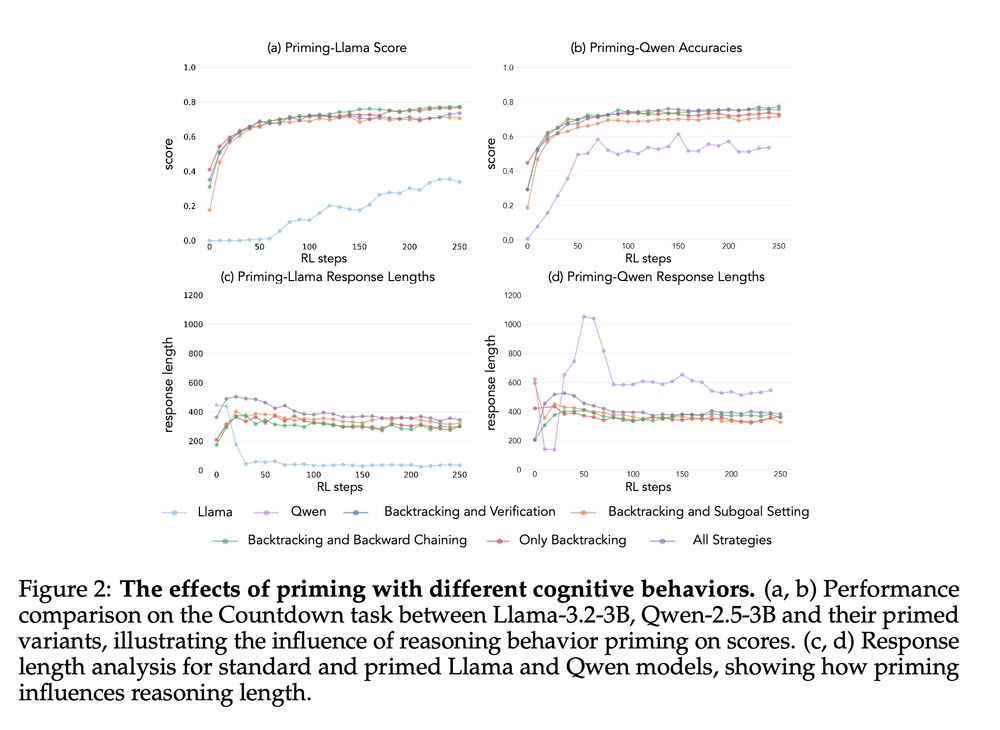
6/13 Empty and length matched empty chain-of-thought priming fails to produce improvement, reverting models to baseline performance. This shows it's the specific cognitive behaviors, not just longer outputs, enabling learning.
March 4, 2025 at 6:15 PM
6/13 Empty and length matched empty chain-of-thought priming fails to produce improvement, reverting models to baseline performance. This shows it's the specific cognitive behaviors, not just longer outputs, enabling learning.
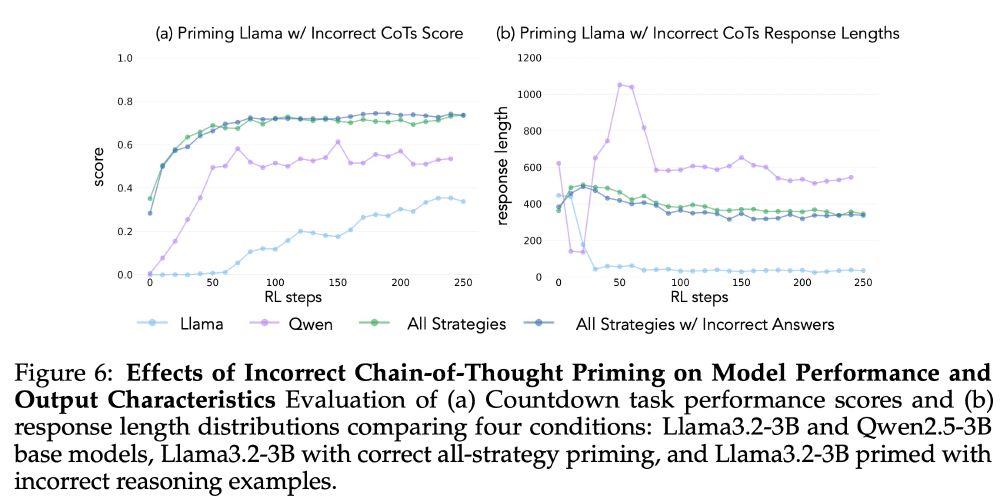
5/13 Crucially, the reasoning patterns matter more than having correct answers. Models primed with incorrect solutions that demonstrate the right cognitive behaviors still show substantial improvement. The behaviors are key.
March 4, 2025 at 6:15 PM
5/13 Crucially, the reasoning patterns matter more than having correct answers. Models primed with incorrect solutions that demonstrate the right cognitive behaviors still show substantial improvement. The behaviors are key.
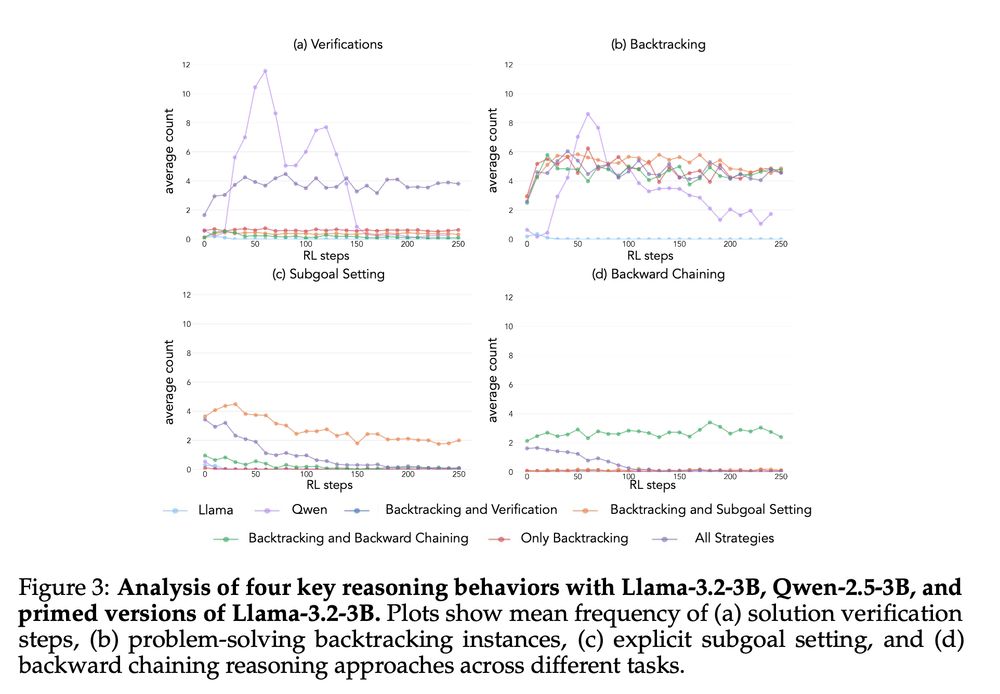
4/13 We curate priming datasets with different behavior combinations and find that models primed with backtracking and verification consistently improve. Interestingly, RL selectively amplifies the most useful behaviors for reaching the goal.
March 4, 2025 at 6:15 PM
4/13 We curate priming datasets with different behavior combinations and find that models primed with backtracking and verification consistently improve. Interestingly, RL selectively amplifies the most useful behaviors for reaching the goal.
3/13 Can we change a model's initial properties to enable improvement? Yes! After "priming" Llama, by finetuning on examples demonstrating these behaviors, it starts improving from RL just like Qwen. The priming jumpstarts the learning process.
March 4, 2025 at 6:15 PM
3/13 Can we change a model's initial properties to enable improvement? Yes! After "priming" Llama, by finetuning on examples demonstrating these behaviors, it starts improving from RL just like Qwen. The priming jumpstarts the learning process.
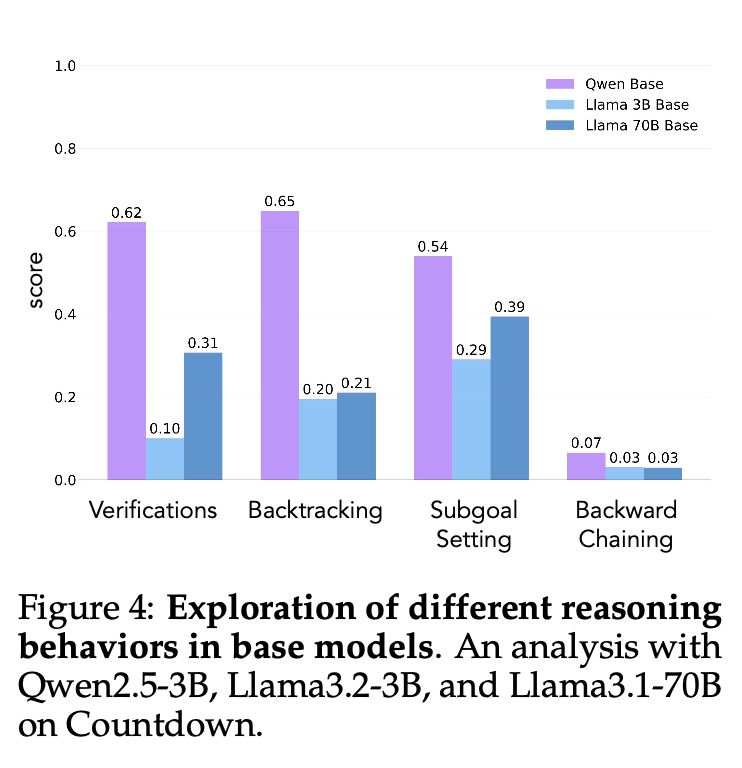
2/13 We identify 4 key cognitive behaviors that enable successful learning: Verification (checking work), Backtracking (trying new approaches), Subgoal Setting (breaking problems down) & Backward Chaining (working backwards from a goal). Qwen naturally exhibits these, while Llama mostly lacks them.
March 4, 2025 at 6:15 PM
2/13 We identify 4 key cognitive behaviors that enable successful learning: Verification (checking work), Backtracking (trying new approaches), Subgoal Setting (breaking problems down) & Backward Chaining (working backwards from a goal). Qwen naturally exhibits these, while Llama mostly lacks them.
These are actually good? No blatant physics violations at least? Definitely better than I expected
December 18, 2024 at 5:53 AM
These are actually good? No blatant physics violations at least? Definitely better than I expected
Actually can you try it with objects that it might have actually seen? Like a blue book falling on a tennis ball? I feel like in abstract prompts like these material properties are underspecified.
December 18, 2024 at 3:08 AM
Actually can you try it with objects that it might have actually seen? Like a blue book falling on a tennis ball? I feel like in abstract prompts like these material properties are underspecified.
Oo can you add me?
November 22, 2024 at 12:52 AM
Oo can you add me?