




Fabian Schaipp
@fschaipp.bsky.social
Researcher in Optimization for ML at Inria Paris. Previously at TU Munich.
https://fabian-sp.github.io/
https://fabian-sp.github.io/
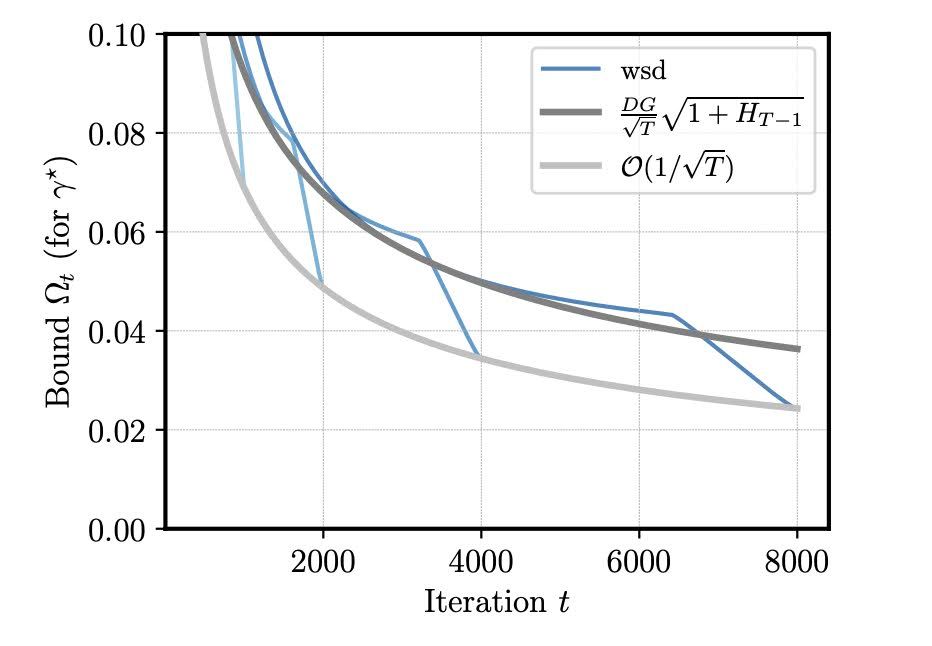
Bonus: this provides a provable explanation for the benefit of cooldown: if we plug in the wsd schedule into the bound, a log-term (H_T+1) vanishes compared to constant LR (dark grey).
February 5, 2025 at 10:13 AM
Bonus: this provides a provable explanation for the benefit of cooldown: if we plug in the wsd schedule into the bound, a log-term (H_T+1) vanishes compared to constant LR (dark grey).
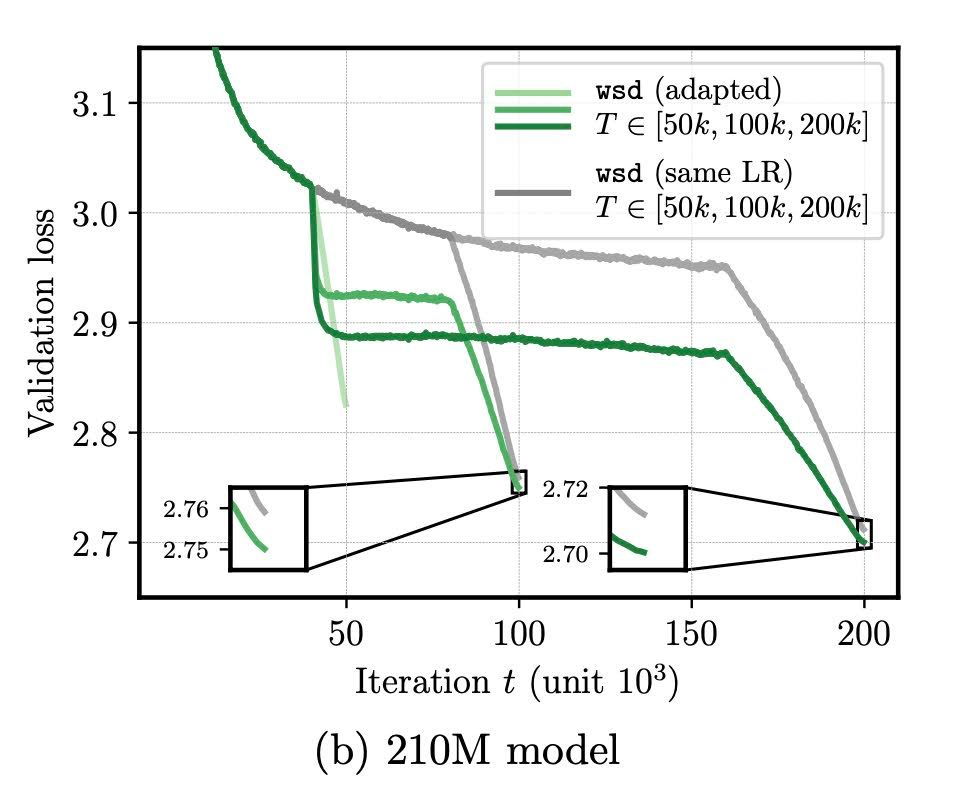
How does this help in practice? In continued training, we need to decrease the learning rate in the second phase. But by how much?
Using the theoretically optimal schedule (which can be computed for free), we obtain noticeable improvement in training 124M and 210M models.
Using the theoretically optimal schedule (which can be computed for free), we obtain noticeable improvement in training 124M and 210M models.
February 5, 2025 at 10:13 AM
How does this help in practice? In continued training, we need to decrease the learning rate in the second phase. But by how much?
Using the theoretically optimal schedule (which can be computed for free), we obtain noticeable improvement in training 124M and 210M models.
Using the theoretically optimal schedule (which can be computed for free), we obtain noticeable improvement in training 124M and 210M models.
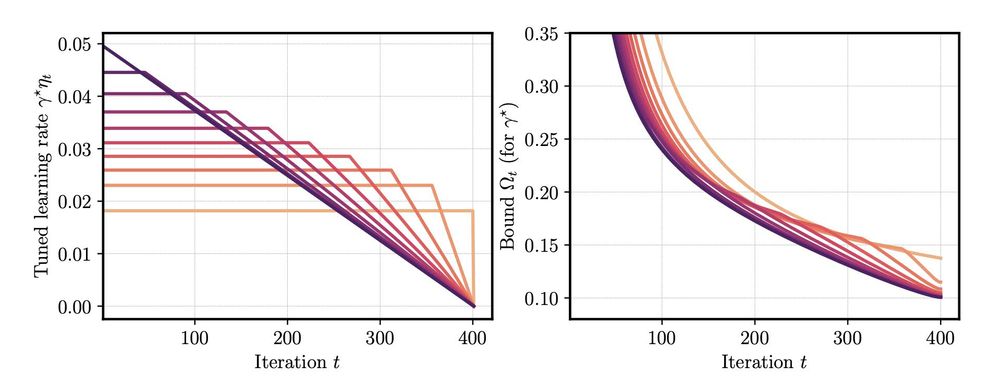
This allows to understand LR schedules beyond experiments: we study (i) optimal cooldown length, (ii) the impact of gradient norm on the schedule performance.
The second part suggests that the sudden drop in loss during cooldown happens when gradient norms do not go to zero.
The second part suggests that the sudden drop in loss during cooldown happens when gradient norms do not go to zero.
February 5, 2025 at 10:13 AM
This allows to understand LR schedules beyond experiments: we study (i) optimal cooldown length, (ii) the impact of gradient norm on the schedule performance.
The second part suggests that the sudden drop in loss during cooldown happens when gradient norms do not go to zero.
The second part suggests that the sudden drop in loss during cooldown happens when gradient norms do not go to zero.
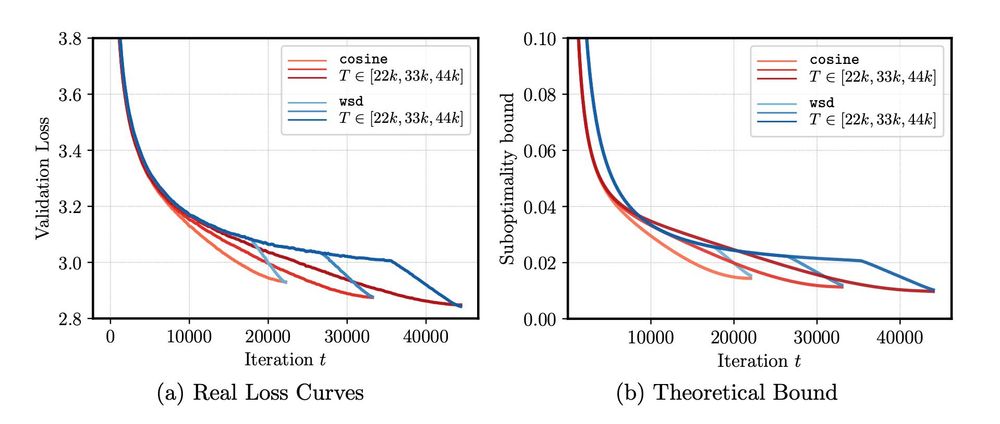
Using a bound from arxiv.org/pdf/2310.07831, we can reproduce the empirical behaviour of cosine and wsd (=constant+cooldown) schedule. Surprisingly the result is for convex problems, but still matches the actual loss of (nonconvex) LLM training.
February 5, 2025 at 10:13 AM
Using a bound from arxiv.org/pdf/2310.07831, we can reproduce the empirical behaviour of cosine and wsd (=constant+cooldown) schedule. Surprisingly the result is for convex problems, but still matches the actual loss of (nonconvex) LLM training.
nice!
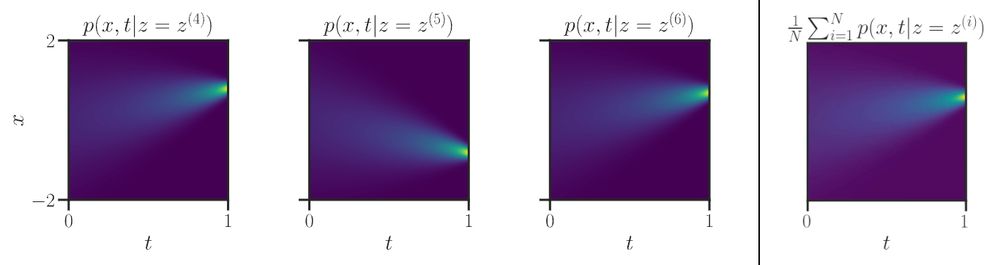
Figure 9 looks like a lighthouse guiding the way (towards the data distribution)
Figure 9 looks like a lighthouse guiding the way (towards the data distribution)
December 13, 2024 at 4:27 PM
nice!
Figure 9 looks like a lighthouse guiding the way (towards the data distribution)
Figure 9 looks like a lighthouse guiding the way (towards the data distribution)