




Explosion 💥
@explosion.ai
We specialize in developer tools & tailored solutions for AI & NLP. Makers of spacy.io and prodi.gy.
🌎 explosion.ai
💼 linkedin.com/company/explosion-ai
🐘 sigmoid.social/@explosion
📺 youtube.com/c/ExplosionAI
🌎 explosion.ai
💼 linkedin.com/company/explosion-ai
🐘 sigmoid.social/@explosion
📺 youtube.com/c/ExplosionAI
🔥 New case study: How GitLab built scalable spaCy pipelines to process a year's worth of support tickets and create actionable insights to better support their community.
explosion.ai/blog/gitlab-...
explosion.ai/blog/gitlab-...

September 16, 2024 at 2:30 PM
🔥 New case study: How GitLab built scalable spaCy pipelines to process a year's worth of support tickets and create actionable insights to better support their community.
explosion.ai/blog/gitlab-...
explosion.ai/blog/gitlab-...
📝 Out now: How S&P Global shipped NLP pipelines for real-time commodities trading insights in a high-security environment with LLMs in the loop.
10× speed-up of their data workflows and up to 99% accuracy at 6mb!
explosion.ai/blog/sp-glob...
10× speed-up of their data workflows and up to 99% accuracy at 6mb!
explosion.ai/blog/sp-glob...

June 21, 2024 at 5:42 PM
📝 Out now: How S&P Global shipped NLP pipelines for real-time commodities trading insights in a high-security environment with LLMs in the loop.
10× speed-up of their data workflows and up to 99% accuracy at 6mb!
explosion.ai/blog/sp-glob...
10× speed-up of their data workflows and up to 99% accuracy at 6mb!
explosion.ai/blog/sp-glob...
Out now: Thinc v9.0! 🔮
This release is the foundation of the upcoming spaCy v4 release and adds support for more powerful learning rates.
We have also merged thinc-apple-ops into Thinc, so Apple AMX is supported out-of-the-box.
Details & release notes: github.com/explosion/th...
This release is the foundation of the upcoming spaCy v4 release and adds support for more powerful learning rates.
We have also merged thinc-apple-ops into Thinc, so Apple AMX is supported out-of-the-box.
Details & release notes: github.com/explosion/th...

April 22, 2024 at 6:12 AM
Out now: Thinc v9.0! 🔮
This release is the foundation of the upcoming spaCy v4 release and adds support for more powerful learning rates.
We have also merged thinc-apple-ops into Thinc, so Apple AMX is supported out-of-the-box.
Details & release notes: github.com/explosion/th...
This release is the foundation of the upcoming spaCy v4 release and adds support for more powerful learning rates.
We have also merged thinc-apple-ops into Thinc, so Apple AMX is supported out-of-the-box.
Details & release notes: github.com/explosion/th...
5️⃣ Error analysis
To maximize ROI from your data engineering, evaluation metrics should be paired with quantitative error analysis. Our latest example error analysis recipe iterates through false positives/negatives and lets you record the reasons to inform your improvement plan.
To maximize ROI from your data engineering, evaluation metrics should be paired with quantitative error analysis. Our latest example error analysis recipe iterates through false positives/negatives and lets you record the reasons to inform your improvement plan.

April 11, 2024 at 11:42 AM
5️⃣ Error analysis
To maximize ROI from your data engineering, evaluation metrics should be paired with quantitative error analysis. Our latest example error analysis recipe iterates through false positives/negatives and lets you record the reasons to inform your improvement plan.
To maximize ROI from your data engineering, evaluation metrics should be paired with quantitative error analysis. Our latest example error analysis recipe iterates through false positives/negatives and lets you record the reasons to inform your improvement plan.
3️⃣ Model training
During the training process, we recommend running Prodigy's train-curve command, which is a great way to quickly see whether more data of similar quality as the current dataset would improve the model.
During the training process, we recommend running Prodigy's train-curve command, which is a great way to quickly see whether more data of similar quality as the current dataset would improve the model.
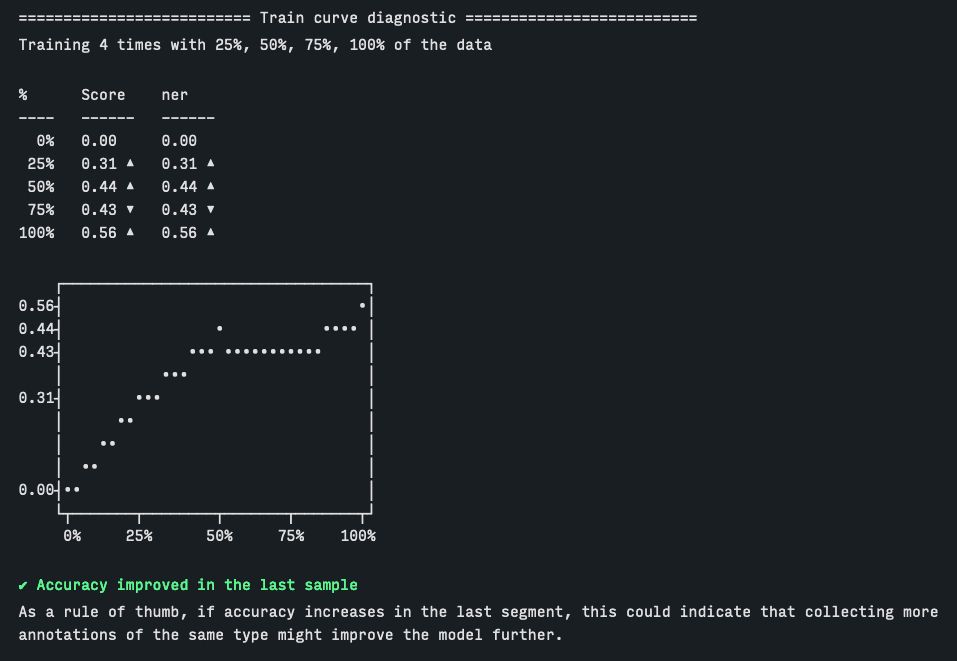
April 11, 2024 at 11:41 AM
3️⃣ Model training
During the training process, we recommend running Prodigy's train-curve command, which is a great way to quickly see whether more data of similar quality as the current dataset would improve the model.
During the training process, we recommend running Prodigy's train-curve command, which is a great way to quickly see whether more data of similar quality as the current dataset would improve the model.
2️⃣ Review
Quantitative measurements of disagreements should always be accompanied by a qualitative analysis. Prodigy's review recipe is an excellent tool for that.
We use it in all our consulting projects to inform and illustrate data model discussions: explosion.ai/tailored-sol...
Quantitative measurements of disagreements should always be accompanied by a qualitative analysis. Prodigy's review recipe is an excellent tool for that.
We use it in all our consulting projects to inform and illustrate data model discussions: explosion.ai/tailored-sol...

April 11, 2024 at 11:41 AM
2️⃣ Review
Quantitative measurements of disagreements should always be accompanied by a qualitative analysis. Prodigy's review recipe is an excellent tool for that.
We use it in all our consulting projects to inform and illustrate data model discussions: explosion.ai/tailored-sol...
Quantitative measurements of disagreements should always be accompanied by a qualitative analysis. Prodigy's review recipe is an excellent tool for that.
We use it in all our consulting projects to inform and illustrate data model discussions: explosion.ai/tailored-sol...
Prodigy provides built-in inter-annotator agreement commands (for tokens and text-level annotations) that you can run directly on your annotated dataset. It also lets you configure custom overlap by specifying the expected number of annotations per example.

April 11, 2024 at 11:41 AM
Prodigy provides built-in inter-annotator agreement commands (for tokens and text-level annotations) that you can run directly on your annotated dataset. It also lets you configure custom overlap by specifying the expected number of annotations per example.
1️⃣ Dataset development
Data development is an iterative process. It’s good practice to test your initial annotation scheme and guidelines during the pilot phase and measure the inter-annotator agreement.
Data development is an iterative process. It’s good practice to test your initial annotation scheme and guidelines during the pilot phase and measure the inter-annotator agreement.

April 11, 2024 at 11:40 AM
1️⃣ Dataset development
Data development is an iterative process. It’s good practice to test your initial annotation scheme and guidelines during the pilot phase and measure the inter-annotator agreement.
Data development is an iterative process. It’s good practice to test your initial annotation scheme and guidelines during the pilot phase and measure the inter-annotator agreement.
New Prodigy plugin: prodigy-evaluate!
📈 confusion matrix and per-label stats
🔎 explore examples your model struggles with most
🍬 entity-level insights for NER with MantisNLP's nervaluate library
github.com/explosion/pr...
📈 confusion matrix and per-label stats
🔎 explore examples your model struggles with most
🍬 entity-level insights for NER with MantisNLP's nervaluate library
github.com/explosion/pr...

March 27, 2024 at 11:46 AM
New Prodigy plugin: prodigy-evaluate!
📈 confusion matrix and per-label stats
🔎 explore examples your model struggles with most
🍬 entity-level insights for NER with MantisNLP's nervaluate library
github.com/explosion/pr...
📈 confusion matrix and per-label stats
🔎 explore examples your model struggles with most
🍬 entity-level insights for NER with MantisNLP's nervaluate library
github.com/explosion/pr...
The SSO plugin is compatible with Prodigy >=1.15.0 and is part of our expanded company license offering, which also includes priority community and email support.

February 19, 2024 at 10:27 AM
The SSO plugin is compatible with Prodigy >=1.15.0 and is part of our expanded company license offering, which also includes priority community and email support.
Some data development and annotation projects need top-notch security.
🔒 Introducing the Prodigy Single Sign-On (SSO) plugin
It's the first in a series of premium Prodigy plugins for company licenses.
🔒 Introducing the Prodigy Single Sign-On (SSO) plugin
It's the first in a series of premium Prodigy plugins for company licenses.
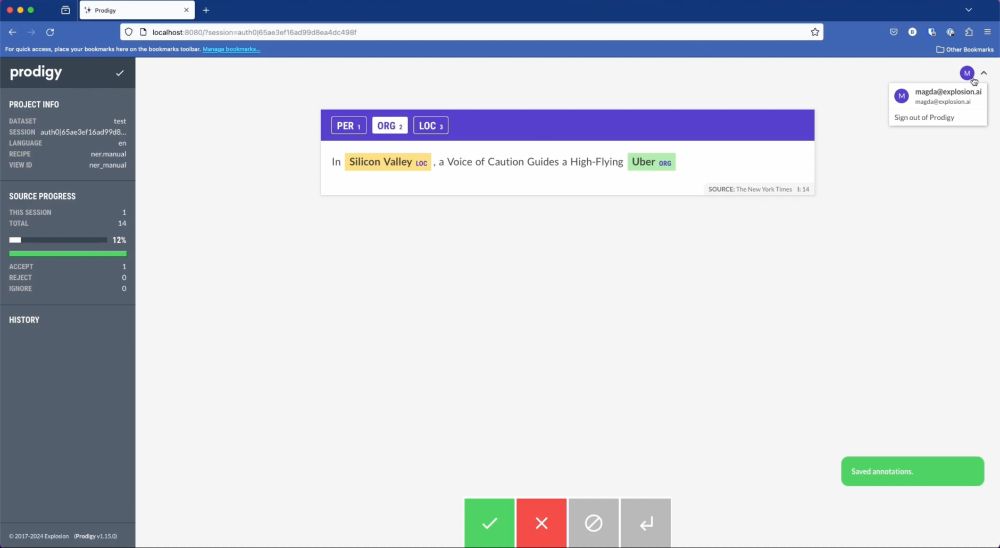
February 19, 2024 at 10:27 AM
Some data development and annotation projects need top-notch security.
🔒 Introducing the Prodigy Single Sign-On (SSO) plugin
It's the first in a series of premium Prodigy plugins for company licenses.
🔒 Introducing the Prodigy Single Sign-On (SSO) plugin
It's the first in a series of premium Prodigy plugins for company licenses.
🗺️ Custom mapping: Instead of using a large skills taxonomy as the NER label scheme, generic skill entities are mapped onto a taxonomy using semantic similarity.
Great work from the Nesta team & thanks to ESCoE for funding!
Great work from the Nesta team & thanks to ESCoE for funding!

February 5, 2024 at 2:21 PM
🗺️ Custom mapping: Instead of using a large skills taxonomy as the NER label scheme, generic skill entities are mapped onto a taxonomy using semantic similarity.
Great work from the Nesta team & thanks to ESCoE for funding!
Great work from the Nesta team & thanks to ESCoE for funding!
✂️ Multiskill splitting: Nesta uses spaCy's dependency parsing to split up multi-skill phrases, like "developing apps and visualizations" into individual skills "developing apps" and "developing visualizations".

February 5, 2024 at 2:20 PM
✂️ Multiskill splitting: Nesta uses spaCy's dependency parsing to split up multi-skill phrases, like "developing apps and visualizations" into individual skills "developing apps" and "developing visualizations".
New case study: How the Nesta data science team extracts skills from millions of online job ads to better understand UK skill demand, using spaCy and Prodigy.
A few project highlights in this thread 🧵✨
explosion.ai/blog/nesta-s...
A few project highlights in this thread 🧵✨
explosion.ai/blog/nesta-s...

February 5, 2024 at 2:20 PM
New case study: How the Nesta data science team extracts skills from millions of online job ads to better understand UK skill demand, using spaCy and Prodigy.
A few project highlights in this thread 🧵✨
explosion.ai/blog/nesta-s...
A few project highlights in this thread 🧵✨
explosion.ai/blog/nesta-s...
The new entity linking functionality lets you to specify a KB and candidate selector. The LLM will then pick the most likely candidate, given the context.
spacy.io/api/large-la...
spacy.io/api/large-la...

January 25, 2024 at 10:32 AM
The new entity linking functionality lets you to specify a KB and candidate selector. The LLM will then pick the most likely candidate, given the context.
spacy.io/api/large-la...
spacy.io/api/large-la...
Out now: spacy-llm v0.7.0!
🔗 Built-in entity linking support
💬 New task for translation from/to arbitrary languages
❓ Use the Doc as prompt for question answering
🧩 Arbitrarily long docs via sharding
github.com/explosion/sp...
🔗 Built-in entity linking support
💬 New task for translation from/to arbitrary languages
❓ Use the Doc as prompt for question answering
🧩 Arbitrarily long docs via sharding
github.com/explosion/sp...

January 25, 2024 at 10:31 AM
Out now: spacy-llm v0.7.0!
🔗 Built-in entity linking support
💬 New task for translation from/to arbitrary languages
❓ Use the Doc as prompt for question answering
🧩 Arbitrarily long docs via sharding
github.com/explosion/sp...
🔗 Built-in entity linking support
💬 New task for translation from/to arbitrary languages
❓ Use the Doc as prompt for question answering
🧩 Arbitrarily long docs via sharding
github.com/explosion/sp...
💌 OUT NOW: The latest edition of our spaCy newsletter featuring our new Merch Store, spaCy 3.7 and spacy-llm 0.6 releases, links to our latest talks, Nesta's Skills Extractor library, and new Prodi.gy blog on 2023 updates! 🚀
Read & sign up: us12.campaign-archive.com?u=83b0498b1e...
Read & sign up: us12.campaign-archive.com?u=83b0498b1e...

November 30, 2023 at 8:45 PM
💌 OUT NOW: The latest edition of our spaCy newsletter featuring our new Merch Store, spaCy 3.7 and spacy-llm 0.6 releases, links to our latest talks, Nesta's Skills Extractor library, and new Prodi.gy blog on 2023 updates! 🚀
Read & sign up: us12.campaign-archive.com?u=83b0498b1e...
Read & sign up: us12.campaign-archive.com?u=83b0498b1e...
Dealing with a huge bucket of images that you want to annotate? The new image retrieval features in Prodigy-ANN might help!
To help explain this new feature, @koaning.bsky.social made a small demo to highlight the new feature 👀
youtu.be/vhbyekSsG8o
To help explain this new feature, @koaning.bsky.social made a small demo to highlight the new feature 👀
youtu.be/vhbyekSsG8o

October 30, 2023 at 9:44 PM
Dealing with a huge bucket of images that you want to annotate? The new image retrieval features in Prodigy-ANN might help!
To help explain this new feature, @koaning.bsky.social made a small demo to highlight the new feature 👀
youtu.be/vhbyekSsG8o
To help explain this new feature, @koaning.bsky.social made a small demo to highlight the new feature 👀
youtu.be/vhbyekSsG8o
🛠️ Improved DX of working with custom CS/JSS by supporting loading from local dirs and remote URLs
Incorporate frameworks like HTMX for a dynamic interface using our latest Custom Events.
prodi.gy/docs/custom-....
Incorporate frameworks like HTMX for a dynamic interface using our latest Custom Events.
prodi.gy/docs/custom-....

October 26, 2023 at 12:50 PM
🛠️ Improved DX of working with custom CS/JSS by supporting loading from local dirs and remote URLs
Incorporate frameworks like HTMX for a dynamic interface using our latest Custom Events.
prodi.gy/docs/custom-....
Incorporate frameworks like HTMX for a dynamic interface using our latest Custom Events.
prodi.gy/docs/custom-....
💥 Prodigy 1.14.5 is out! 💥 We've focused on the front end 💅
prodi.gy/docs/changelog
☑️ A new toggle between token and character-based highlighting to NER and span UI: speedy token-based annotations and precise character highlighting! 🚀
prodi.gy/docs/changelog
☑️ A new toggle between token and character-based highlighting to NER and span UI: speedy token-based annotations and precise character highlighting! 🚀

October 26, 2023 at 12:50 PM
💥 Prodigy 1.14.5 is out! 💥 We've focused on the front end 💅
prodi.gy/docs/changelog
☑️ A new toggle between token and character-based highlighting to NER and span UI: speedy token-based annotations and precise character highlighting! 🚀
prodi.gy/docs/changelog
☑️ A new toggle between token and character-based highlighting to NER and span UI: speedy token-based annotations and precise character highlighting! 🚀
That means that Prodigy now has 5 official plugins! The Prodigy Docs have also been updated to reflect this change.
You can see all the details here:
prodi.gy/docs/plugins
You can see all the details here:
prodi.gy/docs/plugins

October 25, 2023 at 1:53 PM
That means that Prodigy now has 5 official plugins! The Prodigy Docs have also been updated to reflect this change.
You can see all the details here:
prodi.gy/docs/plugins
You can see all the details here:
prodi.gy/docs/plugins
Announcing ✨Prodigy-HF ✨
It's a new plugin that allows you to train @huggingface.bsky.social NER models directly on annotated data in Prodigy. It also provides a recipe to upload annotations to Hugging Face HUB!
It's a new plugin that allows you to train @huggingface.bsky.social NER models directly on annotated data in Prodigy. It also provides a recipe to upload annotations to Hugging Face HUB!

October 25, 2023 at 1:52 PM
Announcing ✨Prodigy-HF ✨
It's a new plugin that allows you to train @huggingface.bsky.social NER models directly on annotated data in Prodigy. It also provides a recipe to upload annotations to Hugging Face HUB!
It's a new plugin that allows you to train @huggingface.bsky.social NER models directly on annotated data in Prodigy. It also provides a recipe to upload annotations to Hugging Face HUB!
For more details on the Prodigy-PDF plugin and other Prodigy plugins, check our docs page: prodi.gy/docs/plugins

October 24, 2023 at 3:08 PM
For more details on the Prodigy-PDF plugin and other Prodigy plugins, check our docs page: prodi.gy/docs/plugins
Want to annotate PDF files with OCR? Our new Prodigy-PDF plugin can help with that!
To help explain how to use PDF segmentation and OCR @koaning.bsky.social made a small demo video to highlight the new feature 👀 www.youtube.com/watch?v=rwyz...
To help explain how to use PDF segmentation and OCR @koaning.bsky.social made a small demo video to highlight the new feature 👀 www.youtube.com/watch?v=rwyz...
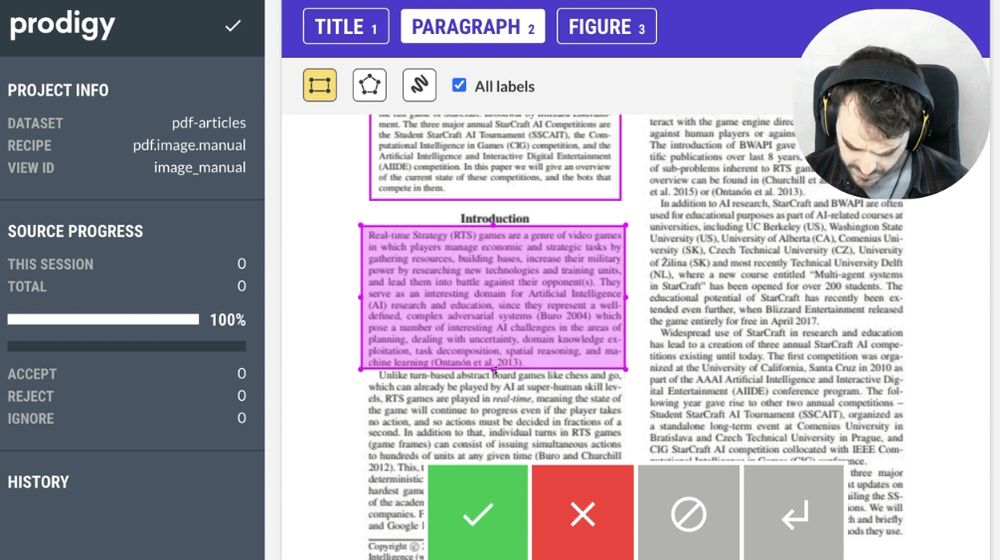
October 24, 2023 at 3:07 PM
Want to annotate PDF files with OCR? Our new Prodigy-PDF plugin can help with that!
To help explain how to use PDF segmentation and OCR @koaning.bsky.social made a small demo video to highlight the new feature 👀 www.youtube.com/watch?v=rwyz...
To help explain how to use PDF segmentation and OCR @koaning.bsky.social made a small demo video to highlight the new feature 👀 www.youtube.com/watch?v=rwyz...
We recently released ✨ Prodigy-ANN ✨ that allows you to use contextual search to find relevant subsets of data to annotate first.
To help explain this new feature, @koaning.bsky.social made a small demo to highlight the new feature 👀
youtu.be/jyu2nbjwfXw
To help explain this new feature, @koaning.bsky.social made a small demo to highlight the new feature 👀
youtu.be/jyu2nbjwfXw


October 20, 2023 at 1:56 PM
We recently released ✨ Prodigy-ANN ✨ that allows you to use contextual search to find relevant subsets of data to annotate first.
To help explain this new feature, @koaning.bsky.social made a small demo to highlight the new feature 👀
youtu.be/jyu2nbjwfXw
To help explain this new feature, @koaning.bsky.social made a small demo to highlight the new feature 👀
youtu.be/jyu2nbjwfXw