




Eivinas Butkus
@eivinas.bsky.social
Cognitive computational neuroscience. Psychology PhD student at Columbia University
eivinasbutkus.github.io
eivinasbutkus.github.io
21/ Poster #2510 (Fri 5 Dec, 4:30-7:30pm PT) at the main conference. Also at the Mechanistic Interpretability Workshop at NeurIPS (Sun 7 Dec). Come chat!
November 18, 2025 at 2:11 AM
21/ Poster #2510 (Fri 5 Dec, 4:30-7:30pm PT) at the main conference. Also at the Mechanistic Interpretability Workshop at NeurIPS (Sun 7 Dec). Come chat!
20/ Thanks to the reviewers and the NeurIPS 2025 community. Thanks also to @zfjoshying, Yushu Pan, @eliasbareinboim (and the CausalAI Lab at Columbia University) for helpful feedback on this work.
November 18, 2025 at 2:11 AM
20/ Thanks to the reviewers and the NeurIPS 2025 community. Thanks also to @zfjoshying, Yushu Pan, @eliasbareinboim (and the CausalAI Lab at Columbia University) for helpful feedback on this work.
19/ Open questions: Do these findings extend to real-world LLMs, more complex causal structures? Could video models like Sora be learning physics simulators internally? We’re excited to explore this in future work.
November 18, 2025 at 2:11 AM
19/ Open questions: Do these findings extend to real-world LLMs, more complex causal structures? Could video models like Sora be learning physics simulators internally? We’re excited to explore this in future work.
18/ Limitations: This is an existence proof in a constrained setting (linear Gaussian SCMs, artificial language). Let us know if you have ideas on how to test this in real LLMs. What may we be missing?
November 18, 2025 at 2:11 AM
18/ Limitations: This is an existence proof in a constrained setting (linear Gaussian SCMs, artificial language). Let us know if you have ideas on how to test this in real LLMs. What may we be missing?
17/ Broader implications: Even when trained using “statistical” prediction, neural networks can develop sophisticated internal machinery (compositional, symbolic structures) that support genuine causal models and reasoning. The “causal parrot” framing may be too limited.
November 18, 2025 at 2:11 AM
17/ Broader implications: Even when trained using “statistical” prediction, neural networks can develop sophisticated internal machinery (compositional, symbolic structures) that support genuine causal models and reasoning. The “causal parrot” framing may be too limited.
16/ Three lines of evidence that the model possesses genuine causal models: (1) it generalizes to novel structure-query combinations, (2) it learns decodable causal representations, and (3) representations can be causally manipulated with predictable effects.
November 18, 2025 at 2:11 AM
16/ Three lines of evidence that the model possesses genuine causal models: (1) it generalizes to novel structure-query combinations, (2) it learns decodable causal representations, and (3) representations can be causally manipulated with predictable effects.
15/ Result 3 (continued): When we intervene on layer activations to change weight w_12 from 0 → 1, the model's predictions flip to match the modified causal structure. This suggests we’re decoding the actual underlying representation the model uses. (See paper for more quantitative results.)

November 18, 2025 at 2:11 AM
15/ Result 3 (continued): When we intervene on layer activations to change weight w_12 from 0 → 1, the model's predictions flip to match the modified causal structure. This suggests we’re decoding the actual underlying representation the model uses. (See paper for more quantitative results.)
14/ Result 3: We can manipulate the model's internal causal representation mid-computation using gradient descent (following the technique from Li et al. 2023). Changing the SCM weights using the probe produces predictable changes in the network’s outputs.

November 18, 2025 at 2:11 AM
14/ Result 3: We can manipulate the model's internal causal representation mid-computation using gradient descent (following the technique from Li et al. 2023). Changing the SCM weights using the probe produces predictable changes in the network’s outputs.
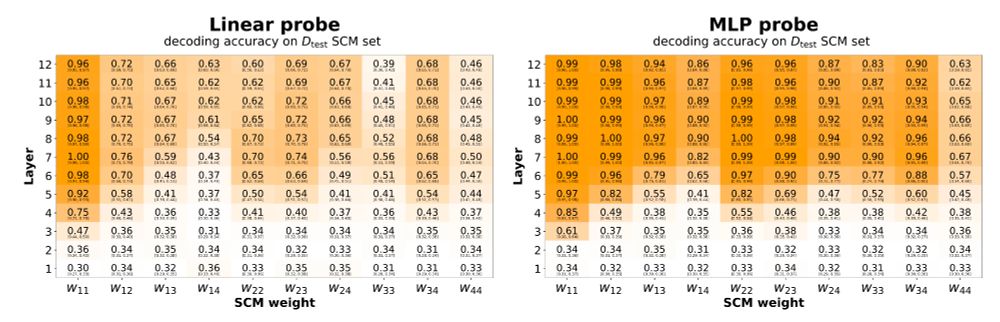
13/ Result 2: We can decode the SCM weights directly from the transformer's residual stream activations using linear and MLP probes. The model builds interpretable internal representations of causal structure.
November 18, 2025 at 2:11 AM
13/ Result 2: We can decode the SCM weights directly from the transformer's residual stream activations using linear and MLP probes. The model builds interpretable internal representations of causal structure.
12/ But does the model really have internal causal models, or is this just lucky generalization? We probe inside to find out...
November 18, 2025 at 2:11 AM
12/ But does the model really have internal causal models, or is this just lucky generalization? We probe inside to find out...
11/ Result 1: Yes! The model generalizes to counterfactual queries about D_test SCMs, reaching near-optimal performance. It must have: (1) learned a counterfactual inference engine, (2) discovered D_test structures from DATA strings, (3) composed them together.

November 18, 2025 at 2:11 AM
11/ Result 1: Yes! The model generalizes to counterfactual queries about D_test SCMs, reaching near-optimal performance. It must have: (1) learned a counterfactual inference engine, (2) discovered D_test structures from DATA strings, (3) composed them together.
10/ The generalization challenge: We hold out 1,000 SCMs (D_test) where the model sees *only* interventional DATA strings during training and zero INFERENCE examples. Can it still answer counterfactual queries about these SCMs?

November 18, 2025 at 2:11 AM
10/ The generalization challenge: We hold out 1,000 SCMs (D_test) where the model sees *only* interventional DATA strings during training and zero INFERENCE examples. Can it still answer counterfactual queries about these SCMs?
9/ We train a GPT-style transformer to predict the next token in this text. The key question: does it simply memorize the training data, or does it discover causal structure and perform inference?

November 18, 2025 at 2:11 AM
9/ We train a GPT-style transformer to predict the next token in this text. The key question: does it simply memorize the training data, or does it discover causal structure and perform inference?
8/ Our setup: ~59k SCMs, each defined by 10 ternary weights. We generate training data using the SCMs in an artificial language with two string types: (1) DATA provide noisy interventional samples and (2) INFERENCE — counterfactual means/stds.

November 18, 2025 at 2:11 AM
8/ Our setup: ~59k SCMs, each defined by 10 ternary weights. We generate training data using the SCMs in an artificial language with two string types: (1) DATA provide noisy interventional samples and (2) INFERENCE — counterfactual means/stds.
7/ Our hypothesis: next-token prediction can drive the emergence of genuine causal models and inference capabilities. We tested this in a controlled setting with linear Gaussian structural causal models (SCMs).

November 18, 2025 at 2:11 AM
7/ Our hypothesis: next-token prediction can drive the emergence of genuine causal models and inference capabilities. We tested this in a controlled setting with linear Gaussian structural causal models (SCMs).
6/ Pearl (Amstat News interview, 2023) and Zečević et al. (2023) acknowledge causal info exists in text, but argue LLMs are merely "causal parrots"—they memorize and recite but do not possess actual causal models.

November 18, 2025 at 2:11 AM
6/ Pearl (Amstat News interview, 2023) and Zečević et al. (2023) acknowledge causal info exists in text, but argue LLMs are merely "causal parrots"—they memorize and recite but do not possess actual causal models.
5/ But natural language used to train LLMs contains rich descriptions of interventions and causal inferences. Passive data != observational data. Text has L2/L3 information!

November 18, 2025 at 2:11 AM
5/ But natural language used to train LLMs contains rich descriptions of interventions and causal inferences. Passive data != observational data. Text has L2/L3 information!
4/ Pearl’s vivid metaphor from “The Book of Why” (p. 362): “Like prisoners in Plato's cave, deep-learning systems explore shadows on the wall and learn to predict their movements. They lack understanding that shadows are mere projections of 3D objects in 3D space.”

November 18, 2025 at 2:11 AM
4/ Pearl’s vivid metaphor from “The Book of Why” (p. 362): “Like prisoners in Plato's cave, deep-learning systems explore shadows on the wall and learn to predict their movements. They lack understanding that shadows are mere projections of 3D objects in 3D space.”
3/ Pearl's argument: DNNs trained on “passive” observations using statistical prediction objectives are fundamentally limited to associations (L1) and cannot reason about interventions (L2) or counterfactuals (L3).

November 18, 2025 at 2:11 AM
3/ Pearl's argument: DNNs trained on “passive” observations using statistical prediction objectives are fundamentally limited to associations (L1) and cannot reason about interventions (L2) or counterfactuals (L3).
2/ Paper: “Causal Discovery and Inference through Next-Token Prediction” (Butkus & Kriegeskorte)
OpenReview: openreview.net/pdf?id=MMYTA...,
NeurIPS: neurips.cc/virtual/2025...
OpenReview: openreview.net/pdf?id=MMYTA...,
NeurIPS: neurips.cc/virtual/2025...
November 18, 2025 at 2:11 AM
2/ Paper: “Causal Discovery and Inference through Next-Token Prediction” (Butkus & Kriegeskorte)
OpenReview: openreview.net/pdf?id=MMYTA...,
NeurIPS: neurips.cc/virtual/2025...
OpenReview: openreview.net/pdf?id=MMYTA...,
NeurIPS: neurips.cc/virtual/2025...
reminds me of Dennett's take that we should be building "tools not colleagues"
January 5, 2025 at 10:41 PM
reminds me of Dennett's take that we should be building "tools not colleagues"