



.txt
@dottxtai.bsky.social
We make AI speak the language of every application
We did make the machines in our own image
May 29, 2025 at 8:57 PM
We did make the machines in our own image
Very cool paper. arxiv.org/abs/2504.09246

Type-Constrained Code Generation with Language Models
Large language models (LLMs) have achieved notable success in code generation. However, they still frequently produce uncompilable output because their next-token inference procedure does not model…
arxiv.org
May 13, 2025 at 4:06 PM
Very cool paper. arxiv.org/abs/2504.09246
Here's a good example of a case where type-constrained decoding ensures that the program is semantically valid at generation time. Left is the unconstrained model, right is the type-constrained approach. Missing arguments, missing return values, missing type annotations. They fixed it for you.

May 13, 2025 at 4:06 PM
Here's a good example of a case where type-constrained decoding ensures that the program is semantically valid at generation time. Left is the unconstrained model, right is the type-constrained approach. Missing arguments, missing return values, missing type annotations. They fixed it for you.
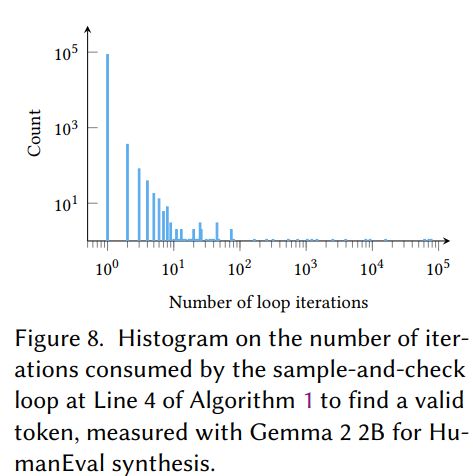
The authors here use rejection methods (guess and check), rather than the constrained decoding approach that modifies the token probabilities by disabling invalid tokens, like Outlines. Type checking is relatively cheap, and the model's first guess is correct 99.4% of the time.
May 13, 2025 at 4:06 PM
The authors here use rejection methods (guess and check), rather than the constrained decoding approach that modifies the token probabilities by disabling invalid tokens, like Outlines. Type checking is relatively cheap, and the model's first guess is correct 99.4% of the time.
The authors propose a novel solution to this, by rejecting tokens that would invalidate a type check. In the following example, num is known to be a number. Only one of these completions is valid, which is to convert the number to a string (as required by parseInt)

May 13, 2025 at 4:06 PM
The authors propose a novel solution to this, by rejecting tokens that would invalidate a type check. In the following example, num is known to be a number. Only one of these completions is valid, which is to convert the number to a string (as required by parseInt)
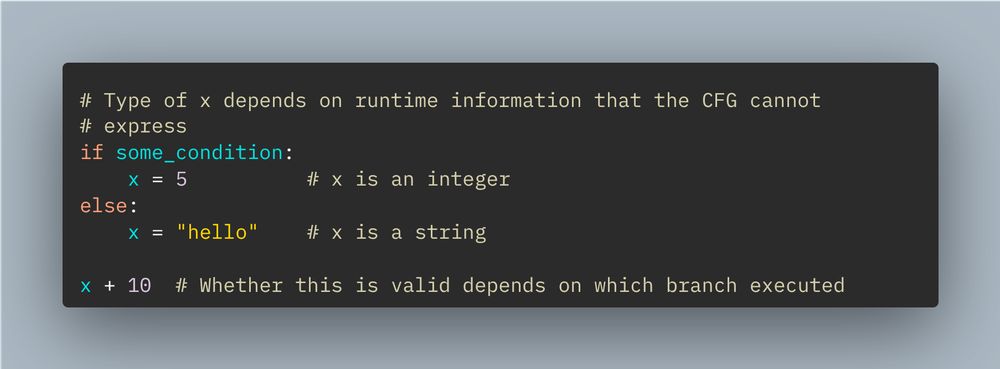
As an example, a context-free grammar cannot express the following type checking constraint, as there is no way of knowing ahead of time what the type of `x` is. Constrained decoding using a CFG cannot enforce the validity of "x+10".
May 13, 2025 at 4:06 PM
As an example, a context-free grammar cannot express the following type checking constraint, as there is no way of knowing ahead of time what the type of `x` is. Constrained decoding using a CFG cannot enforce the validity of "x+10".
Context-free grammars are interesting in their own right. We'll do a thread about them at some point. For now, you should think of them as a "programming language for language" -- they describe the "shape" of text, such as code or natural language.
May 13, 2025 at 4:06 PM
Context-free grammars are interesting in their own right. We'll do a thread about them at some point. For now, you should think of them as a "programming language for language" -- they describe the "shape" of text, such as code or natural language.
Addressing this is an infamously difficult problem. Most programming languages are not "context-free", meaning that constraining a language model's output to be semantically valid cannot be done in advance using what is called a "context-free grammar".
May 13, 2025 at 4:06 PM
Addressing this is an infamously difficult problem. Most programming languages are not "context-free", meaning that constraining a language model's output to be semantically valid cannot be done in advance using what is called a "context-free grammar".
Most LLM-based failures in code generation are not syntactic errors (incorrect formatting). They are typically semantic failures (wrong types, missing arguments, etc). The paper notes that 94% of their compilation errors are due to incorrect types, with the remaining 6% due to syntax errors.
May 13, 2025 at 4:06 PM
Most LLM-based failures in code generation are not syntactic errors (incorrect formatting). They are typically semantic failures (wrong types, missing arguments, etc). The paper notes that 94% of their compilation errors are due to incorrect types, with the remaining 6% due to syntax errors.
Grammar prompting is similar to chain-of-thought prompting, but with formal grammar as the intermediate reasoning step rather than natural language.
It's a cool paper, go take a look.
It's a cool paper, go take a look.
April 28, 2025 at 7:00 PM
Grammar prompting is similar to chain-of-thought prompting, but with formal grammar as the intermediate reasoning step rather than natural language.
It's a cool paper, go take a look.
It's a cool paper, go take a look.
At inference time, the model generates a specialized grammar for the input, then generates output constrained by those grammar rules - creating a two-stage process of grammar selection + code generation.
Rather than input -> output, the model does input -> grammar -> output.
Rather than input -> output, the model does input -> grammar -> output.
April 28, 2025 at 7:00 PM
At inference time, the model generates a specialized grammar for the input, then generates output constrained by those grammar rules - creating a two-stage process of grammar selection + code generation.
Rather than input -> output, the model does input -> grammar -> output.
Rather than input -> output, the model does input -> grammar -> output.
For each input/output example, they provide a context-free grammar that's minimally-sufficient for generating that specific output, teaching the LLM to understand grammar as a reasoning tool.
April 28, 2025 at 7:00 PM
For each input/output example, they provide a context-free grammar that's minimally-sufficient for generating that specific output, teaching the LLM to understand grammar as a reasoning tool.
The gist: LLMs struggle with DSLs because these formal languages have specialized syntax rarely seen in training data. Grammar prompting addresses this by teaching LLMs to work with Backus-Naur Form (BNF) grammars as an intermediate reasoning step.
April 28, 2025 at 7:00 PM
The gist: LLMs struggle with DSLs because these formal languages have specialized syntax rarely seen in training data. Grammar prompting addresses this by teaching LLMs to work with Backus-Naur Form (BNF) grammars as an intermediate reasoning step.