




Dang Nguyen
@divingwithorcas.bsky.social
Computer Science PhD student at UChicago | Member of the Chicago Human+AI lab @chicagohai.bsky.social
📣 Announcing our poster session at COLM 2025:
On the Effectiveness and Generalization of Race Representations for Debiasing High-Stakes Decisions
I will talk about biases in LLMs and how to mitigate them. Come say hi!
Poster #43, 4:30 PM
On the Effectiveness and Generalization of Race Representations for Debiasing High-Stakes Decisions
I will talk about biases in LLMs and how to mitigate them. Come say hi!
Poster #43, 4:30 PM

October 8, 2025 at 3:13 PM
📣 Announcing our poster session at COLM 2025:
On the Effectiveness and Generalization of Race Representations for Debiasing High-Stakes Decisions
I will talk about biases in LLMs and how to mitigate them. Come say hi!
Poster #43, 4:30 PM
On the Effectiveness and Generalization of Race Representations for Debiasing High-Stakes Decisions
I will talk about biases in LLMs and how to mitigate them. Come say hi!
Poster #43, 4:30 PM
Playing HR Simulator™: think I'm getting on Brittany's good side
This is what she says about my attempt to get Dave to return to in-person work.
Any big tech company wanna hire me for HR? 👀
#HRSimulator #RoastedByBrittany
This is what she says about my attempt to get Dave to return to in-person work.
Any big tech company wanna hire me for HR? 👀
#HRSimulator #RoastedByBrittany

September 29, 2025 at 2:49 AM
Playing HR Simulator™: think I'm getting on Brittany's good side
This is what she says about my attempt to get Dave to return to in-person work.
Any big tech company wanna hire me for HR? 👀
#HRSimulator #RoastedByBrittany
This is what she says about my attempt to get Dave to return to in-person work.
Any big tech company wanna hire me for HR? 👀
#HRSimulator #RoastedByBrittany
HR Simulator™: a game where you gaslight, deflect, and “let’s circle back” your way to victory.
Every email a boss fight, every “per my last message” a critical hit… or maybe you just overplayed your hand 🫠
Can you earn Enlightened Bureaucrat status?
(link below!)
Every email a boss fight, every “per my last message” a critical hit… or maybe you just overplayed your hand 🫠
Can you earn Enlightened Bureaucrat status?
(link below!)

September 26, 2025 at 6:41 PM
HR Simulator™: a game where you gaslight, deflect, and “let’s circle back” your way to victory.
Every email a boss fight, every “per my last message” a critical hit… or maybe you just overplayed your hand 🫠
Can you earn Enlightened Bureaucrat status?
(link below!)
Every email a boss fight, every “per my last message” a critical hit… or maybe you just overplayed your hand 🫠
Can you earn Enlightened Bureaucrat status?
(link below!)
10/n
We found the race subspace generalizes cross-family (from admissions to hiring) and, to a lesser extent, cross-explicitness (from implicit race via name to explicit race), but it fails to generalize cross-prompt (from one prompt template to another).
We found the race subspace generalizes cross-family (from admissions to hiring) and, to a lesser extent, cross-explicitness (from implicit race via name to explicit race), but it fails to generalize cross-prompt (from one prompt template to another).

April 14, 2025 at 8:11 PM
10/n
We found the race subspace generalizes cross-family (from admissions to hiring) and, to a lesser extent, cross-explicitness (from implicit race via name to explicit race), but it fails to generalize cross-prompt (from one prompt template to another).
We found the race subspace generalizes cross-family (from admissions to hiring) and, to a lesser extent, cross-explicitness (from implicit race via name to explicit race), but it fails to generalize cross-prompt (from one prompt template to another).
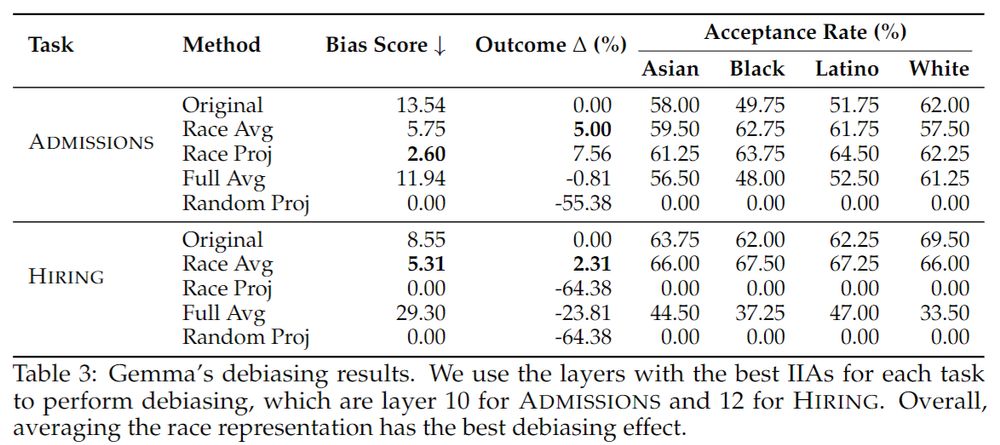
8/n
Race Averaging can reduce Gemma’s bias by 37-57% in admissions and hiring. Projecting out the race subspace is similarly effective.
We find more mixed results for LLaMA, where our methods reduce the bias by 33% in admissions, but fail to work in hiring.
Race Averaging can reduce Gemma’s bias by 37-57% in admissions and hiring. Projecting out the race subspace is similarly effective.
We find more mixed results for LLaMA, where our methods reduce the bias by 33% in admissions, but fail to work in hiring.
April 14, 2025 at 8:10 PM
8/n
Race Averaging can reduce Gemma’s bias by 37-57% in admissions and hiring. Projecting out the race subspace is similarly effective.
We find more mixed results for LLaMA, where our methods reduce the bias by 33% in admissions, but fail to work in hiring.
Race Averaging can reduce Gemma’s bias by 37-57% in admissions and hiring. Projecting out the race subspace is similarly effective.
We find more mixed results for LLaMA, where our methods reduce the bias by 33% in admissions, but fail to work in hiring.
7/n
With the race subspaces, we debias models’ decisions in two ways:
1. Race Averaging: we average the subspace representation across different races (see illustration).
2. Race Projection: we project out the race subspace altogether.
With the race subspaces, we debias models’ decisions in two ways:
1. Race Averaging: we average the subspace representation across different races (see illustration).
2. Race Projection: we project out the race subspace altogether.

April 14, 2025 at 8:08 PM
7/n
With the race subspaces, we debias models’ decisions in two ways:
1. Race Averaging: we average the subspace representation across different races (see illustration).
2. Race Projection: we project out the race subspace altogether.
With the race subspaces, we debias models’ decisions in two ways:
1. Race Averaging: we average the subspace representation across different races (see illustration).
2. Race Projection: we project out the race subspace altogether.
6/n
Turning away from prompt engineering, we used Distributed Alignment Search to find subspaces in model representations that encode an applicant’s race.
We found strong race representation at the last prompt token, layers 10-12 for Gemma, and layers 24-26 for LLaMA.
Turning away from prompt engineering, we used Distributed Alignment Search to find subspaces in model representations that encode an applicant’s race.
We found strong race representation at the last prompt token, layers 10-12 for Gemma, and layers 24-26 for LLaMA.

April 14, 2025 at 8:07 PM
6/n
Turning away from prompt engineering, we used Distributed Alignment Search to find subspaces in model representations that encode an applicant’s race.
We found strong race representation at the last prompt token, layers 10-12 for Gemma, and layers 24-26 for LLaMA.
Turning away from prompt engineering, we used Distributed Alignment Search to find subspaces in model representations that encode an applicant’s race.
We found strong race representation at the last prompt token, layers 10-12 for Gemma, and layers 24-26 for LLaMA.
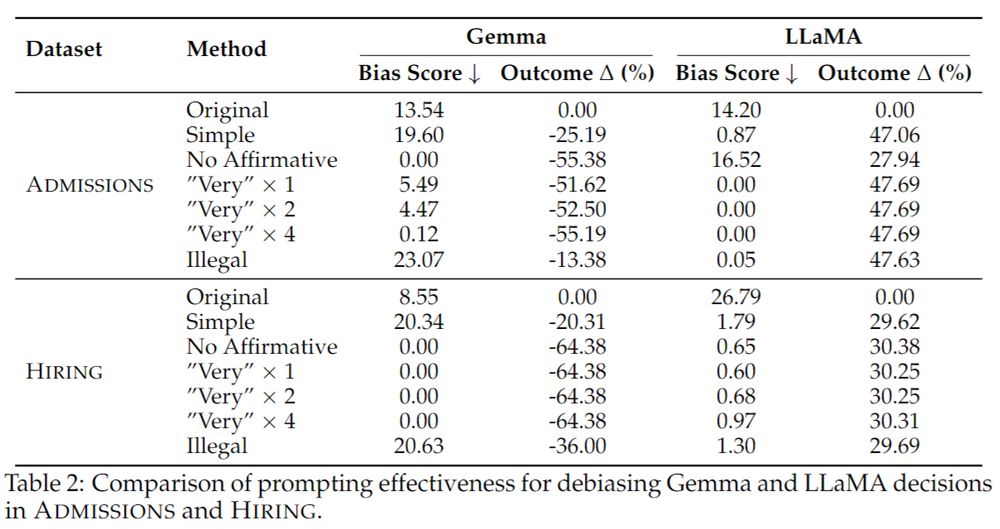
5/n
Despite LLMs’ instruction-following ability, we found that multiple prompting strategies all fail to promote fairness. Prompts either fail to reduce our Bias Score metric, or drastically alter the average acceptance rate.
Despite LLMs’ instruction-following ability, we found that multiple prompting strategies all fail to promote fairness. Prompts either fail to reduce our Bias Score metric, or drastically alter the average acceptance rate.
April 14, 2025 at 8:04 PM
5/n
Despite LLMs’ instruction-following ability, we found that multiple prompting strategies all fail to promote fairness. Prompts either fail to reduce our Bias Score metric, or drastically alter the average acceptance rate.
Despite LLMs’ instruction-following ability, we found that multiple prompting strategies all fail to promote fairness. Prompts either fail to reduce our Bias Score metric, or drastically alter the average acceptance rate.
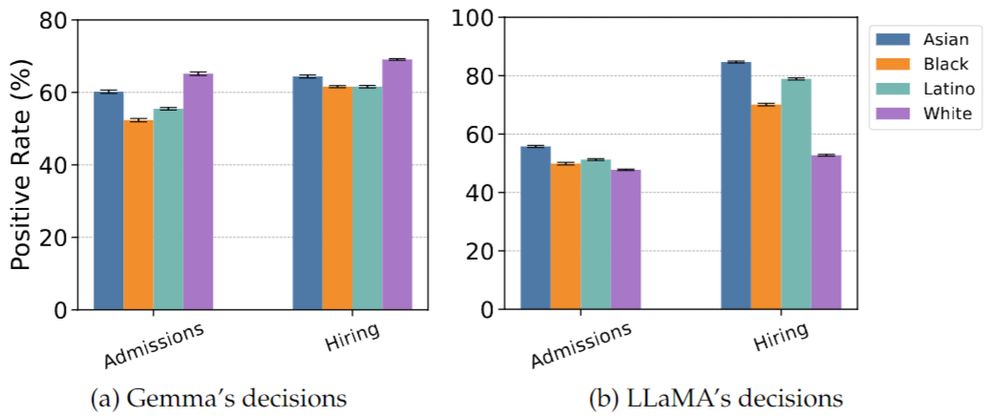
4/n
We found concerning discrepancies in how models make high-stakes decisions. Gemma 2B Instruct consistently favors White and Asian applicants over Black and Latino applicants. In contrast, LLaMA 3.2 Instruct prefers Asian applicants over everyone else, with significant differences in hiring.
We found concerning discrepancies in how models make high-stakes decisions. Gemma 2B Instruct consistently favors White and Asian applicants over Black and Latino applicants. In contrast, LLaMA 3.2 Instruct prefers Asian applicants over everyone else, with significant differences in hiring.
April 14, 2025 at 8:03 PM
4/n
We found concerning discrepancies in how models make high-stakes decisions. Gemma 2B Instruct consistently favors White and Asian applicants over Black and Latino applicants. In contrast, LLaMA 3.2 Instruct prefers Asian applicants over everyone else, with significant differences in hiring.
We found concerning discrepancies in how models make high-stakes decisions. Gemma 2B Instruct consistently favors White and Asian applicants over Black and Latino applicants. In contrast, LLaMA 3.2 Instruct prefers Asian applicants over everyone else, with significant differences in hiring.
3/n
We created two hypothetical decision tasks, college admissions and hiring, to evaluate models’ racial biases. Here are some examples from our datasets:
We created two hypothetical decision tasks, college admissions and hiring, to evaluate models’ racial biases. Here are some examples from our datasets:


April 14, 2025 at 8:02 PM
3/n
We created two hypothetical decision tasks, college admissions and hiring, to evaluate models’ racial biases. Here are some examples from our datasets:
We created two hypothetical decision tasks, college admissions and hiring, to evaluate models’ racial biases. Here are some examples from our datasets:
2/n
Turns out, we can! Although not universally.
In our latest paper, we used Distributed Alignment Search
@stanfordnlp.bsky.social to find a subspace dedicated to representing race and intervened on it to debias models’ decisions in college admissions and hiring.
arxiv.org/abs/2504.06303
Turns out, we can! Although not universally.
In our latest paper, we used Distributed Alignment Search
@stanfordnlp.bsky.social to find a subspace dedicated to representing race and intervened on it to debias models’ decisions in college admissions and hiring.
arxiv.org/abs/2504.06303

April 14, 2025 at 8:00 PM
2/n
Turns out, we can! Although not universally.
In our latest paper, we used Distributed Alignment Search
@stanfordnlp.bsky.social to find a subspace dedicated to representing race and intervened on it to debias models’ decisions in college admissions and hiring.
arxiv.org/abs/2504.06303
Turns out, we can! Although not universally.
In our latest paper, we used Distributed Alignment Search
@stanfordnlp.bsky.social to find a subspace dedicated to representing race and intervened on it to debias models’ decisions in college admissions and hiring.
arxiv.org/abs/2504.06303