




Dimitris Papailiopoulos
@dimitrisp.bsky.social
Researcher @MSFTResearch; Prof @UWMadison (on leave); learning in context; thinking about reasoning; babas of Inez Lily.
https://papail.io
https://papail.io
Is 1948 widely acknowledged as the birth of language models and tokenizers?
In "A Mathematical Theory of Communication", almost as an afterthought Shannon suggests the N-gram for generating English, and that word level tokenization is better than character level tokenization.
In "A Mathematical Theory of Communication", almost as an afterthought Shannon suggests the N-gram for generating English, and that word level tokenization is better than character level tokenization.

May 7, 2025 at 12:05 PM
Is 1948 widely acknowledged as the birth of language models and tokenizers?
In "A Mathematical Theory of Communication", almost as an afterthought Shannon suggests the N-gram for generating English, and that word level tokenization is better than character level tokenization.
In "A Mathematical Theory of Communication", almost as an afterthought Shannon suggests the N-gram for generating English, and that word level tokenization is better than character level tokenization.
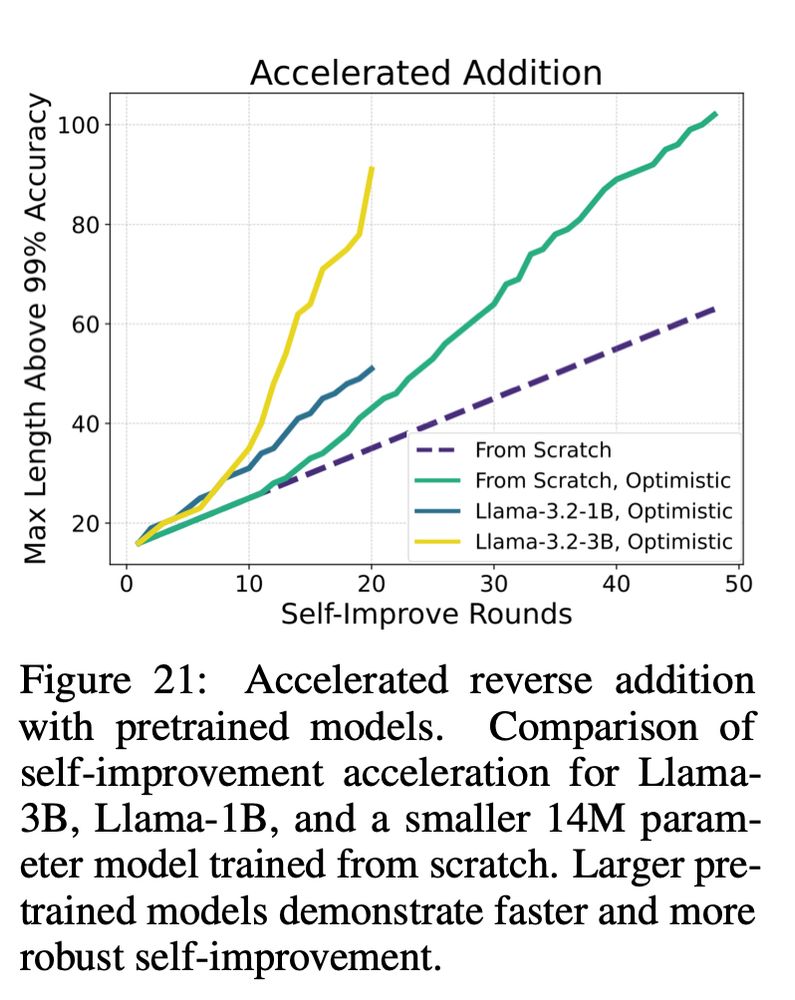
Oh btw, self improvement can become exponentially faster in some settings, ory when we apply it on pretrained models (again this is all for add/mul/maze etc)

February 13, 2025 at 1:33 PM
Oh btw, self improvement can become exponentially faster in some settings, ory when we apply it on pretrained models (again this is all for add/mul/maze etc)
An important aspect of the method is that you need to
1) generate problems of appropriate hardness
2) be able to filter our negative examples using a cheap verifier.
Otherwise the benefit of self-improvement collapses.
1) generate problems of appropriate hardness
2) be able to filter our negative examples using a cheap verifier.
Otherwise the benefit of self-improvement collapses.


February 13, 2025 at 1:33 PM
An important aspect of the method is that you need to
1) generate problems of appropriate hardness
2) be able to filter our negative examples using a cheap verifier.
Otherwise the benefit of self-improvement collapses.
1) generate problems of appropriate hardness
2) be able to filter our negative examples using a cheap verifier.
Otherwise the benefit of self-improvement collapses.
We test self-improvement across diverse algorithmic tasks:
- Arithmetic: Reverse addition, forward (yes forward!) addition, multiplication (with CoT)
- String Manipulation: Copying, reversing
- Maze Solving: Finding shortest paths in graphs.
It always works
- Arithmetic: Reverse addition, forward (yes forward!) addition, multiplication (with CoT)
- String Manipulation: Copying, reversing
- Maze Solving: Finding shortest paths in graphs.
It always works

February 13, 2025 at 1:33 PM
We test self-improvement across diverse algorithmic tasks:
- Arithmetic: Reverse addition, forward (yes forward!) addition, multiplication (with CoT)
- String Manipulation: Copying, reversing
- Maze Solving: Finding shortest paths in graphs.
It always works
- Arithmetic: Reverse addition, forward (yes forward!) addition, multiplication (with CoT)
- String Manipulation: Copying, reversing
- Maze Solving: Finding shortest paths in graphs.
It always works
What if we leverage this?
What if we let the model label slightly harder data… and then train on them?
Our key idea is to use Self-Improving Transformers , where a model iteratively labels its own train data and learns from progressively harder examples (inspired by methods like STaR and ReST).
What if we let the model label slightly harder data… and then train on them?
Our key idea is to use Self-Improving Transformers , where a model iteratively labels its own train data and learns from progressively harder examples (inspired by methods like STaR and ReST).

February 13, 2025 at 1:33 PM
What if we leverage this?
What if we let the model label slightly harder data… and then train on them?
Our key idea is to use Self-Improving Transformers , where a model iteratively labels its own train data and learns from progressively harder examples (inspired by methods like STaR and ReST).
What if we let the model label slightly harder data… and then train on them?
Our key idea is to use Self-Improving Transformers , where a model iteratively labels its own train data and learns from progressively harder examples (inspired by methods like STaR and ReST).
I was kind of done with length gen, but then I took a closer look at that figure above..
I noticed that there is a bit of transcendence, i.e the model trained on n-digit ADD can solve slightly harder problems, eg n+1, but not much more.
(cc on transcendence and chess arxiv.org/html/2406.11741v1)
I noticed that there is a bit of transcendence, i.e the model trained on n-digit ADD can solve slightly harder problems, eg n+1, but not much more.
(cc on transcendence and chess arxiv.org/html/2406.11741v1)

February 13, 2025 at 1:33 PM
I was kind of done with length gen, but then I took a closer look at that figure above..
I noticed that there is a bit of transcendence, i.e the model trained on n-digit ADD can solve slightly harder problems, eg n+1, but not much more.
(cc on transcendence and chess arxiv.org/html/2406.11741v1)
I noticed that there is a bit of transcendence, i.e the model trained on n-digit ADD can solve slightly harder problems, eg n+1, but not much more.
(cc on transcendence and chess arxiv.org/html/2406.11741v1)
Even for simple algorithmic tasks like integer addition, performance collapses as sequence length increases. The only way so far that overcomes this relies on heavily optimizing positional encoding and data format.
(Figure from: Cho et al., arxiv.org/abs/2405.20671)
(Figure from: Cho et al., arxiv.org/abs/2405.20671)

February 13, 2025 at 1:33 PM
Even for simple algorithmic tasks like integer addition, performance collapses as sequence length increases. The only way so far that overcomes this relies on heavily optimizing positional encoding and data format.
(Figure from: Cho et al., arxiv.org/abs/2405.20671)
(Figure from: Cho et al., arxiv.org/abs/2405.20671)
o3 can't multiply beyond a few digits...
But I think multiplication, addition, maze solving and easy-to-hard generalization is actually solvable on standard transformers...
with recursive self-improvement
Below is the acc of a tiny model teaching itself how to add and multiply
But I think multiplication, addition, maze solving and easy-to-hard generalization is actually solvable on standard transformers...
with recursive self-improvement
Below is the acc of a tiny model teaching itself how to add and multiply


February 13, 2025 at 1:33 PM
o3 can't multiply beyond a few digits...
But I think multiplication, addition, maze solving and easy-to-hard generalization is actually solvable on standard transformers...
with recursive self-improvement
Below is the acc of a tiny model teaching itself how to add and multiply
But I think multiplication, addition, maze solving and easy-to-hard generalization is actually solvable on standard transformers...
with recursive self-improvement
Below is the acc of a tiny model teaching itself how to add and multiply
Self-improving Transformers can overcome easy-to-hard and length generalization challenges.
Paper on arxiv coming on Monday.
Link to a talk I gave on this below 👇
Super excited about this work!
Talk : youtube.com/watch?v=szhE...
slides: tinyurl.com/SelfImprovem...
Paper on arxiv coming on Monday.
Link to a talk I gave on this below 👇
Super excited about this work!
Talk : youtube.com/watch?v=szhE...
slides: tinyurl.com/SelfImprovem...



February 2, 2025 at 1:23 PM
Self-improving Transformers can overcome easy-to-hard and length generalization challenges.
Paper on arxiv coming on Monday.
Link to a talk I gave on this below 👇
Super excited about this work!
Talk : youtube.com/watch?v=szhE...
slides: tinyurl.com/SelfImprovem...
Paper on arxiv coming on Monday.
Link to a talk I gave on this below 👇
Super excited about this work!
Talk : youtube.com/watch?v=szhE...
slides: tinyurl.com/SelfImprovem...
Two months before R1 came out, I wrote this in my small notebook of ideas as something to test #schmidhuber

February 1, 2025 at 6:53 PM
Two months before R1 came out, I wrote this in my small notebook of ideas as something to test #schmidhuber
Example 8: Draw the coolest thing you can (sonnet wins this one :))


January 20, 2025 at 5:01 AM
Example 8: Draw the coolest thing you can (sonnet wins this one :))
Example 7: Draw OpenAI's logo


January 20, 2025 at 5:01 AM
Example 7: Draw OpenAI's logo
Example 6: Draw a heart


January 20, 2025 at 5:01 AM
Example 6: Draw a heart
Example 5: Draw a cube


January 20, 2025 at 5:01 AM
Example 5: Draw a cube
Example 4: Drawn an obtuse triangle (o1 wins)


January 20, 2025 at 5:01 AM
Example 4: Drawn an obtuse triangle (o1 wins)
Example 3: Draw a house


January 20, 2025 at 5:01 AM
Example 3: Draw a house
Example 2: Draw a sun


January 20, 2025 at 5:01 AM
Example 2: Draw a sun
I love finding silly tests that LLMs are terrible at.
Here's a new one for me: Drawing with Logo (yes the turtle)!
To be fair drawing with Logo is hard. But.. here goes 8 examples with sonnet 3.6 vs o1.
Example 1/8: Draw the letter G
Here's a new one for me: Drawing with Logo (yes the turtle)!
To be fair drawing with Logo is hard. But.. here goes 8 examples with sonnet 3.6 vs o1.
Example 1/8: Draw the letter G


January 20, 2025 at 5:01 AM
I love finding silly tests that LLMs are terrible at.
Here's a new one for me: Drawing with Logo (yes the turtle)!
To be fair drawing with Logo is hard. But.. here goes 8 examples with sonnet 3.6 vs o1.
Example 1/8: Draw the letter G
Here's a new one for me: Drawing with Logo (yes the turtle)!
To be fair drawing with Logo is hard. But.. here goes 8 examples with sonnet 3.6 vs o1.
Example 1/8: Draw the letter G
Task vectors are akin to punchcards: you feed them to your LLM and it implements specific tasks, without in-context demonstrations. Liu's new paper examines at what scale, where in the network and when during training do they emerge, and how to encourage their emergence.
arxiv.org/pdf/2501.09240
arxiv.org/pdf/2501.09240




January 18, 2025 at 4:51 PM
Task vectors are akin to punchcards: you feed them to your LLM and it implements specific tasks, without in-context demonstrations. Liu's new paper examines at what scale, where in the network and when during training do they emerge, and how to encourage their emergence.
arxiv.org/pdf/2501.09240
arxiv.org/pdf/2501.09240
The single most insightful paper that I read after the initial wave of ICL papers was one that further shifted my understanding on "the early ascent phenomenon" by
Kangwook Lee's group
x.com/Kangwook_Lee...
Kangwook Lee's group
x.com/Kangwook_Lee...

December 30, 2024 at 5:30 PM
The single most insightful paper that I read after the initial wave of ICL papers was one that further shifted my understanding on "the early ascent phenomenon" by
Kangwook Lee's group
x.com/Kangwook_Lee...
Kangwook Lee's group
x.com/Kangwook_Lee...


Life after o5 saturates FrontierMath

December 21, 2024 at 6:56 PM
Life after o5 saturates FrontierMath
Here are the two questions it can't get right no matter how many tries i tried it.


December 16, 2024 at 5:39 PM
Here are the two questions it can't get right no matter how many tries i tried it.
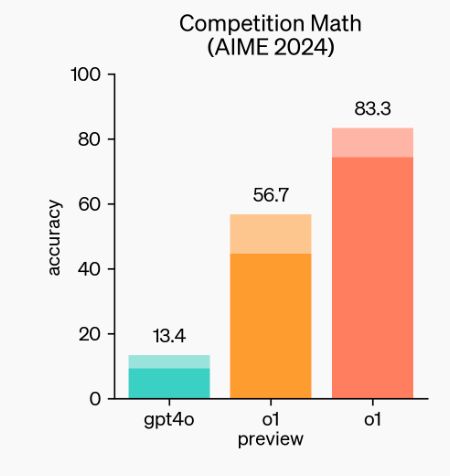
I tested chatGPT o1 pro mode (with best of N) on AIME 2024.
It scored 93.3%.
it got 14 out of 15 questions, on both I and II versions.
Uhm, wow.
It scored 93.3%.
it got 14 out of 15 questions, on both I and II versions.
Uhm, wow.
December 16, 2024 at 5:39 PM
I tested chatGPT o1 pro mode (with best of N) on AIME 2024.
It scored 93.3%.
it got 14 out of 15 questions, on both I and II versions.
Uhm, wow.
It scored 93.3%.
it got 14 out of 15 questions, on both I and II versions.
Uhm, wow.