


Dayeon (Zoey) Ki
@dayeonki.bsky.social
8/ 💌 Huge thanks to @marinecarpuat.bsky.social, Rachel, and @zhoutianyi.bsky.social for their guidance — and special shoutout to the amazing UMD CLIP team!
Check out our paper and code below 🚀
📄 Paper: arxiv.org/abs/2505.24671
🤖 Dataset: github.com/dayeonki/cul...
Check out our paper and code below 🚀
📄 Paper: arxiv.org/abs/2505.24671
🤖 Dataset: github.com/dayeonki/cul...

Multiple LLM Agents Debate for Equitable Cultural Alignment
Large Language Models (LLMs) need to adapt their predictions to diverse cultural contexts to benefit diverse communities across the world. While previous efforts have focused on single-LLM, single-tur...
arxiv.org
June 12, 2025 at 11:33 PM
8/ 💌 Huge thanks to @marinecarpuat.bsky.social, Rachel, and @zhoutianyi.bsky.social for their guidance — and special shoutout to the amazing UMD CLIP team!
Check out our paper and code below 🚀
📄 Paper: arxiv.org/abs/2505.24671
🤖 Dataset: github.com/dayeonki/cul...
Check out our paper and code below 🚀
📄 Paper: arxiv.org/abs/2505.24671
🤖 Dataset: github.com/dayeonki/cul...
7/ 🌟 What’s next for Multi-Agent Debate?
Some exciting future directions:
1️⃣ Assigning specific roles to represent diverse cultural perspectives
2️⃣ Discovering optimal strategies for multi-LLM collaboration
3️⃣ Designing better adjudication methods to resolve disagreements fairly 🤝
Some exciting future directions:
1️⃣ Assigning specific roles to represent diverse cultural perspectives
2️⃣ Discovering optimal strategies for multi-LLM collaboration
3️⃣ Designing better adjudication methods to resolve disagreements fairly 🤝
June 12, 2025 at 11:33 PM
7/ 🌟 What’s next for Multi-Agent Debate?
Some exciting future directions:
1️⃣ Assigning specific roles to represent diverse cultural perspectives
2️⃣ Discovering optimal strategies for multi-LLM collaboration
3️⃣ Designing better adjudication methods to resolve disagreements fairly 🤝
Some exciting future directions:
1️⃣ Assigning specific roles to represent diverse cultural perspectives
2️⃣ Discovering optimal strategies for multi-LLM collaboration
3️⃣ Designing better adjudication methods to resolve disagreements fairly 🤝
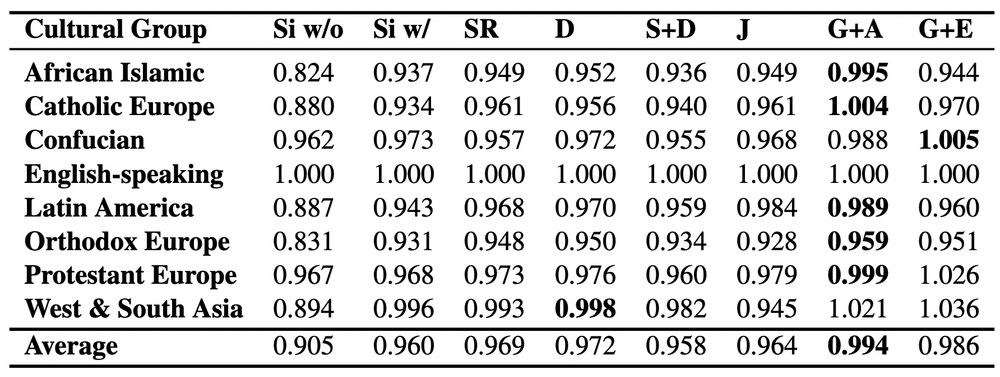
6/ But do these gains hold across cultures? 🗾
🫂 We measure cultural parity across diverse groups — and find that Multi-Agent Debate not only boosts average accuracy but also leads to more equitable cultural alignment 🌍
🫂 We measure cultural parity across diverse groups — and find that Multi-Agent Debate not only boosts average accuracy but also leads to more equitable cultural alignment 🌍
June 12, 2025 at 11:33 PM
6/ But do these gains hold across cultures? 🗾
🫂 We measure cultural parity across diverse groups — and find that Multi-Agent Debate not only boosts average accuracy but also leads to more equitable cultural alignment 🌍
🫂 We measure cultural parity across diverse groups — and find that Multi-Agent Debate not only boosts average accuracy but also leads to more equitable cultural alignment 🌍
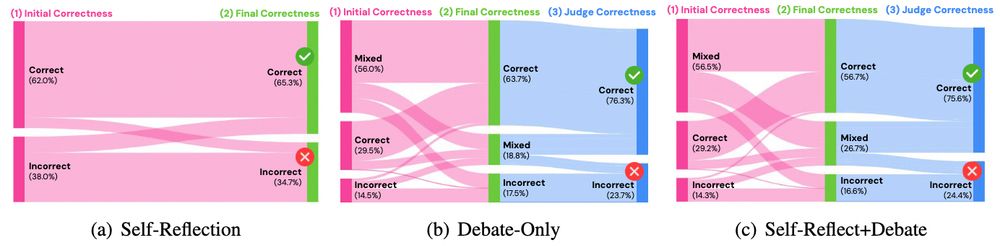
5/ How do model decisions evolve through debate?
We track three phases of LLM behavior:
💗 Initial decision correctness
💚 Final decision correctness
💙 Judge’s decision correctness
✨ Multi-Agent Debate is most valuable when models initially disagree!
We track three phases of LLM behavior:
💗 Initial decision correctness
💚 Final decision correctness
💙 Judge’s decision correctness
✨ Multi-Agent Debate is most valuable when models initially disagree!
June 12, 2025 at 11:33 PM
5/ How do model decisions evolve through debate?
We track three phases of LLM behavior:
💗 Initial decision correctness
💚 Final decision correctness
💙 Judge’s decision correctness
✨ Multi-Agent Debate is most valuable when models initially disagree!
We track three phases of LLM behavior:
💗 Initial decision correctness
💚 Final decision correctness
💙 Judge’s decision correctness
✨ Multi-Agent Debate is most valuable when models initially disagree!
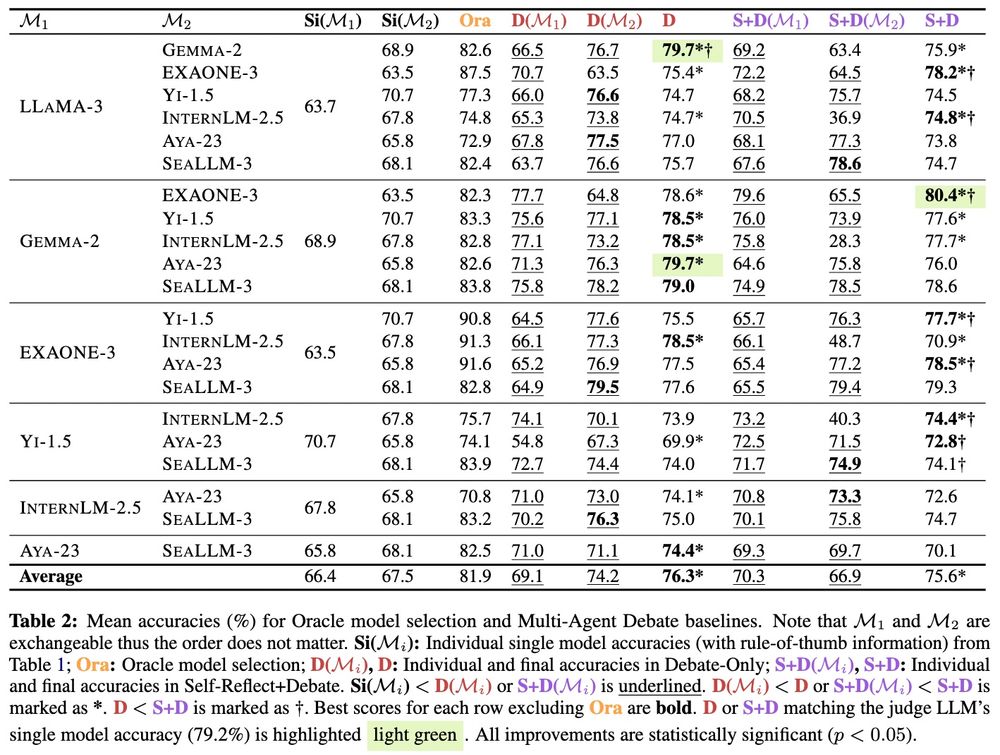
4/ 🔥 Distinct LLMs are complementary!
We find that:
🤯 Multi-Agent Debate lets smaller LLMs (7B) match the performance of much larger ones (27B)
🏆 Best combo? Gemma-2 9B + EXAONE-3 7B 💪
We find that:
🤯 Multi-Agent Debate lets smaller LLMs (7B) match the performance of much larger ones (27B)
🏆 Best combo? Gemma-2 9B + EXAONE-3 7B 💪
June 12, 2025 at 11:33 PM
4/ 🔥 Distinct LLMs are complementary!
We find that:
🤯 Multi-Agent Debate lets smaller LLMs (7B) match the performance of much larger ones (27B)
🏆 Best combo? Gemma-2 9B + EXAONE-3 7B 💪
We find that:
🤯 Multi-Agent Debate lets smaller LLMs (7B) match the performance of much larger ones (27B)
🏆 Best combo? Gemma-2 9B + EXAONE-3 7B 💪
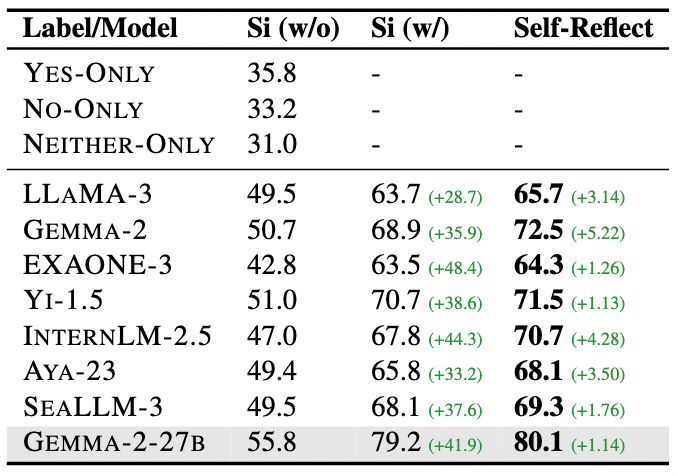
3/ Before bringing in two #LLMs, we first 📈 maximize single-LLM performance through:
1️⃣ Cultural Contextualization: adding relevant rules-of-thumb for the target culture
2️⃣ Self-Reflection: evaluating and improve its own outputs
These serve as strong baselines before we introduce collaboration 🤝
1️⃣ Cultural Contextualization: adding relevant rules-of-thumb for the target culture
2️⃣ Self-Reflection: evaluating and improve its own outputs
These serve as strong baselines before we introduce collaboration 🤝
June 12, 2025 at 11:33 PM
3/ Before bringing in two #LLMs, we first 📈 maximize single-LLM performance through:
1️⃣ Cultural Contextualization: adding relevant rules-of-thumb for the target culture
2️⃣ Self-Reflection: evaluating and improve its own outputs
These serve as strong baselines before we introduce collaboration 🤝
1️⃣ Cultural Contextualization: adding relevant rules-of-thumb for the target culture
2️⃣ Self-Reflection: evaluating and improve its own outputs
These serve as strong baselines before we introduce collaboration 🤝
2/ 🤔 Why involve multiple #LLMs?
Different LLMs bring complementary perspectives and reasoning paths, thanks to variations in:
💽 Training data
🧠 Alignment processes
🌐 Language and cultural coverage
We explore one common form of collaboration: debate.
Different LLMs bring complementary perspectives and reasoning paths, thanks to variations in:
💽 Training data
🧠 Alignment processes
🌐 Language and cultural coverage
We explore one common form of collaboration: debate.
June 12, 2025 at 11:33 PM
2/ 🤔 Why involve multiple #LLMs?
Different LLMs bring complementary perspectives and reasoning paths, thanks to variations in:
💽 Training data
🧠 Alignment processes
🌐 Language and cultural coverage
We explore one common form of collaboration: debate.
Different LLMs bring complementary perspectives and reasoning paths, thanks to variations in:
💽 Training data
🧠 Alignment processes
🌐 Language and cultural coverage
We explore one common form of collaboration: debate.
8/ ❤️ Huge thanks to @marinecarpuat.bsky.social, Kevin duh, and the amazing UMD CLIP team for all the feedback and inspiration throughout this work!
We’d love for you to check it out 🚀
📄 Paper: arxiv.org/abs/2504.11582
🤖 Dataset: github.com/dayeonki/askqe
We’d love for you to check it out 🚀
📄 Paper: arxiv.org/abs/2504.11582
🤖 Dataset: github.com/dayeonki/askqe
AskQE: Question Answering as Automatic Evaluation for Machine Translation
How can a monolingual English speaker determine whether an automatic translation in French is good enough to be shared? Existing MT error detection and quality estimation (QE) techniques do not addres...
arxiv.org
May 21, 2025 at 5:49 PM
8/ ❤️ Huge thanks to @marinecarpuat.bsky.social, Kevin duh, and the amazing UMD CLIP team for all the feedback and inspiration throughout this work!
We’d love for you to check it out 🚀
📄 Paper: arxiv.org/abs/2504.11582
🤖 Dataset: github.com/dayeonki/askqe
We’d love for you to check it out 🚀
📄 Paper: arxiv.org/abs/2504.11582
🤖 Dataset: github.com/dayeonki/askqe
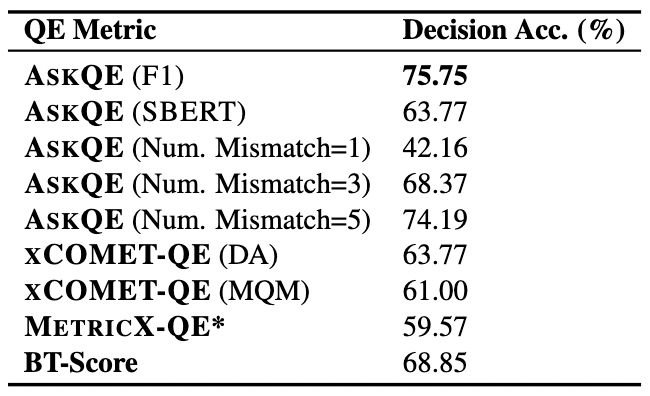
7/ Can AskQE handle naturally occurring translation errors too? 🍃
Yes! It shows:
💁♀️ Stronger correlation with human judgments
✅ Better decision-making accuracy than standard QE metrics
Yes! It shows:
💁♀️ Stronger correlation with human judgments
✅ Better decision-making accuracy than standard QE metrics
May 21, 2025 at 5:49 PM
7/ Can AskQE handle naturally occurring translation errors too? 🍃
Yes! It shows:
💁♀️ Stronger correlation with human judgments
✅ Better decision-making accuracy than standard QE metrics
Yes! It shows:
💁♀️ Stronger correlation with human judgments
✅ Better decision-making accuracy than standard QE metrics
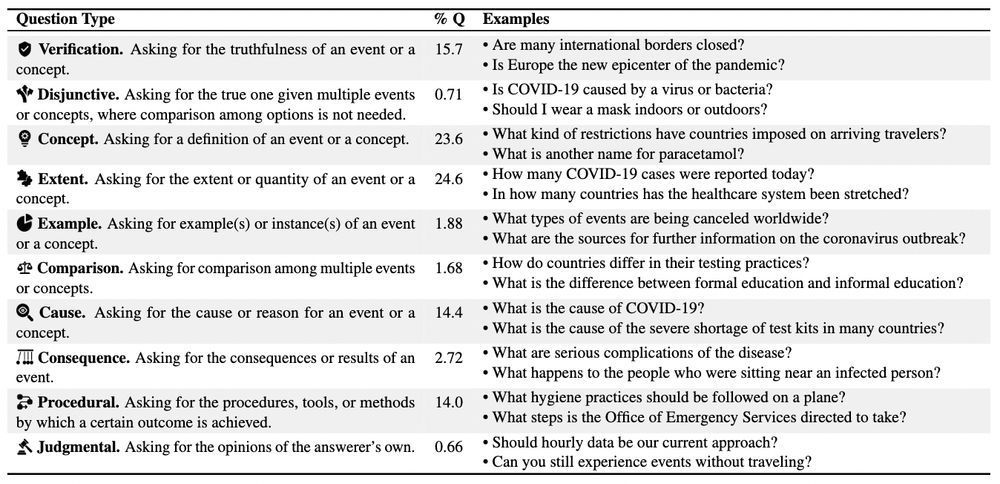
6/ 🤖 What kinds of questions does AskQE generate?
Most commonly:
📏 Extent — How many COVID-19 cases were reported today? (24.6%)
💡 Concept — What is another name for paracetamol? (23.6%)
Most commonly:
📏 Extent — How many COVID-19 cases were reported today? (24.6%)
💡 Concept — What is another name for paracetamol? (23.6%)
May 21, 2025 at 5:49 PM
6/ 🤖 What kinds of questions does AskQE generate?
Most commonly:
📏 Extent — How many COVID-19 cases were reported today? (24.6%)
💡 Concept — What is another name for paracetamol? (23.6%)
Most commonly:
📏 Extent — How many COVID-19 cases were reported today? (24.6%)
💡 Concept — What is another name for paracetamol? (23.6%)
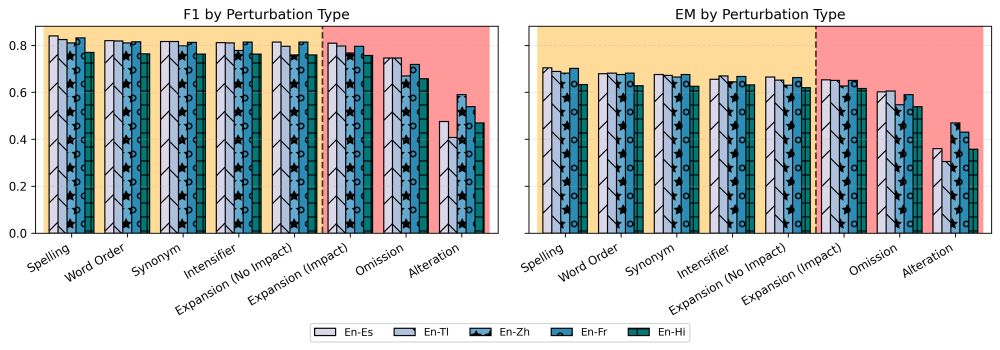
5/ 🔥 We test AskQE on ContraTICO and find:
📉 It effectively distinguishes minor to critical translation errors
👭 It aligns closely with established quality estimation (QE) metrics
📉 It effectively distinguishes minor to critical translation errors
👭 It aligns closely with established quality estimation (QE) metrics

May 21, 2025 at 5:49 PM
5/ 🔥 We test AskQE on ContraTICO and find:
📉 It effectively distinguishes minor to critical translation errors
👭 It aligns closely with established quality estimation (QE) metrics
📉 It effectively distinguishes minor to critical translation errors
👭 It aligns closely with established quality estimation (QE) metrics
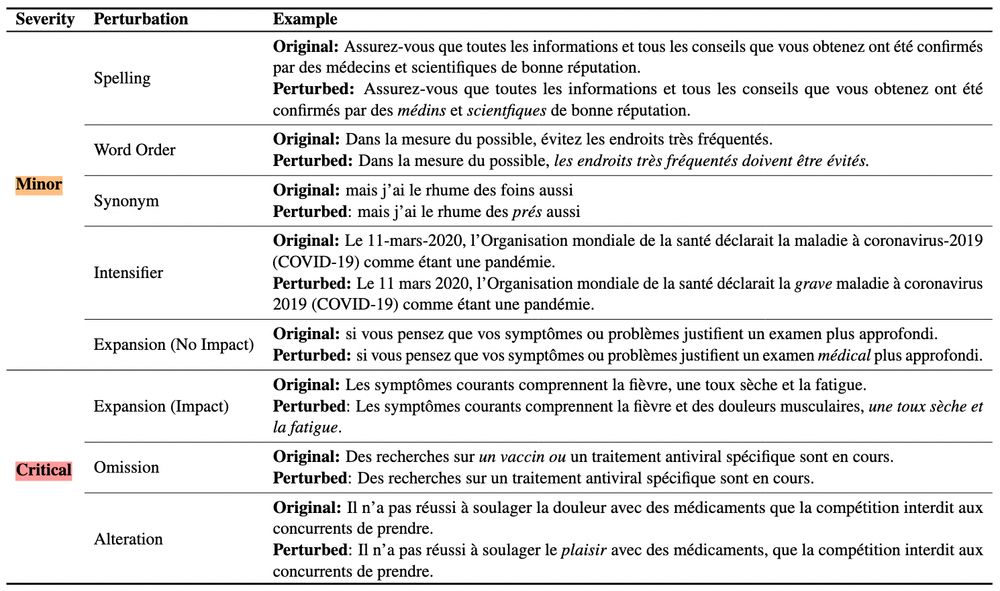
4/ We introduce ContraTICO, a dataset of 8 contrastive MT error types in the COVID-19 domain 😷🦠
⚠️ Minor errors: spelling, word order, synonym, intensifier, expansion (no impact)
📛 Critical errors: expansion (impact), omission, alteration
⚠️ Minor errors: spelling, word order, synonym, intensifier, expansion (no impact)
📛 Critical errors: expansion (impact), omission, alteration
May 21, 2025 at 5:49 PM
4/ We introduce ContraTICO, a dataset of 8 contrastive MT error types in the COVID-19 domain 😷🦠
⚠️ Minor errors: spelling, word order, synonym, intensifier, expansion (no impact)
📛 Critical errors: expansion (impact), omission, alteration
⚠️ Minor errors: spelling, word order, synonym, intensifier, expansion (no impact)
📛 Critical errors: expansion (impact), omission, alteration
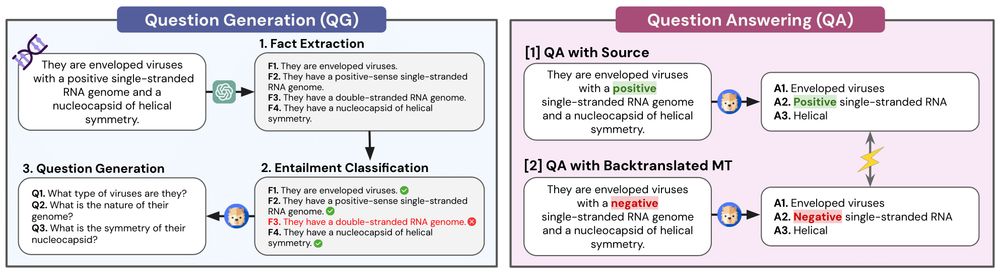
3/ AskQE has two main components:
❓ Question Generation (QG): conditioned on the source + its entailed facts
❕ Question Answering (QA): based on the source and backtranslated MT
If the answers don’t match... there's likely an error ⚠️
❓ Question Generation (QG): conditioned on the source + its entailed facts
❕ Question Answering (QA): based on the source and backtranslated MT
If the answers don’t match... there's likely an error ⚠️
May 21, 2025 at 5:49 PM
3/ AskQE has two main components:
❓ Question Generation (QG): conditioned on the source + its entailed facts
❕ Question Answering (QA): based on the source and backtranslated MT
If the answers don’t match... there's likely an error ⚠️
❓ Question Generation (QG): conditioned on the source + its entailed facts
❕ Question Answering (QA): based on the source and backtranslated MT
If the answers don’t match... there's likely an error ⚠️
2/ But why question answering? 🤔
1️⃣ Provides functional explanations of MT quality
2️⃣ Users can weigh the evidence based on their own judgment
3️⃣ Aligns well with real-world cross-lingual communication strategies 🌐
1️⃣ Provides functional explanations of MT quality
2️⃣ Users can weigh the evidence based on their own judgment
3️⃣ Aligns well with real-world cross-lingual communication strategies 🌐
May 21, 2025 at 5:49 PM
2/ But why question answering? 🤔
1️⃣ Provides functional explanations of MT quality
2️⃣ Users can weigh the evidence based on their own judgment
3️⃣ Aligns well with real-world cross-lingual communication strategies 🌐
1️⃣ Provides functional explanations of MT quality
2️⃣ Users can weigh the evidence based on their own judgment
3️⃣ Aligns well with real-world cross-lingual communication strategies 🌐
8/ 🫶 Huge thanks to my advisor @marinecarpuat.bsky.social and the amazing UMD CLIP folks for all the insightful discussions!
Please check out our paper accepted to NAACL 2025 🚀
📄 Paper: arxiv.org/abs/2502.16682
🤖 Code: github.com/dayeonki/rew...
Please check out our paper accepted to NAACL 2025 🚀
📄 Paper: arxiv.org/abs/2502.16682
🤖 Code: github.com/dayeonki/rew...
Automatic Input Rewriting Improves Translation with Large Language Models
Can we improve machine translation (MT) with LLMs by rewriting their inputs automatically? Users commonly rely on the intuition that well-written text is easier to translate when using off-the-shelf M...
arxiv.org
April 17, 2025 at 1:32 AM
8/ 🫶 Huge thanks to my advisor @marinecarpuat.bsky.social and the amazing UMD CLIP folks for all the insightful discussions!
Please check out our paper accepted to NAACL 2025 🚀
📄 Paper: arxiv.org/abs/2502.16682
🤖 Code: github.com/dayeonki/rew...
Please check out our paper accepted to NAACL 2025 🚀
📄 Paper: arxiv.org/abs/2502.16682
🤖 Code: github.com/dayeonki/rew...
7/ Taken together, we show that simpler texts are more translatable — and more broadly, #LLM-assisted input rewriting is a promising direction for improving translations! 💥
As LLM-based writing assistants grow, we encourage future work on interactive, rewriting-based approaches to MT 🫡
As LLM-based writing assistants grow, we encourage future work on interactive, rewriting-based approaches to MT 🫡
April 17, 2025 at 1:32 AM
7/ Taken together, we show that simpler texts are more translatable — and more broadly, #LLM-assisted input rewriting is a promising direction for improving translations! 💥
As LLM-based writing assistants grow, we encourage future work on interactive, rewriting-based approaches to MT 🫡
As LLM-based writing assistants grow, we encourage future work on interactive, rewriting-based approaches to MT 🫡
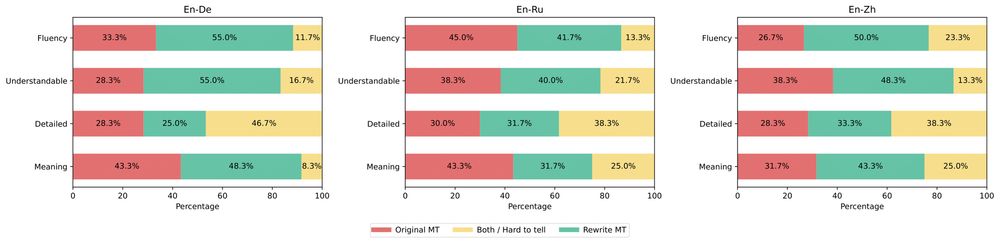
6/ 🧑⚖️ Do humans actually prefer translations of simplified inputs?
Yes! They rated these to be:
📝 More contextually appropriate
👁️ Easier to read
🤗 More comprehensible
compared to translations of original inputs!
Yes! They rated these to be:
📝 More contextually appropriate
👁️ Easier to read
🤗 More comprehensible
compared to translations of original inputs!
April 17, 2025 at 1:32 AM
6/ 🧑⚖️ Do humans actually prefer translations of simplified inputs?
Yes! They rated these to be:
📝 More contextually appropriate
👁️ Easier to read
🤗 More comprehensible
compared to translations of original inputs!
Yes! They rated these to be:
📝 More contextually appropriate
👁️ Easier to read
🤗 More comprehensible
compared to translations of original inputs!
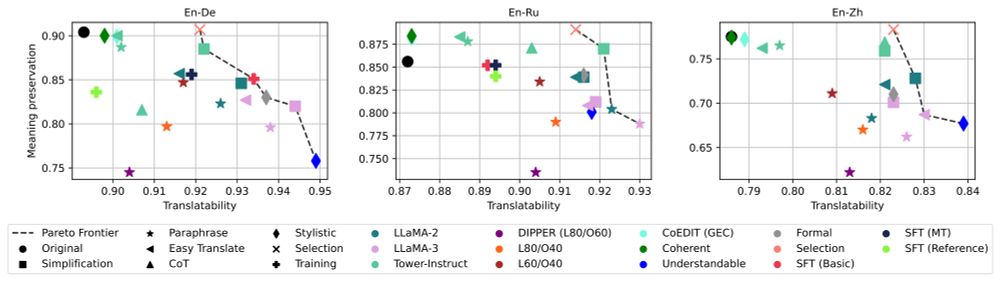
5/ What does input rewriting actually change? 🧐
Here are 3 key findings:
1️⃣ Better translatability trades-off meaning preservation
2️⃣ Simplification boosts both input & output readability 📖
3️⃣ Input rewriting > Output post-editing 🤯
Here are 3 key findings:
1️⃣ Better translatability trades-off meaning preservation
2️⃣ Simplification boosts both input & output readability 📖
3️⃣ Input rewriting > Output post-editing 🤯
April 17, 2025 at 1:32 AM
5/ What does input rewriting actually change? 🧐
Here are 3 key findings:
1️⃣ Better translatability trades-off meaning preservation
2️⃣ Simplification boosts both input & output readability 📖
3️⃣ Input rewriting > Output post-editing 🤯
Here are 3 key findings:
1️⃣ Better translatability trades-off meaning preservation
2️⃣ Simplification boosts both input & output readability 📖
3️⃣ Input rewriting > Output post-editing 🤯
4/ 🤔 Can we have more selective strategies?
Yes! By selecting rewrites based on translatability scores at inference time, we outperform all other methods 🔥
Yes! By selecting rewrites based on translatability scores at inference time, we outperform all other methods 🔥
April 17, 2025 at 1:32 AM
4/ 🤔 Can we have more selective strategies?
Yes! By selecting rewrites based on translatability scores at inference time, we outperform all other methods 🔥
Yes! By selecting rewrites based on translatability scores at inference time, we outperform all other methods 🔥