




Computer Vision and Machine Learning at MPI Informatics
@cvml.mpi-inf.mpg.de
Computer Vision and Machine Department at the Max Planck Institute for Informatics | https://www.mpi-inf.mpg.de/departments/computer-vision-and-machine-learning/
MVGBench: “A Comprehensive Benchmark for Multi-view Generation Models” — measures 3D consistency & image quality for fair comparisons.
By Xianghui Xie, Jan Eric Lenssen, Gerard Pons-Moll
Project: virtualhumans.mpi-inf.mpg.de/MVGBench/
By Xianghui Xie, Jan Eric Lenssen, Gerard Pons-Moll
Project: virtualhumans.mpi-inf.mpg.de/MVGBench/

October 19, 2025 at 7:49 AM
MVGBench: “A Comprehensive Benchmark for Multi-view Generation Models” — measures 3D consistency & image quality for fair comparisons.
By Xianghui Xie, Jan Eric Lenssen, Gerard Pons-Moll
Project: virtualhumans.mpi-inf.mpg.de/MVGBench/
By Xianghui Xie, Jan Eric Lenssen, Gerard Pons-Moll
Project: virtualhumans.mpi-inf.mpg.de/MVGBench/
VITAL: “More Understandable Feature Visualization via Distribution Alignment & Relevant Information Flow.” Fewer artifacts, more faithful internals, scales well.
By Ada Görgün, Bernt Schiele, Jonas Fischer
Project: adagorgun.github.io/VITAL-Project/
By Ada Görgün, Bernt Schiele, Jonas Fischer
Project: adagorgun.github.io/VITAL-Project/

October 19, 2025 at 7:49 AM
VITAL: “More Understandable Feature Visualization via Distribution Alignment & Relevant Information Flow.” Fewer artifacts, more faithful internals, scales well.
By Ada Görgün, Bernt Schiele, Jonas Fischer
Project: adagorgun.github.io/VITAL-Project/
By Ada Görgün, Bernt Schiele, Jonas Fischer
Project: adagorgun.github.io/VITAL-Project/
AIM (Highlight 🎉): “Amending Inherent Interpretability via Self-Supervised Masking.” - Promotes genuine features over spurious ones—no extra annotations.
By Eyad Alshami, Shashank Agnihotri, Bernt Schiele, Margret Keuper
By Eyad Alshami, Shashank Agnihotri, Bernt Schiele, Margret Keuper

October 19, 2025 at 7:49 AM
AIM (Highlight 🎉): “Amending Inherent Interpretability via Self-Supervised Masking.” - Promotes genuine features over spurious ones—no extra annotations.
By Eyad Alshami, Shashank Agnihotri, Bernt Schiele, Margret Keuper
By Eyad Alshami, Shashank Agnihotri, Bernt Schiele, Margret Keuper
DIY-SC: “Do It Yourself—Learning Semantic Correspondence from Pseudo-Labels.” - Light-weight adapter on DINOv2 / SD+DINOv2 → SOTA on SPair-71k w/o keypoints.
By O. Dünkel, T. Wimmer, C. Theobalt, C. Rupprecht, A. Kortylewski
Page: genintel.github.io/DIY-SC
By O. Dünkel, T. Wimmer, C. Theobalt, C. Rupprecht, A. Kortylewski
Page: genintel.github.io/DIY-SC

October 19, 2025 at 7:49 AM
DIY-SC: “Do It Yourself—Learning Semantic Correspondence from Pseudo-Labels.” - Light-weight adapter on DINOv2 / SD+DINOv2 → SOTA on SPair-71k w/o keypoints.
By O. Dünkel, T. Wimmer, C. Theobalt, C. Rupprecht, A. Kortylewski
Page: genintel.github.io/DIY-SC
By O. Dünkel, T. Wimmer, C. Theobalt, C. Rupprecht, A. Kortylewski
Page: genintel.github.io/DIY-SC
ICCV 2025 🌺 Aloha from Hawaii! MPI-INF (D2) is presenting 4 papers this year (one Highlight). Thread 👇

October 19, 2025 at 7:49 AM
ICCV 2025 🌺 Aloha from Hawaii! MPI-INF (D2) is presenting 4 papers this year (one Highlight). Thread 👇
4/ "🌀Spatial Reasoners for Continuous Variables in Any Domains" by @bartpog.bsky.social, @chriswewer.bsky.social, Bernt Schiele, and @janericlenssen.bsky.social (CODEML Workshop)
🔍 Software framework for training Spatial Reasoning Models in any domain
🔍 Software framework for training Spatial Reasoning Models in any domain
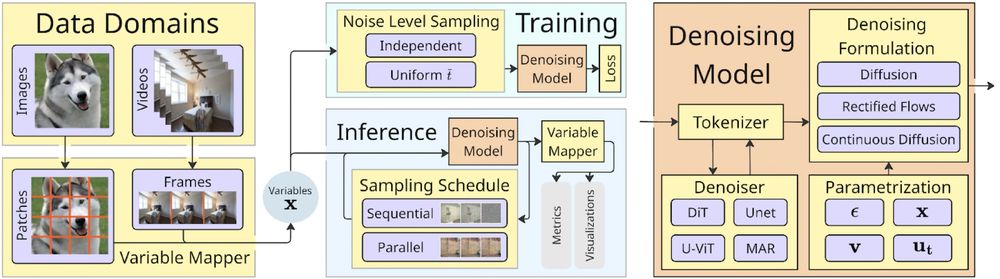
July 13, 2025 at 8:00 AM
4/ "🌀Spatial Reasoners for Continuous Variables in Any Domains" by @bartpog.bsky.social, @chriswewer.bsky.social, Bernt Schiele, and @janericlenssen.bsky.social (CODEML Workshop)
🔍 Software framework for training Spatial Reasoning Models in any domain
🔍 Software framework for training Spatial Reasoning Models in any domain
3/ "Pixel-level Certified Explanations via Randomized Smoothing" by @aanani.bsky.social, Tobias Lorenz, Mario Fritz, and Bernt Schiele
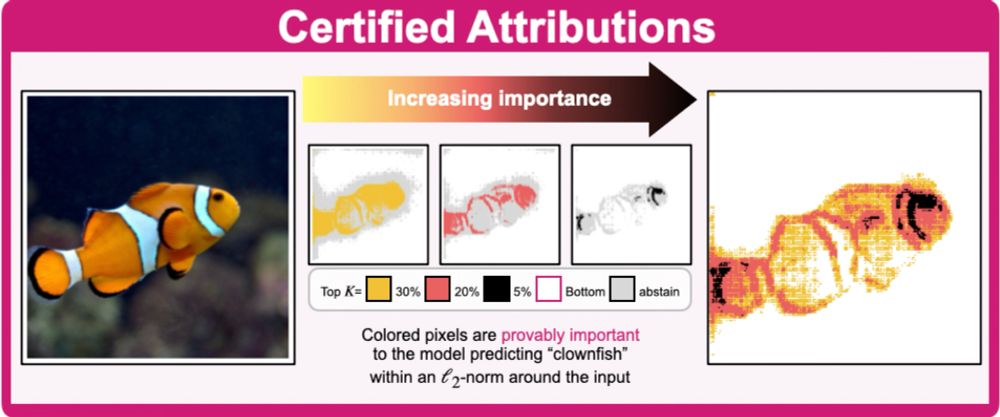
July 13, 2025 at 8:00 AM
3/ "Pixel-level Certified Explanations via Randomized Smoothing" by @aanani.bsky.social, Tobias Lorenz, Mario Fritz, and Bernt Schiele
2/ "Spatial Reasoning with Denoising Models" by @chriswewer.bsky.social, @bartpog.bsky.social, Bernt Schiele, and @janericlenssen.bsky.social
🔍 Can image generators solve visual Sudoku? Naively, no, with sequentialization and the correct order, they can!
🔍 Can image generators solve visual Sudoku? Naively, no, with sequentialization and the correct order, they can!
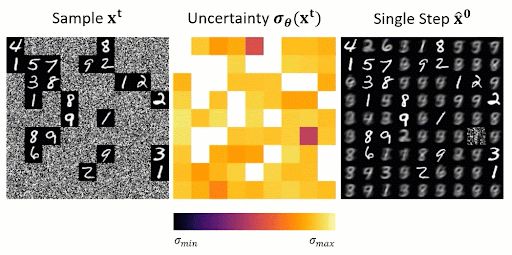
July 13, 2025 at 8:00 AM
2/ "Spatial Reasoning with Denoising Models" by @chriswewer.bsky.social, @bartpog.bsky.social, Bernt Schiele, and @janericlenssen.bsky.social
🔍 Can image generators solve visual Sudoku? Naively, no, with sequentialization and the correct order, they can!
🔍 Can image generators solve visual Sudoku? Naively, no, with sequentialization and the correct order, they can!
1/ "DCBM: Data-Efficient Visual Concept Bottleneck Models" by @katharinaprasse.bsky.social*, @patrickknab.bsky.social*, Sascha Marton, Christian Bartelt, and @margretkeuper.bsky.social
🔍 Data-efficient CBMs (DCBMs) generate concepts from image regions detected by segmentation or detection models
🔍 Data-efficient CBMs (DCBMs) generate concepts from image regions detected by segmentation or detection models
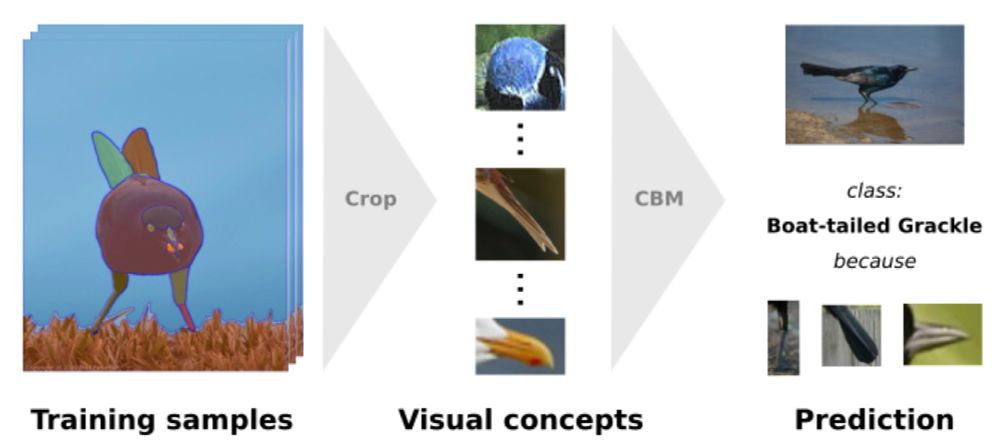
July 13, 2025 at 8:00 AM
1/ "DCBM: Data-Efficient Visual Concept Bottleneck Models" by @katharinaprasse.bsky.social*, @patrickknab.bsky.social*, Sascha Marton, Christian Bartelt, and @margretkeuper.bsky.social
🔍 Data-efficient CBMs (DCBMs) generate concepts from image regions detected by segmentation or detection models
🔍 Data-efficient CBMs (DCBMs) generate concepts from image regions detected by segmentation or detection models
Papers being presented from our group at #ICML2025!
Congratulations to all the authors! To know more, visit us in the poster sessions!
A 🧵with more details:
@icmlconf.bsky.social @mpi-inf.mpg.de
Congratulations to all the authors! To know more, visit us in the poster sessions!
A 🧵with more details:
@icmlconf.bsky.social @mpi-inf.mpg.de

July 13, 2025 at 8:00 AM
Papers being presented from our group at #ICML2025!
Congratulations to all the authors! To know more, visit us in the poster sessions!
A 🧵with more details:
@icmlconf.bsky.social @mpi-inf.mpg.de
Congratulations to all the authors! To know more, visit us in the poster sessions!
A 🧵with more details:
@icmlconf.bsky.social @mpi-inf.mpg.de
🎉 Congrats to Yue Fan on defending his PhD: "Improving Representation Learning from Data and Model Perspectives: Semi-Supervised Learning and Foundation Models" 🧑🎓
He is now at Genmo.ai as a Research Engineer working on video generation! 🚀
More: yue-fan.github.io
All the best!
He is now at Genmo.ai as a Research Engineer working on video generation! 🚀
More: yue-fan.github.io
All the best!

July 5, 2025 at 8:47 PM
🎉 Congrats to Yue Fan on defending his PhD: "Improving Representation Learning from Data and Model Perspectives: Semi-Supervised Learning and Foundation Models" 🧑🎓
He is now at Genmo.ai as a Research Engineer working on video generation! 🚀
More: yue-fan.github.io
All the best!
He is now at Genmo.ai as a Research Engineer working on video generation! 🚀
More: yue-fan.github.io
All the best!
A heart congratulations to the freshly minted Dr. Mattia Segù on successfully defending his PhD, Congratulazioni!!! 🎉 🎓.
His thesis is titled: Learning to Track: From Limited Supervision to Long-range Sequence Modeling
Checkout his web-page to learn more about his work: mattiasegu.github.io
His thesis is titled: Learning to Track: From Limited Supervision to Long-range Sequence Modeling
Checkout his web-page to learn more about his work: mattiasegu.github.io

June 26, 2025 at 9:55 AM
A heart congratulations to the freshly minted Dr. Mattia Segù on successfully defending his PhD, Congratulazioni!!! 🎉 🎓.
His thesis is titled: Learning to Track: From Limited Supervision to Long-range Sequence Modeling
Checkout his web-page to learn more about his work: mattiasegu.github.io
His thesis is titled: Learning to Track: From Limited Supervision to Long-range Sequence Modeling
Checkout his web-page to learn more about his work: mattiasegu.github.io
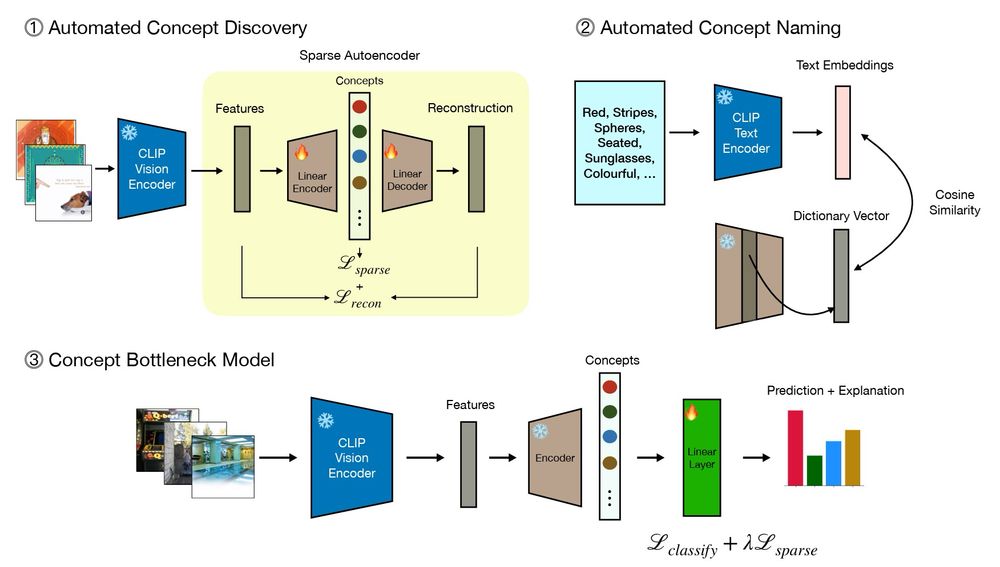
7/ 🧵 Discover-then-Name: Task-Agnostic Concept Bottlenecks via Automated Concept Discovery
Authors: S. Rao, S. Mahajan, M. Böhle, B. Schiele
🔍 Explore sparse autoencoders to automatically extract and name concepts, enabling performance improvements on downstream tasks.
📚 arxiv.org/abs/2407.14499
Authors: S. Rao, S. Mahajan, M. Böhle, B. Schiele
🔍 Explore sparse autoencoders to automatically extract and name concepts, enabling performance improvements on downstream tasks.
📚 arxiv.org/abs/2407.14499
June 11, 2025 at 8:44 PM
7/ 🧵 Discover-then-Name: Task-Agnostic Concept Bottlenecks via Automated Concept Discovery
Authors: S. Rao, S. Mahajan, M. Böhle, B. Schiele
🔍 Explore sparse autoencoders to automatically extract and name concepts, enabling performance improvements on downstream tasks.
📚 arxiv.org/abs/2407.14499
Authors: S. Rao, S. Mahajan, M. Böhle, B. Schiele
🔍 Explore sparse autoencoders to automatically extract and name concepts, enabling performance improvements on downstream tasks.
📚 arxiv.org/abs/2407.14499
6/ 🧵 3D-WAG: Wavelet-Guided Autoregressive Generation for 3D Shapes
Authors: T. Medi*, A. Rampini, P. Reddy, P. K. Jayaraman, M. Keuper
🔍 3D-WAG introduces wavelet-guided autoregressive generation for 3D shapes, aiming for better geometry modeling.
📚 arxiv.org/abs/2411.19037
Authors: T. Medi*, A. Rampini, P. Reddy, P. K. Jayaraman, M. Keuper
🔍 3D-WAG introduces wavelet-guided autoregressive generation for 3D shapes, aiming for better geometry modeling.
📚 arxiv.org/abs/2411.19037

June 11, 2025 at 8:44 PM
6/ 🧵 3D-WAG: Wavelet-Guided Autoregressive Generation for 3D Shapes
Authors: T. Medi*, A. Rampini, P. Reddy, P. K. Jayaraman, M. Keuper
🔍 3D-WAG introduces wavelet-guided autoregressive generation for 3D shapes, aiming for better geometry modeling.
📚 arxiv.org/abs/2411.19037
Authors: T. Medi*, A. Rampini, P. Reddy, P. K. Jayaraman, M. Keuper
🔍 3D-WAG introduces wavelet-guided autoregressive generation for 3D shapes, aiming for better geometry modeling.
📚 arxiv.org/abs/2411.19037
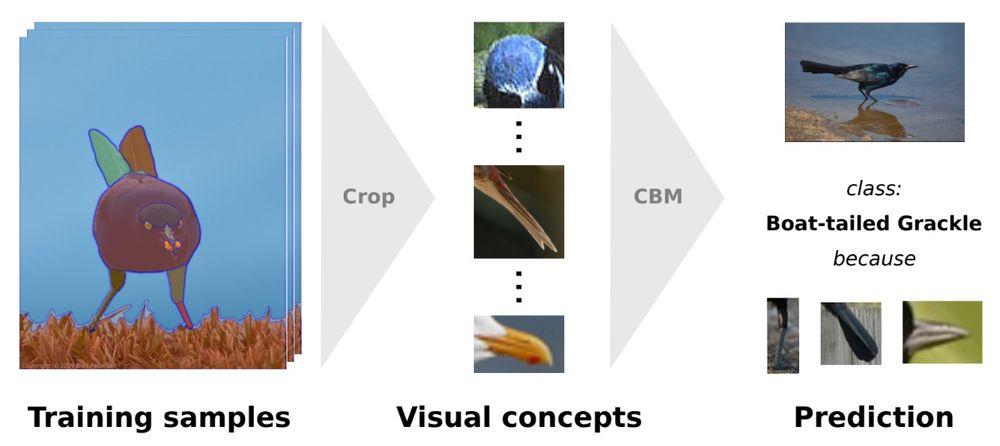
5/ 🧵 Data-Efficient Visual Concept Bottleneck Models
Authors: K. Prasse, P. Knab, S. Marton, C. Bartelt, M. Keuper
🔍 Introducing data-efficient visual concept bottleneck models for improved explainability in CV.
📚 arxiv.org/abs/2412.11576
Authors: K. Prasse, P. Knab, S. Marton, C. Bartelt, M. Keuper
🔍 Introducing data-efficient visual concept bottleneck models for improved explainability in CV.
📚 arxiv.org/abs/2412.11576
June 11, 2025 at 8:44 PM
5/ 🧵 Data-Efficient Visual Concept Bottleneck Models
Authors: K. Prasse, P. Knab, S. Marton, C. Bartelt, M. Keuper
🔍 Introducing data-efficient visual concept bottleneck models for improved explainability in CV.
📚 arxiv.org/abs/2412.11576
Authors: K. Prasse, P. Knab, S. Marton, C. Bartelt, M. Keuper
🔍 Introducing data-efficient visual concept bottleneck models for improved explainability in CV.
📚 arxiv.org/abs/2412.11576
4/ 🧵 HD-VILA-Caption: A Diverse Video-Text Dataset Derived from ASR Narrations
By: M. Saleh, N. Shvetsova, A. Kukleva, H. Kuehne, B. Schiele
🔍 HD-VILA-Caption is a large-scale, diverse video-text dataset with 10M high-quality captions, built from ASR subtitles for video-language pretraining.
By: M. Saleh, N. Shvetsova, A. Kukleva, H. Kuehne, B. Schiele
🔍 HD-VILA-Caption is a large-scale, diverse video-text dataset with 10M high-quality captions, built from ASR subtitles for video-language pretraining.

June 11, 2025 at 8:44 PM
4/ 🧵 HD-VILA-Caption: A Diverse Video-Text Dataset Derived from ASR Narrations
By: M. Saleh, N. Shvetsova, A. Kukleva, H. Kuehne, B. Schiele
🔍 HD-VILA-Caption is a large-scale, diverse video-text dataset with 10M high-quality captions, built from ASR subtitles for video-language pretraining.
By: M. Saleh, N. Shvetsova, A. Kukleva, H. Kuehne, B. Schiele
🔍 HD-VILA-Caption is a large-scale, diverse video-text dataset with 10M high-quality captions, built from ASR subtitles for video-language pretraining.
3/ 🧵 Corner Cases: How Size and Position of Objects Challenge ImageNet-Trained Models
By: M. Fatima, S. Jung, M. Keuper
🔍 Exploring how object size & position affect ImageNet-trained models and lead to performance issues.
📚 openreview.net/forum?id=B6l...
By: M. Fatima, S. Jung, M. Keuper
🔍 Exploring how object size & position affect ImageNet-trained models and lead to performance issues.
📚 openreview.net/forum?id=B6l...

June 11, 2025 at 8:44 PM
3/ 🧵 Corner Cases: How Size and Position of Objects Challenge ImageNet-Trained Models
By: M. Fatima, S. Jung, M. Keuper
🔍 Exploring how object size & position affect ImageNet-trained models and lead to performance issues.
📚 openreview.net/forum?id=B6l...
By: M. Fatima, S. Jung, M. Keuper
🔍 Exploring how object size & position affect ImageNet-trained models and lead to performance issues.
📚 openreview.net/forum?id=B6l...
2/ 🧵 Are Synthetic Corruptions A Reliable Proxy For Real-World Corruptions?
By: S. Agnihotri, D. Schader, N. Sharei, M.E. Kaçar, M. Keuper
🔍 Investigating if synthetic corruptions can be a reliable proxy for real-world ones, and understanding their limitations.
📚https://www.arxiv.org/abs/2505.04835
By: S. Agnihotri, D. Schader, N. Sharei, M.E. Kaçar, M. Keuper
🔍 Investigating if synthetic corruptions can be a reliable proxy for real-world ones, and understanding their limitations.
📚https://www.arxiv.org/abs/2505.04835

June 11, 2025 at 8:44 PM
2/ 🧵 Are Synthetic Corruptions A Reliable Proxy For Real-World Corruptions?
By: S. Agnihotri, D. Schader, N. Sharei, M.E. Kaçar, M. Keuper
🔍 Investigating if synthetic corruptions can be a reliable proxy for real-world ones, and understanding their limitations.
📚https://www.arxiv.org/abs/2505.04835
By: S. Agnihotri, D. Schader, N. Sharei, M.E. Kaçar, M. Keuper
🔍 Investigating if synthetic corruptions can be a reliable proxy for real-world ones, and understanding their limitations.
📚https://www.arxiv.org/abs/2505.04835
1/ 🧵 DispBench: Benchmarking Disparity Estimation to Synthetic Corruptions
By: S. Agnihotri, A. Ansari, A. Dackermann, F. Rösch, M. Keuper
🔍 A benchmark & tool for testing disparity estimation methods against synthetic corruptions & attacks.
📚 arxiv.org/abs/2505.050...
By: S. Agnihotri, A. Ansari, A. Dackermann, F. Rösch, M. Keuper
🔍 A benchmark & tool for testing disparity estimation methods against synthetic corruptions & attacks.
📚 arxiv.org/abs/2505.050...

June 11, 2025 at 8:44 PM
1/ 🧵 DispBench: Benchmarking Disparity Estimation to Synthetic Corruptions
By: S. Agnihotri, A. Ansari, A. Dackermann, F. Rösch, M. Keuper
🔍 A benchmark & tool for testing disparity estimation methods against synthetic corruptions & attacks.
📚 arxiv.org/abs/2505.050...
By: S. Agnihotri, A. Ansari, A. Dackermann, F. Rösch, M. Keuper
🔍 A benchmark & tool for testing disparity estimation methods against synthetic corruptions & attacks.
📚 arxiv.org/abs/2505.050...
Thread: Workshop Papers from Our Lab at CVPR 2025! 🚀
👏 Huge congrats to our members on these workshop paper acceptances! Excited to see their work at #CVPR2025 🌟
#MPI-INF #D2 #Workshop #AI #ComputerVision #PhD
@mpi-inf.mpg.de
👏 Huge congrats to our members on these workshop paper acceptances! Excited to see their work at #CVPR2025 🌟
#MPI-INF #D2 #Workshop #AI #ComputerVision #PhD
@mpi-inf.mpg.de

June 11, 2025 at 8:44 PM
Thread: Workshop Papers from Our Lab at CVPR 2025! 🚀
👏 Huge congrats to our members on these workshop paper acceptances! Excited to see their work at #CVPR2025 🌟
#MPI-INF #D2 #Workshop #AI #ComputerVision #PhD
@mpi-inf.mpg.de
👏 Huge congrats to our members on these workshop paper acceptances! Excited to see their work at #CVPR2025 🌟
#MPI-INF #D2 #Workshop #AI #ComputerVision #PhD
@mpi-inf.mpg.de
5/ 🧵 Number it: Temporal Grounding Like Manga
Authors: Y. Wu*, X. Hu*, Y. Sun, Y. Zhou, W. Zhu, F. Rao, B. Schiele, X. Yang
🔍 NumPro enhances Video-LLMs in temporal grounding with red number markers, like flipping manga!
📚 arxiv.org/abs/2411.10332
Authors: Y. Wu*, X. Hu*, Y. Sun, Y. Zhou, W. Zhu, F. Rao, B. Schiele, X. Yang
🔍 NumPro enhances Video-LLMs in temporal grounding with red number markers, like flipping manga!
📚 arxiv.org/abs/2411.10332

June 11, 2025 at 8:20 PM
5/ 🧵 Number it: Temporal Grounding Like Manga
Authors: Y. Wu*, X. Hu*, Y. Sun, Y. Zhou, W. Zhu, F. Rao, B. Schiele, X. Yang
🔍 NumPro enhances Video-LLMs in temporal grounding with red number markers, like flipping manga!
📚 arxiv.org/abs/2411.10332
Authors: Y. Wu*, X. Hu*, Y. Sun, Y. Zhou, W. Zhu, F. Rao, B. Schiele, X. Yang
🔍 NumPro enhances Video-LLMs in temporal grounding with red number markers, like flipping manga!
📚 arxiv.org/abs/2411.10332
4/ 🧵 PersonaHOI: Face Personalization in Human-Object Interaction
By: X. Hu*, H. Wang*, J.E. Lenssen, B. Schiele
🔍 PersonaHOI is the first training-free framework to generate human-object interactions with personalized faces.
📚 arxiv.org/abs/2501.05823
By: X. Hu*, H. Wang*, J.E. Lenssen, B. Schiele
🔍 PersonaHOI is the first training-free framework to generate human-object interactions with personalized faces.
📚 arxiv.org/abs/2501.05823

June 11, 2025 at 8:20 PM
4/ 🧵 PersonaHOI: Face Personalization in Human-Object Interaction
By: X. Hu*, H. Wang*, J.E. Lenssen, B. Schiele
🔍 PersonaHOI is the first training-free framework to generate human-object interactions with personalized faces.
📚 arxiv.org/abs/2501.05823
By: X. Hu*, H. Wang*, J.E. Lenssen, B. Schiele
🔍 PersonaHOI is the first training-free framework to generate human-object interactions with personalized faces.
📚 arxiv.org/abs/2501.05823
3/ 🧵 MEt3R: Measuring Multi-View Consistency
By: M. Asim, C. Wewer, T. Wimmer, B. Schiele, J.E. Lenssen
🔍 MEt3R is a metric for multi-view consistency in generated image sequences & videos.
📚 arxiv.org/abs/2501.06336
🔗 geometric-rl.mpi-inf.mpg.de/met3r/
By: M. Asim, C. Wewer, T. Wimmer, B. Schiele, J.E. Lenssen
🔍 MEt3R is a metric for multi-view consistency in generated image sequences & videos.
📚 arxiv.org/abs/2501.06336
🔗 geometric-rl.mpi-inf.mpg.de/met3r/

June 11, 2025 at 8:20 PM
3/ 🧵 MEt3R: Measuring Multi-View Consistency
By: M. Asim, C. Wewer, T. Wimmer, B. Schiele, J.E. Lenssen
🔍 MEt3R is a metric for multi-view consistency in generated image sequences & videos.
📚 arxiv.org/abs/2501.06336
🔗 geometric-rl.mpi-inf.mpg.de/met3r/
By: M. Asim, C. Wewer, T. Wimmer, B. Schiele, J.E. Lenssen
🔍 MEt3R is a metric for multi-view consistency in generated image sequences & videos.
📚 arxiv.org/abs/2501.06336
🔗 geometric-rl.mpi-inf.mpg.de/met3r/
2/ 🧵 Unbiasing through Textual Descriptions
By: N. Shvetsova, A. Nagrani, B. Schiele, H. Kuehne, C. Rupprecht
🔍 UTD uses VLMs/LLMs to mitigate representation bias in video benchmarks, ensuring fairer evaluations.
📚 arxiv.org/abs/2503.18637
📱 @ninashv.bsky.social @hildekuehne.bsky.social
By: N. Shvetsova, A. Nagrani, B. Schiele, H. Kuehne, C. Rupprecht
🔍 UTD uses VLMs/LLMs to mitigate representation bias in video benchmarks, ensuring fairer evaluations.
📚 arxiv.org/abs/2503.18637
📱 @ninashv.bsky.social @hildekuehne.bsky.social

June 11, 2025 at 8:20 PM
2/ 🧵 Unbiasing through Textual Descriptions
By: N. Shvetsova, A. Nagrani, B. Schiele, H. Kuehne, C. Rupprecht
🔍 UTD uses VLMs/LLMs to mitigate representation bias in video benchmarks, ensuring fairer evaluations.
📚 arxiv.org/abs/2503.18637
📱 @ninashv.bsky.social @hildekuehne.bsky.social
By: N. Shvetsova, A. Nagrani, B. Schiele, H. Kuehne, C. Rupprecht
🔍 UTD uses VLMs/LLMs to mitigate representation bias in video benchmarks, ensuring fairer evaluations.
📚 arxiv.org/abs/2503.18637
📱 @ninashv.bsky.social @hildekuehne.bsky.social
1/ 🧵 Test-Time Visual In-Context Tuning
By: J. Xie, A. Tonioni, N. Rauschmayr, F. Tombari, B. Schiele
🔍 VICT adapts VICL models with a single test sample, enhancing generalizability for unseen tasks.
📚 arxiv.org/abs/2503.21777
🔗 github.com/Jiahao000/VICT
By: J. Xie, A. Tonioni, N. Rauschmayr, F. Tombari, B. Schiele
🔍 VICT adapts VICL models with a single test sample, enhancing generalizability for unseen tasks.
📚 arxiv.org/abs/2503.21777
🔗 github.com/Jiahao000/VICT

June 11, 2025 at 8:20 PM
1/ 🧵 Test-Time Visual In-Context Tuning
By: J. Xie, A. Tonioni, N. Rauschmayr, F. Tombari, B. Schiele
🔍 VICT adapts VICL models with a single test sample, enhancing generalizability for unseen tasks.
📚 arxiv.org/abs/2503.21777
🔗 github.com/Jiahao000/VICT
By: J. Xie, A. Tonioni, N. Rauschmayr, F. Tombari, B. Schiele
🔍 VICT adapts VICL models with a single test sample, enhancing generalizability for unseen tasks.
📚 arxiv.org/abs/2503.21777
🔗 github.com/Jiahao000/VICT