




Chris Offner
@chrisoffner3d.bsky.social
Student Researcher @ RAI Institute, MSc CS Student @ ETH Zurich
visual computing, 3D vision, spatial AI, machine learning, robot perception.
📍Zurich, Switzerland
visual computing, 3D vision, spatial AI, machine learning, robot perception.
📍Zurich, Switzerland
Great video on the convergent evolution from hierarchical military command structures to cybernetics to centralized AI coordination across political ideologies:
www.youtube.com/watch?v=mayo...
www.youtube.com/watch?v=mayo...
August 23, 2025 at 11:07 AM
Great video on the convergent evolution from hierarchical military command structures to cybernetics to centralized AI coordination across political ideologies:
www.youtube.com/watch?v=mayo...
www.youtube.com/watch?v=mayo...
"It is beautiful. It is elegant. Does it work well in practice? Not really. This is often the caveat we face in research: the things that are beautiful don't work and the things that work are not beautiful." – Daniel Cremers
August 22, 2025 at 11:55 AM
"It is beautiful. It is elegant. Does it work well in practice? Not really. This is often the caveat we face in research: the things that are beautiful don't work and the things that work are not beautiful." – Daniel Cremers
"As roboticists and computer vision people [outside of big tech], do we have to just wait for the next foundation model?"
I share the frustration. It's disempowering when most major progress recently is downstream of "foundation models" that you don't have the compute or data to train yourself.
I share the frustration. It's disempowering when most major progress recently is downstream of "foundation models" that you don't have the compute or data to train yourself.
August 21, 2025 at 5:37 PM
"As roboticists and computer vision people [outside of big tech], do we have to just wait for the next foundation model?"
I share the frustration. It's disempowering when most major progress recently is downstream of "foundation models" that you don't have the compute or data to train yourself.
I share the frustration. It's disempowering when most major progress recently is downstream of "foundation models" that you don't have the compute or data to train yourself.
Sort of, but DINOv3 also seems to (inadvertently?) point towards the limits of pure scaling.
x.com/chrisoffner3...
x.com/chrisoffner3...

August 19, 2025 at 7:34 PM
Sort of, but DINOv3 also seems to (inadvertently?) point towards the limits of pure scaling.
x.com/chrisoffner3...
x.com/chrisoffner3...
Yay, DINOv3 is out!
SigLIP (VLMs) and DINO are two competing paradigms for image encoders.
My intuition is that joint vision-language modeling works great for semantic problems but may be too coarse for geometry problems like SfM or SLAM.
Most animals navigate 3D space perfectly without language.
SigLIP (VLMs) and DINO are two competing paradigms for image encoders.
My intuition is that joint vision-language modeling works great for semantic problems but may be too coarse for geometry problems like SfM or SLAM.
Most animals navigate 3D space perfectly without language.


August 14, 2025 at 5:59 PM
Yay, DINOv3 is out!
SigLIP (VLMs) and DINO are two competing paradigms for image encoders.
My intuition is that joint vision-language modeling works great for semantic problems but may be too coarse for geometry problems like SfM or SLAM.
Most animals navigate 3D space perfectly without language.
SigLIP (VLMs) and DINO are two competing paradigms for image encoders.
My intuition is that joint vision-language modeling works great for semantic problems but may be too coarse for geometry problems like SfM or SLAM.
Most animals navigate 3D space perfectly without language.
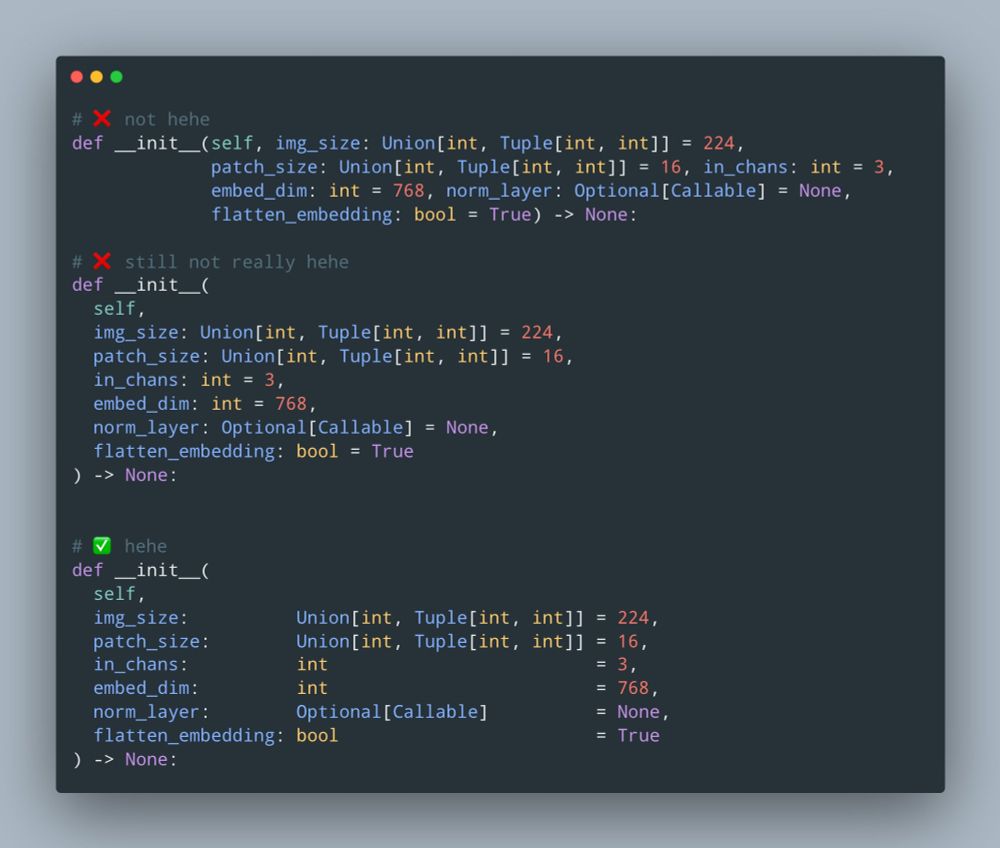
I must note that, while the typing is good, the formatting in the above jaxtyping example is still "not hehe." x.com/chrisoffner3...
June 23, 2025 at 6:01 PM
I must note that, while the typing is good, the formatting in the above jaxtyping example is still "not hehe." x.com/chrisoffner3...
Agreed, but the remedy for bad type hints is not no type hints but good type hints. github.com/patrick-kidg...

June 23, 2025 at 5:55 PM
Agreed, but the remedy for bad type hints is not no type hints but good type hints. github.com/patrick-kidg...
My X feed's reaction to Dario Amodei's recent interviews.
May 31, 2025 at 6:23 PM
My X feed's reaction to Dario Amodei's recent interviews.
Ambitious projects are happening in Zurich’s AI scene.
www.theverge.com/news/669238/...
www.theverge.com/news/669238/...

May 19, 2025 at 5:50 AM
Ambitious projects are happening in Zurich’s AI scene.
www.theverge.com/news/669238/...
www.theverge.com/news/669238/...
kids these days, am I right? @clairebraeuer.bsky.social

May 2, 2025 at 11:39 AM
kids these days, am I right? @clairebraeuer.bsky.social
When I try it, it messes up the image on the very first try, creating a vertically repeating image. If I then crop it and try a second time, it refuses. 🤷♂️


May 1, 2025 at 5:42 AM
When I try it, it messes up the image on the very first try, creating a vertically repeating image. If I then crop it and try a second time, it refuses. 🤷♂️
Repeating "Create the exact replica of this image, don't change a thing" 101 times
(from www.reddit.com/r/ChatGPT/co...)
(from www.reddit.com/r/ChatGPT/co...)
May 1, 2025 at 5:12 AM
Repeating "Create the exact replica of this image, don't change a thing" 101 times
(from www.reddit.com/r/ChatGPT/co...)
(from www.reddit.com/r/ChatGPT/co...)
“Another, this time asking for the image 5 seconds into the future” (from x.com/indian_brons...)
April 29, 2025 at 4:28 AM
“Another, this time asking for the image 5 seconds into the future” (from x.com/indian_brons...)
“GPT-image feedback loop, asking the machine to replicate the image without changing anything.” (from x.com/indian_brons...)
April 29, 2025 at 4:28 AM
“GPT-image feedback loop, asking the machine to replicate the image without changing anything.” (from x.com/indian_brons...)
Wisdom is knowing when to rely on science and when to believe in a bit of magic. Tonight it’s time for the Böögg!

April 28, 2025 at 8:13 AM
Wisdom is knowing when to rely on science and when to believe in a bit of magic. Tonight it’s time for the Böögg!
I guess she should’ve worked on Grok instead.
techcrunch.com/2025/04/25/a...
techcrunch.com/2025/04/25/a...

April 26, 2025 at 5:34 AM
I guess she should’ve worked on Grok instead.
techcrunch.com/2025/04/25/a...
techcrunch.com/2025/04/25/a...
April 23, 2025 at 3:10 PM
AI for Good vs. AI for Evil

April 23, 2025 at 6:46 AM
AI for Good vs. AI for Evil
Former F.B.I. special agent and current assistant dean of Yale’s Jackson School of Global Affairs, Asha Rangappa, explains how fucked things are.
April 20, 2025 at 6:19 AM
Former F.B.I. special agent and current assistant dean of Yale’s Jackson School of Global Affairs, Asha Rangappa, explains how fucked things are.
pattern matchers gonna pattern match

April 19, 2025 at 10:45 AM
pattern matchers gonna pattern match


April 17, 2025 at 6:18 AM
What does this “€ 178,347 Monthly Contribution” count? Does this include the corporate memberships? Because that is very little money to support software development.

April 15, 2025 at 5:40 AM
What does this “€ 178,347 Monthly Contribution” count? Does this include the corporate memberships? Because that is very little money to support software development.
“Who do you think you are? Who do you think you are? You think you’re special? You think you just float directly above all those you encounter because you are beautiful? Because you are educated? You’re just a tramp. Shh. You’re just a lady of the night.”

April 12, 2025 at 5:06 AM
“Who do you think you are? Who do you think you are? You think you’re special? You think you just float directly above all those you encounter because you are beautiful? Because you are educated? You’re just a tramp. Shh. You’re just a lady of the night.”
Finally reaching my target demographic.

April 5, 2025 at 6:55 AM
Finally reaching my target demographic.
And they’re used to encode camera geometry.

April 4, 2025 at 5:53 AM
And they’re used to encode camera geometry.