




Chau Minh Pham
@chautmpham.bsky.social
PhD student @umdcs | Long-form Narrative Generation & Analysis | Intern @AdobeResearch @MSFTResearch | https://chtmp223.github.io
Room for improvement:
🔧 Frankentexts struggle with smooth narrative transitions and grammar, as noted by human annotators.
🔩 Non-fiction versions are coherent and faithful but tend to be overly anecdotal and lack factual accuracy.
🔧 Frankentexts struggle with smooth narrative transitions and grammar, as noted by human annotators.
🔩 Non-fiction versions are coherent and faithful but tend to be overly anecdotal and lack factual accuracy.

June 3, 2025 at 3:09 PM
Room for improvement:
🔧 Frankentexts struggle with smooth narrative transitions and grammar, as noted by human annotators.
🔩 Non-fiction versions are coherent and faithful but tend to be overly anecdotal and lack factual accuracy.
🔧 Frankentexts struggle with smooth narrative transitions and grammar, as noted by human annotators.
🔩 Non-fiction versions are coherent and faithful but tend to be overly anecdotal and lack factual accuracy.
Takeaway 2: Our controllable generation process provides a sandbox for human-AI co-writing research, with adjustable proportion, length, and diversity of human excerpts.
👫 Models can follow copy constraints, which is a proxy for % of human writing in co-authored texts.
👫 Models can follow copy constraints, which is a proxy for % of human writing in co-authored texts.

June 3, 2025 at 3:09 PM
Takeaway 2: Our controllable generation process provides a sandbox for human-AI co-writing research, with adjustable proportion, length, and diversity of human excerpts.
👫 Models can follow copy constraints, which is a proxy for % of human writing in co-authored texts.
👫 Models can follow copy constraints, which is a proxy for % of human writing in co-authored texts.
Takeaway 1: Frankentexts don’t fit into the "AI vs. human" binary.
📉 Binary detectors misclassify them as human-written
👨👩👧 Humans can detect AI involvement more often
🔍 Mixed-authorship tools (Pangram) help, but still catch only 59%
We need better tools for this gray zone.
📉 Binary detectors misclassify them as human-written
👨👩👧 Humans can detect AI involvement more often
🔍 Mixed-authorship tools (Pangram) help, but still catch only 59%
We need better tools for this gray zone.

June 3, 2025 at 3:09 PM
Takeaway 1: Frankentexts don’t fit into the "AI vs. human" binary.
📉 Binary detectors misclassify them as human-written
👨👩👧 Humans can detect AI involvement more often
🔍 Mixed-authorship tools (Pangram) help, but still catch only 59%
We need better tools for this gray zone.
📉 Binary detectors misclassify them as human-written
👨👩👧 Humans can detect AI involvement more often
🔍 Mixed-authorship tools (Pangram) help, but still catch only 59%
We need better tools for this gray zone.
Automatic evaluation on 100 Frankentexts using LLM judges, text detectors, and a ROUGE-L-based metric shows that:
💪 Gemini-2.5-Pro, Claude-3.5-Sonnet, and R1 can generate Frankentexts that are up to 90% relevant, 70% coherent, and 75% traceable to the original human writings.
💪 Gemini-2.5-Pro, Claude-3.5-Sonnet, and R1 can generate Frankentexts that are up to 90% relevant, 70% coherent, and 75% traceable to the original human writings.

June 3, 2025 at 3:09 PM
Automatic evaluation on 100 Frankentexts using LLM judges, text detectors, and a ROUGE-L-based metric shows that:
💪 Gemini-2.5-Pro, Claude-3.5-Sonnet, and R1 can generate Frankentexts that are up to 90% relevant, 70% coherent, and 75% traceable to the original human writings.
💪 Gemini-2.5-Pro, Claude-3.5-Sonnet, and R1 can generate Frankentexts that are up to 90% relevant, 70% coherent, and 75% traceable to the original human writings.
Frankentext generation presents an instruction-following task that challenges the limits of controllable generation, requiring each model to:
1️⃣ Produce a draft by selecting & combining human-written passages.
2️⃣ Iteratively revise the draft while maintaining a copy ratio.
1️⃣ Produce a draft by selecting & combining human-written passages.
2️⃣ Iteratively revise the draft while maintaining a copy ratio.

June 3, 2025 at 3:09 PM
Frankentext generation presents an instruction-following task that challenges the limits of controllable generation, requiring each model to:
1️⃣ Produce a draft by selecting & combining human-written passages.
2️⃣ Iteratively revise the draft while maintaining a copy ratio.
1️⃣ Produce a draft by selecting & combining human-written passages.
2️⃣ Iteratively revise the draft while maintaining a copy ratio.
🤔 What if you gave an LLM thousands of random human-written paragraphs and told it to write something new -- while copying 90% of its output from those texts?
🧟 You get what we call a Frankentext!
💡 Frankentexts are surprisingly coherent and tough for AI detectors to flag.
🧟 You get what we call a Frankentext!
💡 Frankentexts are surprisingly coherent and tough for AI detectors to flag.

June 3, 2025 at 3:09 PM
🤔 What if you gave an LLM thousands of random human-written paragraphs and told it to write something new -- while copying 90% of its output from those texts?
🧟 You get what we call a Frankentext!
💡 Frankentexts are surprisingly coherent and tough for AI detectors to flag.
🧟 You get what we call a Frankentext!
💡 Frankentexts are surprisingly coherent and tough for AI detectors to flag.
Areas for improvement:
🔩 Larger models (>=70B) may benefit from book-level reasoning—our chapter-level model outperforms the book-level version, indicating that smaller models might struggle with book-level reasoning.
🔩 Fine-tuned models struggle to verify False claims.
🔩 Larger models (>=70B) may benefit from book-level reasoning—our chapter-level model outperforms the book-level version, indicating that smaller models might struggle with book-level reasoning.
🔩 Fine-tuned models struggle to verify False claims.

February 21, 2025 at 4:25 PM
Areas for improvement:
🔩 Larger models (>=70B) may benefit from book-level reasoning—our chapter-level model outperforms the book-level version, indicating that smaller models might struggle with book-level reasoning.
🔩 Fine-tuned models struggle to verify False claims.
🔩 Larger models (>=70B) may benefit from book-level reasoning—our chapter-level model outperforms the book-level version, indicating that smaller models might struggle with book-level reasoning.
🔩 Fine-tuned models struggle to verify False claims.
Our fine-tuned models produce more informative chain-of-thought reasoning compared to baseline models. Each chain of thoughts has:
📍 Source chapter of each event in the claim
🤝 Relationships between these events
📖 Explanation on how this supports/contradicts the claim.
📍 Source chapter of each event in the claim
🤝 Relationships between these events
📖 Explanation on how this supports/contradicts the claim.

February 21, 2025 at 4:25 PM
Our fine-tuned models produce more informative chain-of-thought reasoning compared to baseline models. Each chain of thoughts has:
📍 Source chapter of each event in the claim
🤝 Relationships between these events
📖 Explanation on how this supports/contradicts the claim.
📍 Source chapter of each event in the claim
🤝 Relationships between these events
📖 Explanation on how this supports/contradicts the claim.
🔧 We fine-tune Qwen2.5-7B-Instruct, LLaMA-3.1-8B-Instruct, and Prolong-512K-8B-Instruct on our dataset.
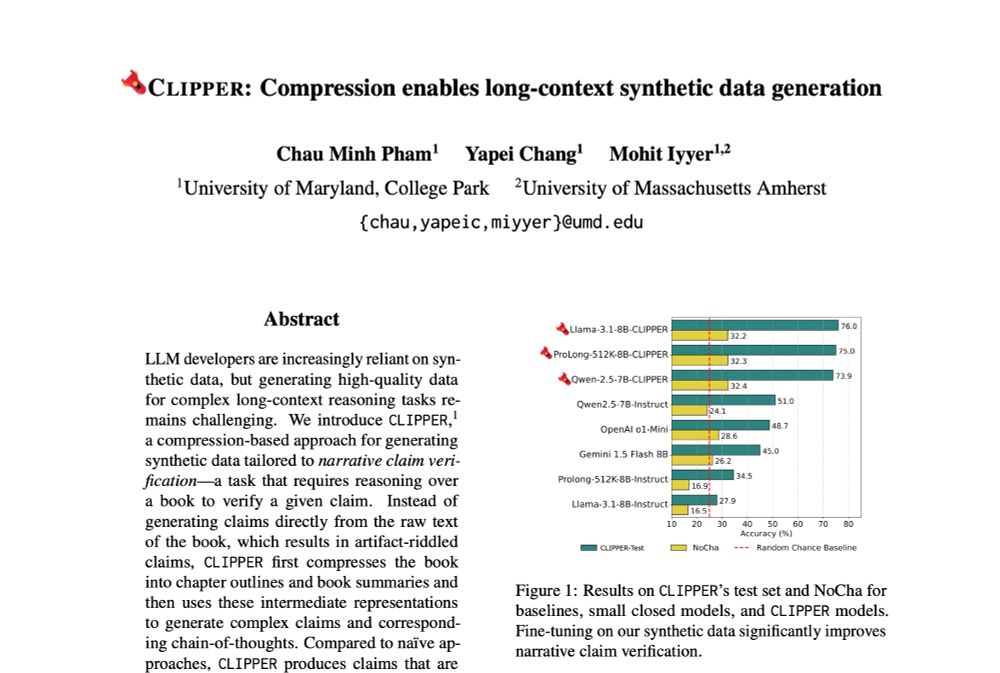
📈 The fine-tuned LLaMA model boosts test performance from 28% to 76% and set a new state-of-the-art for <10B on NoCha, a long-form claim verification benchmark!
📈 The fine-tuned LLaMA model boosts test performance from 28% to 76% and set a new state-of-the-art for <10B on NoCha, a long-form claim verification benchmark!

February 21, 2025 at 4:25 PM
🔧 We fine-tune Qwen2.5-7B-Instruct, LLaMA-3.1-8B-Instruct, and Prolong-512K-8B-Instruct on our dataset.
📈 The fine-tuned LLaMA model boosts test performance from 28% to 76% and set a new state-of-the-art for <10B on NoCha, a long-form claim verification benchmark!
📈 The fine-tuned LLaMA model boosts test performance from 28% to 76% and set a new state-of-the-art for <10B on NoCha, a long-form claim verification benchmark!
💽 We use CLIPPER to create a dataset of 19K synthetic book claims paired with chain-of-thought explanations.
✅ Our claims suffer from fewer errors like misattributions, duplications, and invalid claims compared to naïve approaches.
✅ Our claims suffer from fewer errors like misattributions, duplications, and invalid claims compared to naïve approaches.

February 21, 2025 at 4:25 PM
💽 We use CLIPPER to create a dataset of 19K synthetic book claims paired with chain-of-thought explanations.
✅ Our claims suffer from fewer errors like misattributions, duplications, and invalid claims compared to naïve approaches.
✅ Our claims suffer from fewer errors like misattributions, duplications, and invalid claims compared to naïve approaches.
Instead of generating claims directly from full-length books—which results in noisy data—CLIPPER work in two stages:
1️⃣ Books are compressed into chapter outlines and summaries.
2️⃣ Grounded and complex claims are then generated based on these compressed representations.
1️⃣ Books are compressed into chapter outlines and summaries.
2️⃣ Grounded and complex claims are then generated based on these compressed representations.

February 21, 2025 at 4:25 PM
Instead of generating claims directly from full-length books—which results in noisy data—CLIPPER work in two stages:
1️⃣ Books are compressed into chapter outlines and summaries.
2️⃣ Grounded and complex claims are then generated based on these compressed representations.
1️⃣ Books are compressed into chapter outlines and summaries.
2️⃣ Grounded and complex claims are then generated based on these compressed representations.
⚠️Current methods for generating instruction-following data fall short for long-range reasoning tasks like narrative claim verification.
We present CLIPPER ✂️, a compression-based pipeline that produces grounded instructions for ~$0.5 each, 34x cheaper than human annotations.
We present CLIPPER ✂️, a compression-based pipeline that produces grounded instructions for ~$0.5 each, 34x cheaper than human annotations.
February 21, 2025 at 4:25 PM
⚠️Current methods for generating instruction-following data fall short for long-range reasoning tasks like narrative claim verification.
We present CLIPPER ✂️, a compression-based pipeline that produces grounded instructions for ~$0.5 each, 34x cheaper than human annotations.
We present CLIPPER ✂️, a compression-based pipeline that produces grounded instructions for ~$0.5 each, 34x cheaper than human annotations.
Presented this at #EMNLP2024 last week 🙌 It was great chatting with everyone about evaluation practices/possible follow-ups to the paper!
November 18, 2024 at 1:40 PM
Presented this at #EMNLP2024 last week 🙌 It was great chatting with everyone about evaluation practices/possible follow-ups to the paper!
I will be at EMNLP 🌴 to present this paper (Thursday and WNU on Friday)! Reach out if you would like to chat about
1️⃣ Long-form text generation/eval
2️⃣ Synthetic data and instruction tuning
3️⃣ Anything else!
Looking forward to meeting old and new friends!
1️⃣ Long-form text generation/eval
2️⃣ Synthetic data and instruction tuning
3️⃣ Anything else!
Looking forward to meeting old and new friends!

November 11, 2024 at 12:49 PM
I will be at EMNLP 🌴 to present this paper (Thursday and WNU on Friday)! Reach out if you would like to chat about
1️⃣ Long-form text generation/eval
2️⃣ Synthetic data and instruction tuning
3️⃣ Anything else!
Looking forward to meeting old and new friends!
1️⃣ Long-form text generation/eval
2️⃣ Synthetic data and instruction tuning
3️⃣ Anything else!
Looking forward to meeting old and new friends!
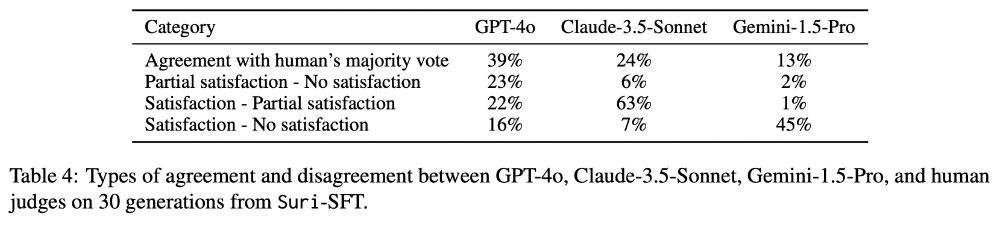
We also find that GPT-4o's annotations do not align with human evaluations when determining whether the long-form generation satisfies, partially satisfies, or does not satisfy the given constraints.
November 11, 2024 at 12:44 PM
We also find that GPT-4o's annotations do not align with human evaluations when determining whether the long-form generation satisfies, partially satisfies, or does not satisfy the given constraints.
Our human evaluation shows that, while our fine-tuned models are both generally effective at following constraints, Suri-I-ORPO is preferred over Suri-SFT for coherent and informative constraint satisfaction.


November 11, 2024 at 12:44 PM
Our human evaluation shows that, while our fine-tuned models are both generally effective at following constraints, Suri-I-ORPO is preferred over Suri-SFT for coherent and informative constraint satisfaction.
Our automatic evaluation shows that Suri-I-ORPO and Suri-SFT generate substantially longer text while keeping n-gram repetitions within a reasonable range. In addition, Suri-I-ORPO improves the ranking accuracy compared to SFT and open-weight models.


November 11, 2024 at 12:44 PM
Our automatic evaluation shows that Suri-I-ORPO and Suri-SFT generate substantially longer text while keeping n-gram repetitions within a reasonable range. In addition, Suri-I-ORPO improves the ranking accuracy compared to SFT and open-weight models.
We improve @MistralAI Mistral-7B-Instruct via supervised fine-tuning and alignment.
Collecting human preferences on long-form text is costly and hard, so we propose I-ORPO, a variant of the ORPO alignment algorithm that relies on:
3️⃣ Synthetically corrupted instructions.
Collecting human preferences on long-form text is costly and hard, so we propose I-ORPO, a variant of the ORPO alignment algorithm that relies on:
3️⃣ Synthetically corrupted instructions.

November 11, 2024 at 12:42 PM
We improve @MistralAI Mistral-7B-Instruct via supervised fine-tuning and alignment.
Collecting human preferences on long-form text is costly and hard, so we propose I-ORPO, a variant of the ORPO alignment algorithm that relies on:
3️⃣ Synthetically corrupted instructions.
Collecting human preferences on long-form text is costly and hard, so we propose I-ORPO, a variant of the ORPO alignment algorithm that relies on:
3️⃣ Synthetically corrupted instructions.
We focus on the task of long-form writing generation under multiple constraints. Suri contains two initial components:
1️⃣ Gold responses from 3 existing datasets featuring web text and creative writing.
2️⃣ Backtranslated instructions generated by an LLM based on gold responses.
1️⃣ Gold responses from 3 existing datasets featuring web text and creative writing.
2️⃣ Backtranslated instructions generated by an LLM based on gold responses.

November 11, 2024 at 12:42 PM
We focus on the task of long-form writing generation under multiple constraints. Suri contains two initial components:
1️⃣ Gold responses from 3 existing datasets featuring web text and creative writing.
2️⃣ Backtranslated instructions generated by an LLM based on gold responses.
1️⃣ Gold responses from 3 existing datasets featuring web text and creative writing.
2️⃣ Backtranslated instructions generated by an LLM based on gold responses.
Long-form text generation with multiple stylistic and semantic constraints remains largely unexplored.
We present Suri 🦙: a dataset of 20K long-form texts & LLM-generated, backtranslated instructions with complex constraints.
📎 arxiv.org/abs/2406.19371
We present Suri 🦙: a dataset of 20K long-form texts & LLM-generated, backtranslated instructions with complex constraints.
📎 arxiv.org/abs/2406.19371

November 11, 2024 at 12:41 PM
Long-form text generation with multiple stylistic and semantic constraints remains largely unexplored.
We present Suri 🦙: a dataset of 20K long-form texts & LLM-generated, backtranslated instructions with complex constraints.
📎 arxiv.org/abs/2406.19371
We present Suri 🦙: a dataset of 20K long-form texts & LLM-generated, backtranslated instructions with complex constraints.
📎 arxiv.org/abs/2406.19371