



Catherine Arnett
@catherinearnett.bsky.social
NLP Researcher at EleutherAI, PhD UC San Diego Linguistics.
Previously PleIAs, Edinburgh University.
Interested in multilingual NLP, tokenizers, open science.
📍Boston. She/her.
https://catherinearnett.github.io/
Previously PleIAs, Edinburgh University.
Interested in multilingual NLP, tokenizers, open science.
📍Boston. She/her.
https://catherinearnett.github.io/
We found that one of the biggest predictors of token premium effects was whitespace usage. So we also trained SuperBPE tokenizers, which do not use whitespace pretokenizers. SuperBPE tokenizers demonstrate better compression and less extreme token premium effects.

October 28, 2025 at 3:11 PM
We found that one of the biggest predictors of token premium effects was whitespace usage. So we also trained SuperBPE tokenizers, which do not use whitespace pretokenizers. SuperBPE tokenizers demonstrate better compression and less extreme token premium effects.
While it’s possible to achieve the same compression for some sets of languages by manipulating vocabulary size, there are some languages which changing vocab size does not lead to the same compression.

October 28, 2025 at 3:11 PM
While it’s possible to achieve the same compression for some sets of languages by manipulating vocabulary size, there are some languages which changing vocab size does not lead to the same compression.
We used the compression rates we got from our monolingual tokenizers to estimate the vocabulary size at which a tokenizer would reach a target compression rate. We used this to determine the “optimal” vocab size for each language. This significantly reduces token premium effects.

October 28, 2025 at 3:11 PM
We used the compression rates we got from our monolingual tokenizers to estimate the vocabulary size at which a tokenizer would reach a target compression rate. We used this to determine the “optimal” vocab size for each language. This significantly reduces token premium effects.
We trained 7000 monolingual tokenizers for 97 languages and a range of vocabulary sizes. There was no vocabulary size at which token premiums go away, though larger vocabularies unsurprisingly lead to better compression and slightly smaller token premiums.

October 28, 2025 at 3:11 PM
We trained 7000 monolingual tokenizers for 97 languages and a range of vocabulary sizes. There was no vocabulary size at which token premiums go away, though larger vocabularies unsurprisingly lead to better compression and slightly smaller token premiums.
Our #NeurIPS2025 paper shows that even comparable monolingual tokenizers have different compression rates across languages. But by getting rid of whitespace tokenization and using a custom vocab size for each language, we can reduce token premiums. Preprint out now!

October 28, 2025 at 3:11 PM
Our #NeurIPS2025 paper shows that even comparable monolingual tokenizers have different compression rates across languages. But by getting rid of whitespace tokenization and using a custom vocab size for each language, we can reduce token premiums. Preprint out now!
I’m in Montreal this week for @colmweb.org and @wmdqs.bsky.social! Looking forward to chatting about tokenizers, multilingual data, and more! #COLM2025

October 6, 2025 at 9:30 PM
I’m in Montreal this week for @colmweb.org and @wmdqs.bsky.social! Looking forward to chatting about tokenizers, multilingual data, and more! #COLM2025
I have a new blog post about the so-called “tokenizer-free” approach to language modeling and why it’s not tokenizer-free at all. I also talk about why people hate tokenizers so much!

September 25, 2025 at 3:14 PM
I have a new blog post about the so-called “tokenizer-free” approach to language modeling and why it’s not tokenizer-free at all. I also talk about why people hate tokenizers so much!
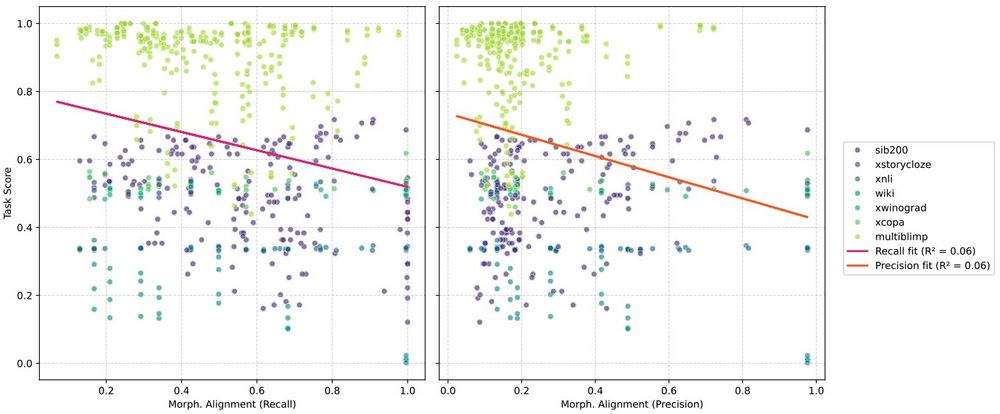
We replicate the findings from the COLING paper and find that higher morphological alignment scores do not correlate with better performance. In fact, they’re predictive of slightly *worse* performance across multiple tasks and models.
July 10, 2025 at 4:09 PM
We replicate the findings from the COLING paper and find that higher morphological alignment scores do not correlate with better performance. In fact, they’re predictive of slightly *worse* performance across multiple tasks and models.
MorphScore got an update! MorphScore now covers 70 languages 🌎🌍🌏 We have a new-preprint out and we will be presenting our paper at the Tokenization Workshop @tokshop.bsky.social at ICML next week! @marisahudspeth.bsky.social @brenocon.bsky.social

July 10, 2025 at 4:09 PM
MorphScore got an update! MorphScore now covers 70 languages 🌎🌍🌏 We have a new-preprint out and we will be presenting our paper at the Tokenization Workshop @tokshop.bsky.social at ICML next week! @marisahudspeth.bsky.social @brenocon.bsky.social
As part of the workshop, we are also organizing a shared task to develop a collaborative physical commonsense reasoning evaluation dataset. See the shared task page for more information: sigtyp.github.io/st2025-mrl.h....

June 24, 2025 at 4:33 PM
As part of the workshop, we are also organizing a shared task to develop a collaborative physical commonsense reasoning evaluation dataset. See the shared task page for more information: sigtyp.github.io/st2025-mrl.h....
The call for papers is out for the 5th edition of the Workshop on Multilingual Representation Learning which will take place in Suzhou, China co-located with EMNLP 2025! See details below!

June 24, 2025 at 4:33 PM
The call for papers is out for the 5th edition of the Workshop on Multilingual Representation Learning which will take place in Suzhou, China co-located with EMNLP 2025! See details below!
Data contributions can be made through the Web Languages Project and/or Text Language Identification task on Dynabench. Top contributors will be recognized as part of the shared task!
Web Langs Project: github.com/commoncrawl/...
Text ID: dynabench.org/tasks/text-l...
Web Langs Project: github.com/commoncrawl/...
Text ID: dynabench.org/tasks/text-l...

June 9, 2025 at 3:44 PM
Data contributions can be made through the Web Languages Project and/or Text Language Identification task on Dynabench. Top contributors will be recognized as part of the shared task!
Web Langs Project: github.com/commoncrawl/...
Text ID: dynabench.org/tasks/text-l...
Web Langs Project: github.com/commoncrawl/...
Text ID: dynabench.org/tasks/text-l...

We also discuss how this encoding strategy helps provide an alternative to complex and fragile regex pretokenization (visualization from arxiv.org/abs/2402.01035)

June 3, 2025 at 3:43 PM
We also discuss how this encoding strategy helps provide an alternative to complex and fragile regex pretokenization (visualization from arxiv.org/abs/2402.01035)
What if we didn't use UTF-8 as a starting point for tokenization? In UTF-8, different scripts need different number of bytes. And tokenizers can create merges that lead to stranded bytes and undecodable sequences. Sander Land and I propose a novel encoding strategy that solves those problems!

June 3, 2025 at 3:43 PM
What if we didn't use UTF-8 as a starting point for tokenization? In UTF-8, different scripts need different number of bytes. And tokenizers can create merges that lead to stranded bytes and undecodable sequences. Sander Land and I propose a novel encoding strategy that solves those problems!
I’m in Paris this week to present about best practices for multilingual LLM evaluation in the open! I’m talking at PyTorch Day as part of #GOSIMParis2025. I also wrote up the content of my talk as a blog post if you’re interested - link below!


May 7, 2025 at 12:04 PM
I’m in Paris this week to present about best practices for multilingual LLM evaluation in the open! I’m talking at PyTorch Day as part of #GOSIMParis2025. I also wrote up the content of my talk as a blog post if you’re interested - link below!
I’m in Paris this week to present about best practices for multilingual LLM evaluation in the open! I’m talking at PyTorch Day as part of #GOSIMParis2025. I also wrote up the content of my talk as a blog post if you’re interested - link below!
May 7, 2025 at 12:04 PM
I’m in Paris this week to present about best practices for multilingual LLM evaluation in the open! I’m talking at PyTorch Day as part of #GOSIMParis2025. I also wrote up the content of my talk as a blog post if you’re interested - link below!
✨New pre-print✨ Crosslingual transfer allows models to leverage their representations for one language to improve performance on another language. We characterize the acquisition of shared representations in order to better understand how and when crosslingual transfer happens.

March 7, 2025 at 4:34 PM
✨New pre-print✨ Crosslingual transfer allows models to leverage their representations for one language to improve performance on another language. We characterize the acquisition of shared representations in order to better understand how and when crosslingual transfer happens.
#COLING2025 isn't over yet! I'm presenting my poster now on GatherTown! Come stop by and chat!

January 27, 2025 at 2:58 PM
#COLING2025 isn't over yet! I'm presenting my poster now on GatherTown! Come stop by and chat!
Super honored that this paper received the best paper award at #COLING2025!

January 24, 2025 at 3:56 PM
Super honored that this paper received the best paper award at #COLING2025!
This week I came back to San Diego and successfully defended my dissertation, “A Linguistic Approach to Crosslingual and Multilingual NLP”!


January 23, 2025 at 3:35 PM
This week I came back to San Diego and successfully defended my dissertation, “A Linguistic Approach to Crosslingual and Multilingual NLP”!
I've been thinking about small models and why people don't like them substack.com/@catherinear... #NLP

December 6, 2024 at 5:05 PM
I've been thinking about small models and why people don't like them substack.com/@catherinear... #NLP
We are working on developing evaluations to see how the filtering impacted our models! Should hopefully be out early next year, but the preliminary results are in our recent model release blog post: huggingface.co/blog/Pclangl...

December 6, 2024 at 3:24 PM
We are working on developing evaluations to see how the filtering impacted our models! Should hopefully be out early next year, but the preliminary results are in our recent model release blog post: huggingface.co/blog/Pclangl...
And we developed a new toxicity benchmark, which shows that our models are much less likely to generate a harmful continuation, even when the prompts are toxic. More details on that to come soon!
December 5, 2024 at 3:44 PM
And we developed a new toxicity benchmark, which shows that our models are much less likely to generate a harmful continuation, even when the prompts are toxic. More details on that to come soon!
We spent a lot of time trying to mitigate harmful behaviors. We developed a multilingual data filtering pipeline, particularly focused on our historical data. Read more about it in our recent preprint: arxiv.org/pdf/2410.22587

December 5, 2024 at 3:44 PM
We spent a lot of time trying to mitigate harmful behaviors. We developed a multilingual data filtering pipeline, particularly focused on our historical data. Read more about it in our recent preprint: arxiv.org/pdf/2410.22587