



Carlo Sferrazza
@carlosferrazza.bsky.social
Postdoc at Berkeley AI Research. PhD from ETH Zurich.
Robotics, Artificial Intelligence, Humanoids, Tactile Sensing.
https://sferrazza.cc
Robotics, Artificial Intelligence, Humanoids, Tactile Sensing.
https://sferrazza.cc
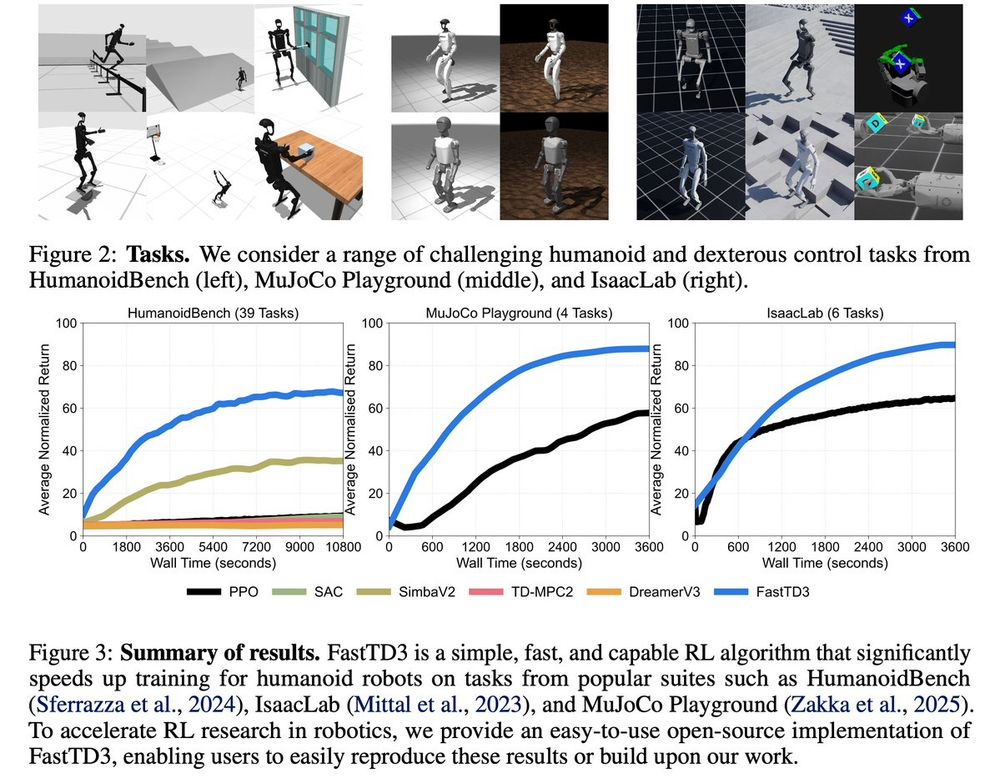
FastTD3 is open-source, and compatible with most sim-to-real robotics frameworks, e.g., MuJoCo Playground and Isaac Lab. All the advances in scaling off-policy RL are now readily available to the robotics community 🤖
May 29, 2025 at 5:49 PM
FastTD3 is open-source, and compatible with most sim-to-real robotics frameworks, e.g., MuJoCo Playground and Isaac Lab. All the advances in scaling off-policy RL are now readily available to the robotics community 🤖
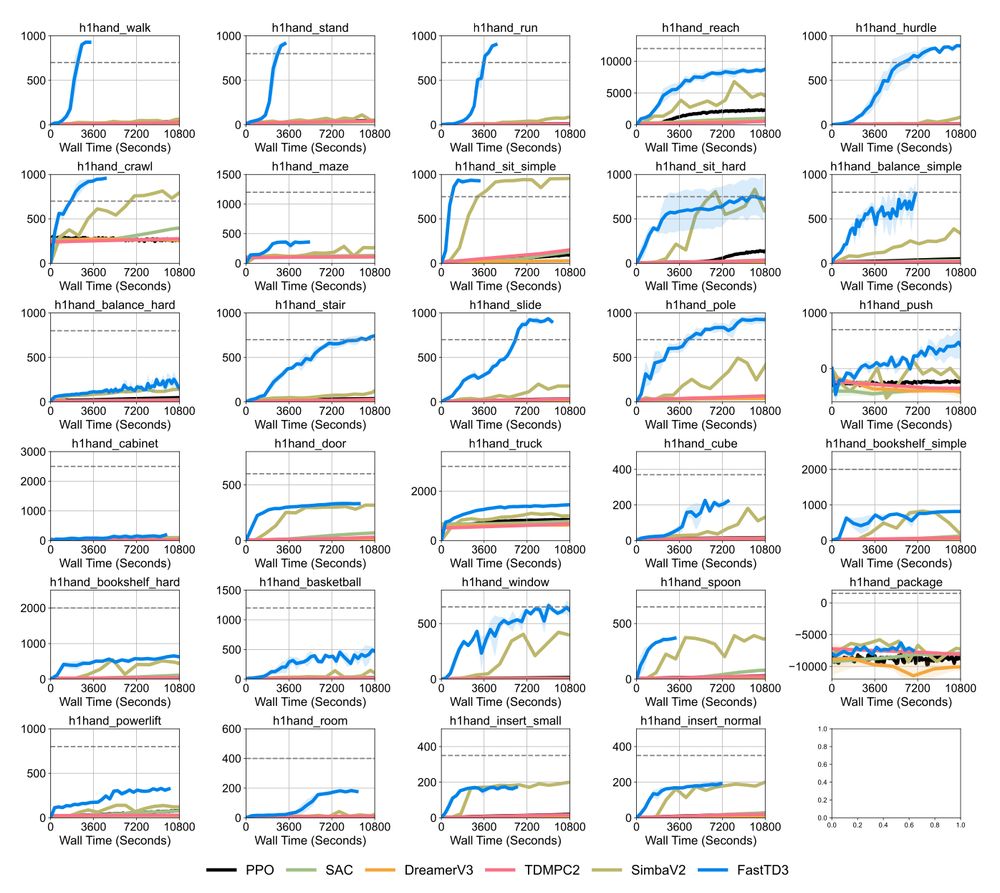
A very cool thing: FastTD3 achieves state-of-the-art performance on most HumanoidBench tasks, even superior to model-based algorithms. All it takes: 128 parallel environments and 1-3 hours of training 🤯
May 29, 2025 at 5:49 PM
A very cool thing: FastTD3 achieves state-of-the-art performance on most HumanoidBench tasks, even superior to model-based algorithms. All it takes: 128 parallel environments and 1-3 hours of training 🤯
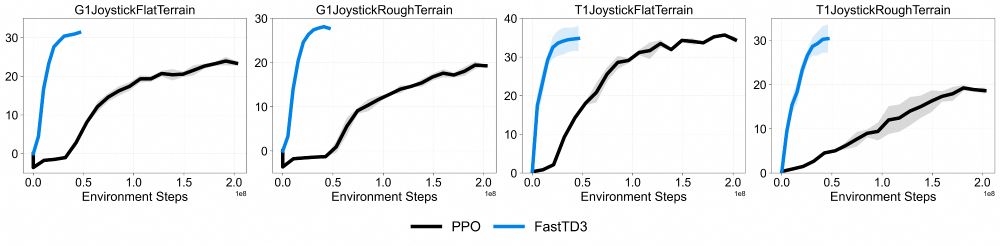
Off-policy methods have pushed RL sample efficiency, but robotics still leans on parallel on-policy RL (PPO) for wall-time gains. FastTD3 gets the best of both worlds!
May 29, 2025 at 5:49 PM
Off-policy methods have pushed RL sample efficiency, but robotics still leans on parallel on-policy RL (PPO) for wall-time gains. FastTD3 gets the best of both worlds!
We just released FastTD3: a simple, fast, off-policy RL algorithm to train humanoid policies that transfer seamlessly from simulation to the real world.
younggyo.me/fast_td3
younggyo.me/fast_td3
May 29, 2025 at 5:49 PM
We just released FastTD3: a simple, fast, off-policy RL algorithm to train humanoid policies that transfer seamlessly from simulation to the real world.
younggyo.me/fast_td3
younggyo.me/fast_td3
Heading to @ieeeras.bsky.social RoboSoft today! I'll be giving a short Rising Star talk Thu at 2:30pm: "Towards Multi-sensory, Tactile-Enabled Generalist Robot Learning"
Excited for my first in-person RoboSoft after the 2020 edition went virtual mid-pandemic.
Reach out if you'd like to chat!
Excited for my first in-person RoboSoft after the 2020 edition went virtual mid-pandemic.
Reach out if you'd like to chat!

April 22, 2025 at 5:59 PM
Heading to @ieeeras.bsky.social RoboSoft today! I'll be giving a short Rising Star talk Thu at 2:30pm: "Towards Multi-sensory, Tactile-Enabled Generalist Robot Learning"
Excited for my first in-person RoboSoft after the 2020 edition went virtual mid-pandemic.
Reach out if you'd like to chat!
Excited for my first in-person RoboSoft after the 2020 edition went virtual mid-pandemic.
Reach out if you'd like to chat!
What is the place of exploration in today's AI landscape and in which settings can exploration algorithms address current open challenges?
Join us to discuss this at our exciting workshop at @icmlconf.bsky.social 2025: EXAIT!
exait-workshop.github.io
#ICML2025
Join us to discuss this at our exciting workshop at @icmlconf.bsky.social 2025: EXAIT!
exait-workshop.github.io
#ICML2025

April 17, 2025 at 5:53 AM
What is the place of exploration in today's AI landscape and in which settings can exploration algorithms address current open challenges?
Join us to discuss this at our exciting workshop at @icmlconf.bsky.social 2025: EXAIT!
exait-workshop.github.io
#ICML2025
Join us to discuss this at our exciting workshop at @icmlconf.bsky.social 2025: EXAIT!
exait-workshop.github.io
#ICML2025
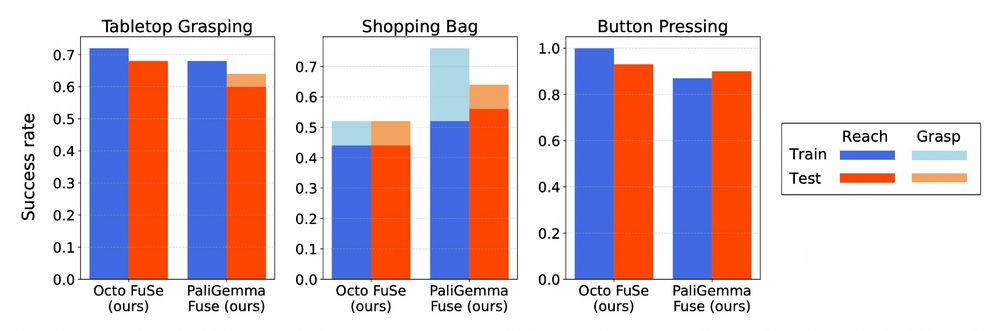
We find that the same general recipe is applicable to generalist policies with diverse architectures, including a large 3B VLA with a PaliGemma vision-language-model backbone.
January 13, 2025 at 6:51 PM
We find that the same general recipe is applicable to generalist policies with diverse architectures, including a large 3B VLA with a PaliGemma vision-language-model backbone.
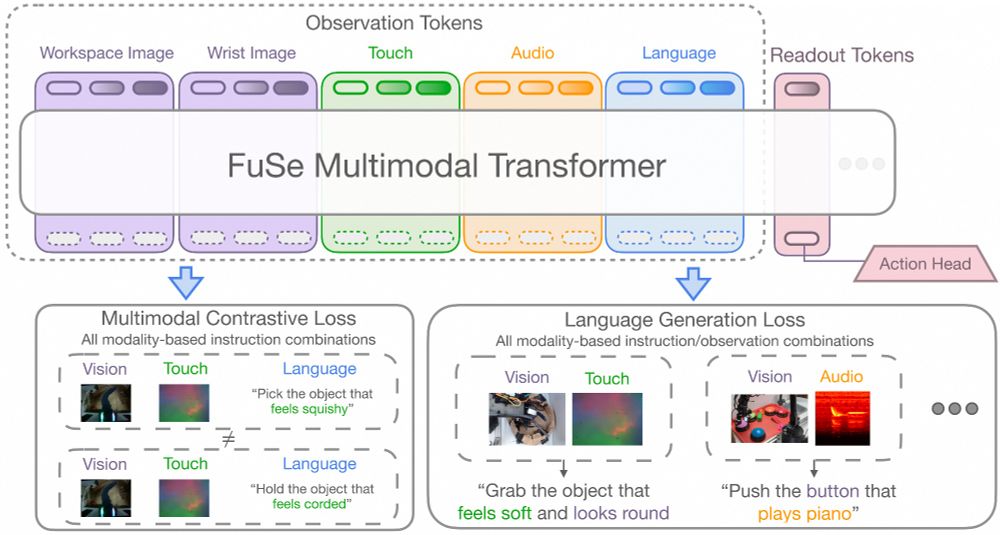
FuSe policies reason jointly over vision, touch, and sound, enabling tasks such as multimodal disambiguation, generation of object descriptions upon interaction, and compositional cross-modal prompting (e.g., “press the button with the same color as the soft object”).
January 13, 2025 at 6:51 PM
FuSe policies reason jointly over vision, touch, and sound, enabling tasks such as multimodal disambiguation, generation of object descriptions upon interaction, and compositional cross-modal prompting (e.g., “press the button with the same color as the soft object”).
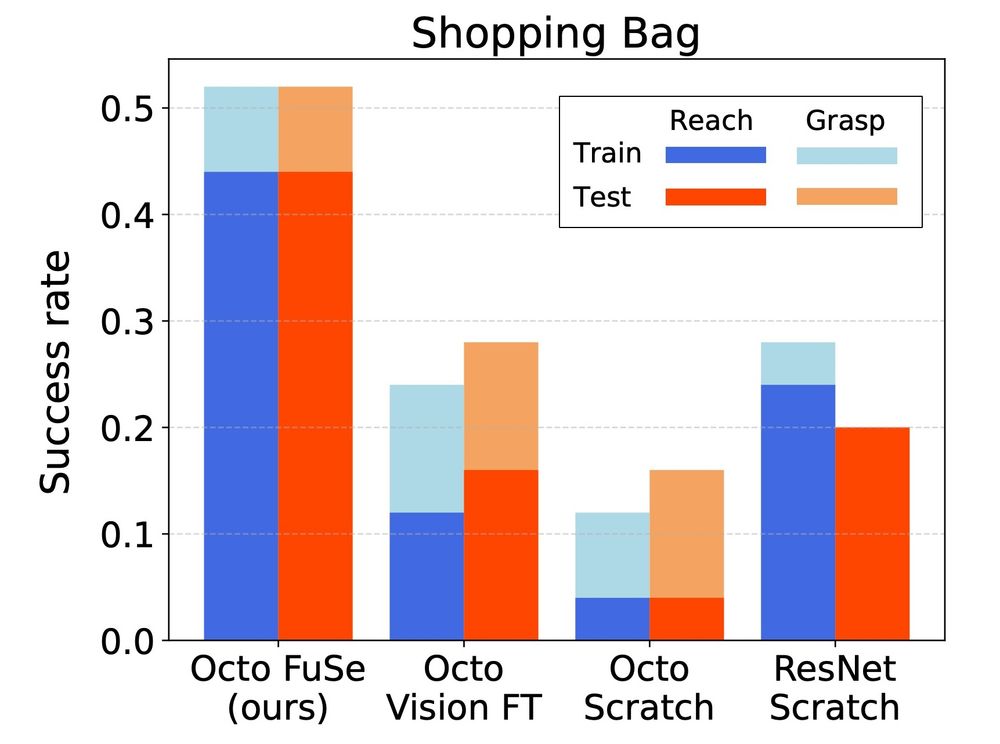
Pretrained generalist robot policies finetuned on multimodal data consistently outperform baselines finetuned only on vision data. This is particularly evident in tasks with partial visual observability, such as grabbing objects from a shopping bag.
January 13, 2025 at 6:51 PM
Pretrained generalist robot policies finetuned on multimodal data consistently outperform baselines finetuned only on vision data. This is particularly evident in tasks with partial visual observability, such as grabbing objects from a shopping bag.
We use language instructions to ground all sensing modalities by introducing two auxiliary losses. In fact, we find that naively finetuning on a small-scale multimodal dataset results in the VLA over-relying on vision, ignoring much sparser tactile and auditory signals.
January 13, 2025 at 6:51 PM
We use language instructions to ground all sensing modalities by introducing two auxiliary losses. In fact, we find that naively finetuning on a small-scale multimodal dataset results in the VLA over-relying on vision, ignoring much sparser tactile and auditory signals.
Ever wondered what robots 🤖 could achieve if they could not just see – but also feel and hear?
Introducing FuSe: a recipe for finetuning large vision-language-action (VLA) models with heterogeneous sensory data, such as vision, touch, sound, and more.
Details in the thread 👇
Introducing FuSe: a recipe for finetuning large vision-language-action (VLA) models with heterogeneous sensory data, such as vision, touch, sound, and more.
Details in the thread 👇
January 13, 2025 at 6:51 PM
Ever wondered what robots 🤖 could achieve if they could not just see – but also feel and hear?
Introducing FuSe: a recipe for finetuning large vision-language-action (VLA) models with heterogeneous sensory data, such as vision, touch, sound, and more.
Details in the thread 👇
Introducing FuSe: a recipe for finetuning large vision-language-action (VLA) models with heterogeneous sensory data, such as vision, touch, sound, and more.
Details in the thread 👇
By combining MaxInfoRL with DrQv2 and DrM, this achieves state-of-the-art model-free performance on hard visual control tasks such as DMControl humanoid and dog tasks, improving both sample efficiency and steady-state performance.
December 17, 2024 at 5:47 PM
By combining MaxInfoRL with DrQv2 and DrM, this achieves state-of-the-art model-free performance on hard visual control tasks such as DMControl humanoid and dog tasks, improving both sample efficiency and steady-state performance.
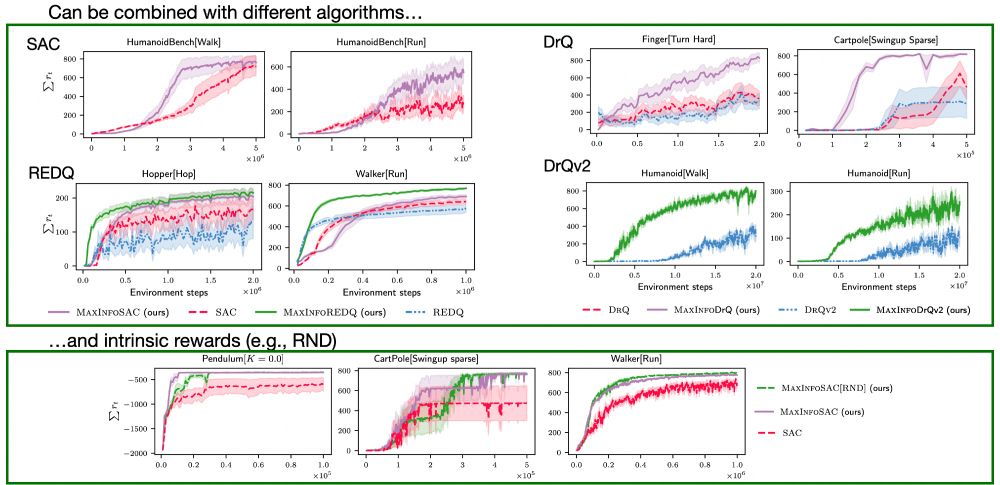
MaxInfoRL is a simple, flexible, and scalable add-on to most RL advancements. We combine it with various algorithms, such as SAC, REDQ, DrQv2, DrM, and more – consistently showing improved performance over the respective backbones.
December 17, 2024 at 5:47 PM
MaxInfoRL is a simple, flexible, and scalable add-on to most RL advancements. We combine it with various algorithms, such as SAC, REDQ, DrQv2, DrM, and more – consistently showing improved performance over the respective backbones.
While standard Boltzmann exploration (e.g., SAC) focuses only on action entropy, MaxInfoRL maximizes entropy in both state and action spaces! This proves to be crucial when dealing with complex exploration settings.
December 17, 2024 at 5:47 PM
While standard Boltzmann exploration (e.g., SAC) focuses only on action entropy, MaxInfoRL maximizes entropy in both state and action spaces! This proves to be crucial when dealing with complex exploration settings.
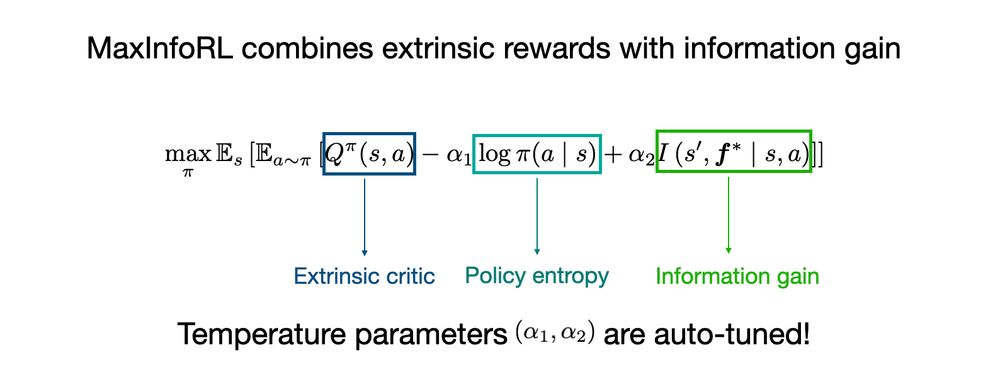
The core principle is to balance extrinsic rewards with intrinsic exploration. MaxInfoRL achieves this by 1) using an ensemble of dynamics models to estimate information gain, and 2) incorporating this as an automatically-tuned exploration bonus in addition to policy entropy.
December 17, 2024 at 5:47 PM
The core principle is to balance extrinsic rewards with intrinsic exploration. MaxInfoRL achieves this by 1) using an ensemble of dynamics models to estimate information gain, and 2) incorporating this as an automatically-tuned exploration bonus in addition to policy entropy.
🚨 New reinforcement learning algorithms 🚨
Excited to announce MaxInfoRL, a class of model-free RL algorithms that solves complex continuous control tasks (including vision-based!) by steering exploration towards informative transitions.
Details in the thread 👇
Excited to announce MaxInfoRL, a class of model-free RL algorithms that solves complex continuous control tasks (including vision-based!) by steering exploration towards informative transitions.
Details in the thread 👇
December 17, 2024 at 5:47 PM
🚨 New reinforcement learning algorithms 🚨
Excited to announce MaxInfoRL, a class of model-free RL algorithms that solves complex continuous control tasks (including vision-based!) by steering exploration towards informative transitions.
Details in the thread 👇
Excited to announce MaxInfoRL, a class of model-free RL algorithms that solves complex continuous control tasks (including vision-based!) by steering exploration towards informative transitions.
Details in the thread 👇
MaxInfoRL is a simple, flexible, and scalable add-on to most RL advancements. We combine it with various algorithms, such as SAC, REDQ, DrQv2, DrM, and more – consistently showing improved performance over the respective backbones.
December 17, 2024 at 5:44 PM
MaxInfoRL is a simple, flexible, and scalable add-on to most RL advancements. We combine it with various algorithms, such as SAC, REDQ, DrQv2, DrM, and more – consistently showing improved performance over the respective backbones.
While standard Boltzmann exploration (e.g., SAC) focuses only on action entropy, MaxInfoRL maximizes entropy in both state and action spaces! This proves to be crucial when dealing with complex exploration settings.
December 17, 2024 at 5:44 PM
While standard Boltzmann exploration (e.g., SAC) focuses only on action entropy, MaxInfoRL maximizes entropy in both state and action spaces! This proves to be crucial when dealing with complex exploration settings.
The core principle is to balance extrinsic rewards with intrinsic exploration. MaxInfoRL achieves this by 1) using an ensemble of dynamics models to estimate information gain, and 2) incorporating this as an automatically-tuned exploration bonus in addition to policy entropy.
December 17, 2024 at 5:44 PM
The core principle is to balance extrinsic rewards with intrinsic exploration. MaxInfoRL achieves this by 1) using an ensemble of dynamics models to estimate information gain, and 2) incorporating this as an automatically-tuned exploration bonus in addition to policy entropy.