



Benjamin Minixhofer
@bminixhofer.bsky.social
Models from our paper, including Gemma-2B and Llama-3B instruction-tunes transferred to byte-level, are up on Hugging Face 🤗
huggingface.co/collections/...
huggingface.co/collections/...

ALM Transfers - a benjamin Collection
We’re on a journey to advance and democratize artificial intelligence through open source and open science.
huggingface.co
April 2, 2025 at 6:42 AM
Models from our paper, including Gemma-2B and Llama-3B instruction-tunes transferred to byte-level, are up on Hugging Face 🤗
huggingface.co/collections/...
huggingface.co/collections/...
Check out the paper for lots of details.
We are also releasing our code as part of `tokenkit`, a new library implementing advanced tokenization transfer methods. More to follow on that👀
Paper: arxiv.org/abs/2503.20083
Code: github.com/bminixhofer/...
w/ Ivan Vulić and @edoardo-ponti.bsky.social
We are also releasing our code as part of `tokenkit`, a new library implementing advanced tokenization transfer methods. More to follow on that👀
Paper: arxiv.org/abs/2503.20083
Code: github.com/bminixhofer/...
w/ Ivan Vulić and @edoardo-ponti.bsky.social

Cross-Tokenizer Distillation via Approximate Likelihood Matching
Distillation has shown remarkable success in transferring knowledge from a Large Language Model (LLM) teacher to a student LLM. However, current distillation methods predominantly require the same tok...
arxiv.org
April 2, 2025 at 6:41 AM
Check out the paper for lots of details.
We are also releasing our code as part of `tokenkit`, a new library implementing advanced tokenization transfer methods. More to follow on that👀
Paper: arxiv.org/abs/2503.20083
Code: github.com/bminixhofer/...
w/ Ivan Vulić and @edoardo-ponti.bsky.social
We are also releasing our code as part of `tokenkit`, a new library implementing advanced tokenization transfer methods. More to follow on that👀
Paper: arxiv.org/abs/2503.20083
Code: github.com/bminixhofer/...
w/ Ivan Vulić and @edoardo-ponti.bsky.social
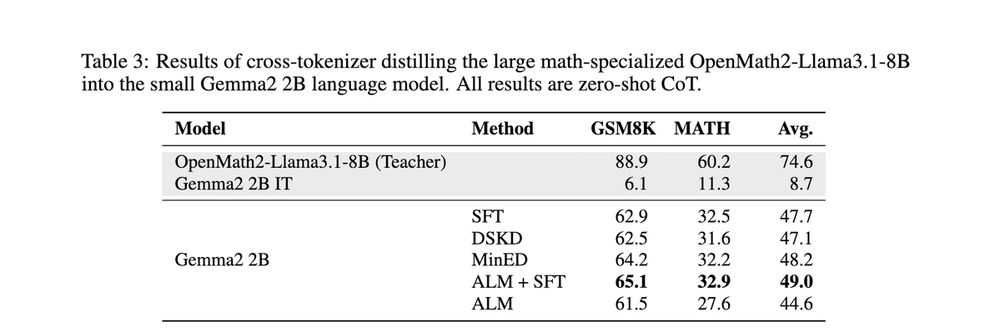
2️⃣We also use ALM to directly transfer knowledge from a large teacher (with one tokenizer) to a smaller student (with another tokenizer).
We test this by distilling a large maths-specialized Llama into a small Gemma model.🔢
We test this by distilling a large maths-specialized Llama into a small Gemma model.🔢
April 2, 2025 at 6:39 AM
2️⃣We also use ALM to directly transfer knowledge from a large teacher (with one tokenizer) to a smaller student (with another tokenizer).
We test this by distilling a large maths-specialized Llama into a small Gemma model.🔢
We test this by distilling a large maths-specialized Llama into a small Gemma model.🔢
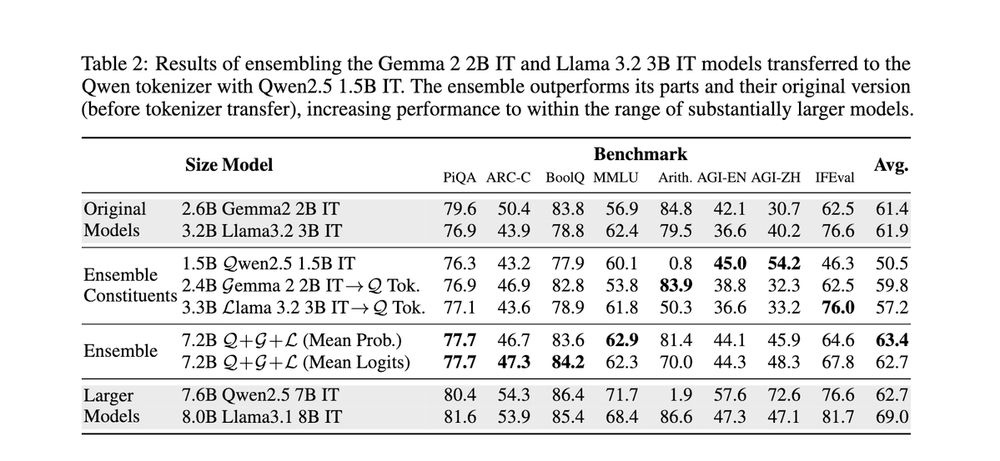
1️⃣continued: we can also transfer different base models to the same tokenizer, then ensemble them by combining their logits.
This would not be possible if they had different tokenizers.
We try ensembling Gemma, Llama and Qwen. They perform better together than separately!🤝
This would not be possible if they had different tokenizers.
We try ensembling Gemma, Llama and Qwen. They perform better together than separately!🤝
April 2, 2025 at 6:39 AM
1️⃣continued: we can also transfer different base models to the same tokenizer, then ensemble them by combining their logits.
This would not be possible if they had different tokenizers.
We try ensembling Gemma, Llama and Qwen. They perform better together than separately!🤝
This would not be possible if they had different tokenizers.
We try ensembling Gemma, Llama and Qwen. They perform better together than separately!🤝
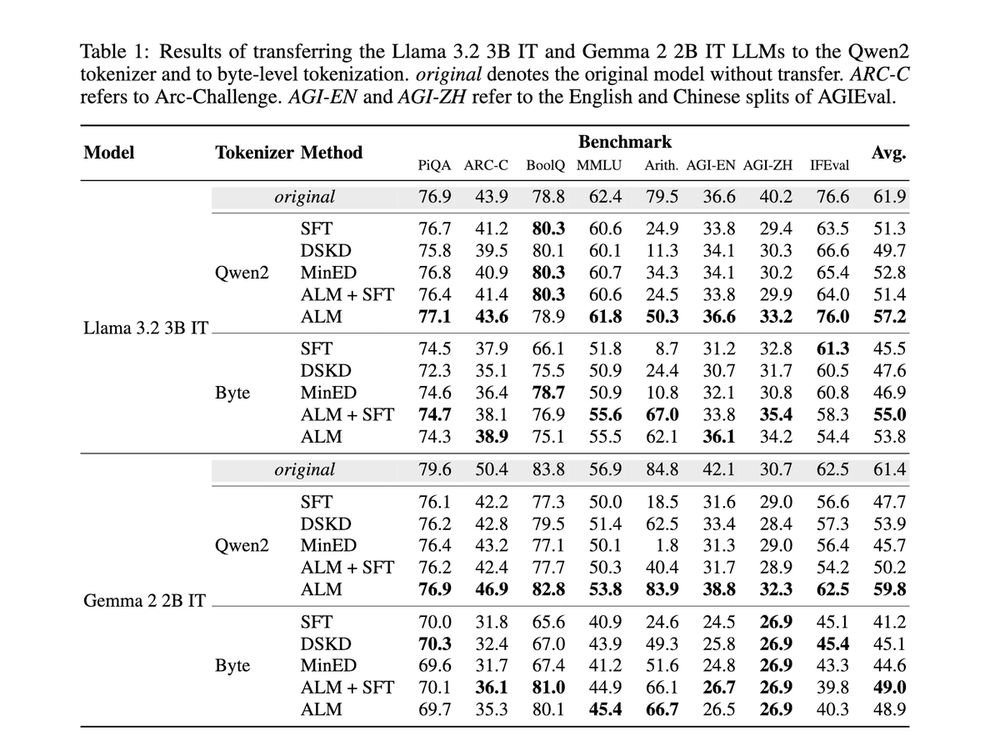
We investigate two use cases of ALM in detail (but there's definitely more!)
1️⃣Tokenizer transfer: the teacher is the model with its original tokenizer; the student is the same model with a new tokenizer.
Here, ALM even lets us distill subword models to a byte-level tokenizer😮
1️⃣Tokenizer transfer: the teacher is the model with its original tokenizer; the student is the same model with a new tokenizer.
Here, ALM even lets us distill subword models to a byte-level tokenizer😮
April 2, 2025 at 6:38 AM
We investigate two use cases of ALM in detail (but there's definitely more!)
1️⃣Tokenizer transfer: the teacher is the model with its original tokenizer; the student is the same model with a new tokenizer.
Here, ALM even lets us distill subword models to a byte-level tokenizer😮
1️⃣Tokenizer transfer: the teacher is the model with its original tokenizer; the student is the same model with a new tokenizer.
Here, ALM even lets us distill subword models to a byte-level tokenizer😮
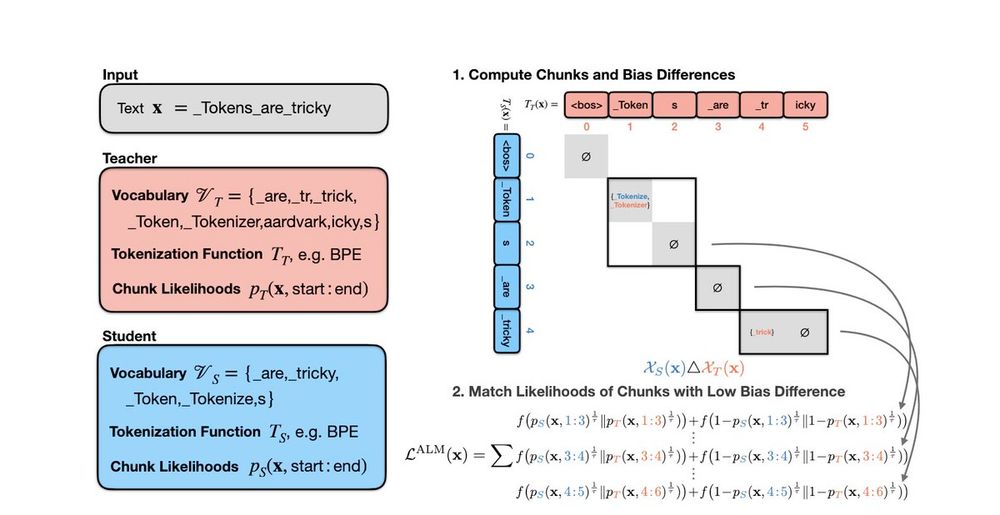
Chunks of tokens with different tokenization biases are not fairly comparable!⚠️⚠️
We thus develop a method to find chunks with low tokenization bias differences (making them *approximately comparable*), then learn to match the likelihoods of those✅
We thus develop a method to find chunks with low tokenization bias differences (making them *approximately comparable*), then learn to match the likelihoods of those✅
April 2, 2025 at 6:38 AM
Chunks of tokens with different tokenization biases are not fairly comparable!⚠️⚠️
We thus develop a method to find chunks with low tokenization bias differences (making them *approximately comparable*), then learn to match the likelihoods of those✅
We thus develop a method to find chunks with low tokenization bias differences (making them *approximately comparable*), then learn to match the likelihoods of those✅
Our greatest adversary in this endeavour is *tokenization bias*.
Due to tokenization bias, a sequence of subword tokens can leak information about the future contents of the text they encode.
Due to tokenization bias, a sequence of subword tokens can leak information about the future contents of the text they encode.

April 2, 2025 at 6:37 AM
Our greatest adversary in this endeavour is *tokenization bias*.
Due to tokenization bias, a sequence of subword tokens can leak information about the future contents of the text they encode.
Due to tokenization bias, a sequence of subword tokens can leak information about the future contents of the text they encode.
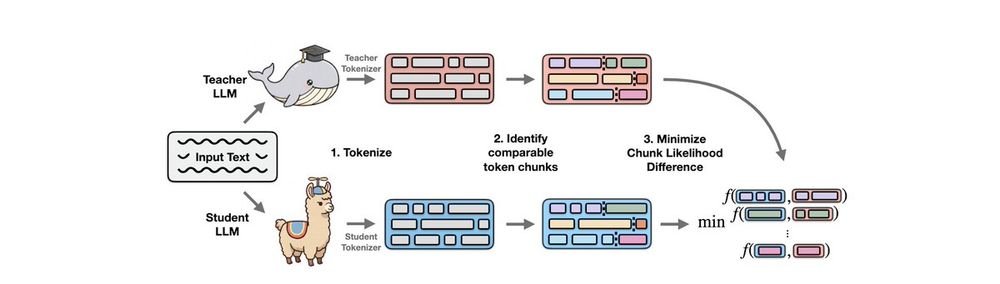
Most distillation methods so far needed the teacher and the student to have the same tokenizer.
We lift this restriction by first identifying comparable chunks of tokens in a sequence (surprisingly, this is not so easy!), then minimizing the difference between their likelihoods.
We lift this restriction by first identifying comparable chunks of tokens in a sequence (surprisingly, this is not so easy!), then minimizing the difference between their likelihoods.
April 2, 2025 at 6:37 AM
Most distillation methods so far needed the teacher and the student to have the same tokenizer.
We lift this restriction by first identifying comparable chunks of tokens in a sequence (surprisingly, this is not so easy!), then minimizing the difference between their likelihoods.
We lift this restriction by first identifying comparable chunks of tokens in a sequence (surprisingly, this is not so easy!), then minimizing the difference between their likelihoods.