



Ben Hoover
@bhoov.bsky.social
PhD student@GA Tech; Research Engineer @IBM Research. Thinking about Associative Memory, Hopfield Networks, and AI.
When u say AM decision boundaries, do you mean the "ridge" that separates basins of attraction? Not sure I understand the pseudomath
December 4, 2024 at 8:50 PM
When u say AM decision boundaries, do you mean the "ridge" that separates basins of attraction? Not sure I understand the pseudomath
Interesting -- when you say inversion, you mean taking the strict inverse of the random projection? Our work is not just a random projection for the purpose of dim reduction, but instead a random mapping to a feature space to approximate the original AM's energy.
December 4, 2024 at 8:47 PM
Interesting -- when you say inversion, you mean taking the strict inverse of the random projection? Our work is not just a random projection for the purpose of dim reduction, but instead a random mapping to a feature space to approximate the original AM's energy.
🎉Work done with @polochau.bsky.social @henstr.bsky.social @p-ram-p.bsky.social @krotov.bsky.social
Want to learn more?
📜Paper arxiv.org/abs/2410.24153
💾Code github.com/bhoov/distri...
👨🏫NeurIPS Page: neurips.cc/virtual/2024...
🎥SlidesLive (use Chrome) recorder-v3.slideslive.com#/share?share...
Want to learn more?
📜Paper arxiv.org/abs/2410.24153
💾Code github.com/bhoov/distri...
👨🏫NeurIPS Page: neurips.cc/virtual/2024...
🎥SlidesLive (use Chrome) recorder-v3.slideslive.com#/share?share...

Dense Associative Memory Through the Lens of Random Features
Dense Associative Memories are high storage capacity variants of the Hopfield networks that are capable of storing a large number of memory patterns in the weights of the network of a given size. Thei...
arxiv.org
December 3, 2024 at 4:33 PM
🎉Work done with @polochau.bsky.social @henstr.bsky.social @p-ram-p.bsky.social @krotov.bsky.social
Want to learn more?
📜Paper arxiv.org/abs/2410.24153
💾Code github.com/bhoov/distri...
👨🏫NeurIPS Page: neurips.cc/virtual/2024...
🎥SlidesLive (use Chrome) recorder-v3.slideslive.com#/share?share...
Want to learn more?
📜Paper arxiv.org/abs/2410.24153
💾Code github.com/bhoov/distri...
👨🏫NeurIPS Page: neurips.cc/virtual/2024...
🎥SlidesLive (use Chrome) recorder-v3.slideslive.com#/share?share...
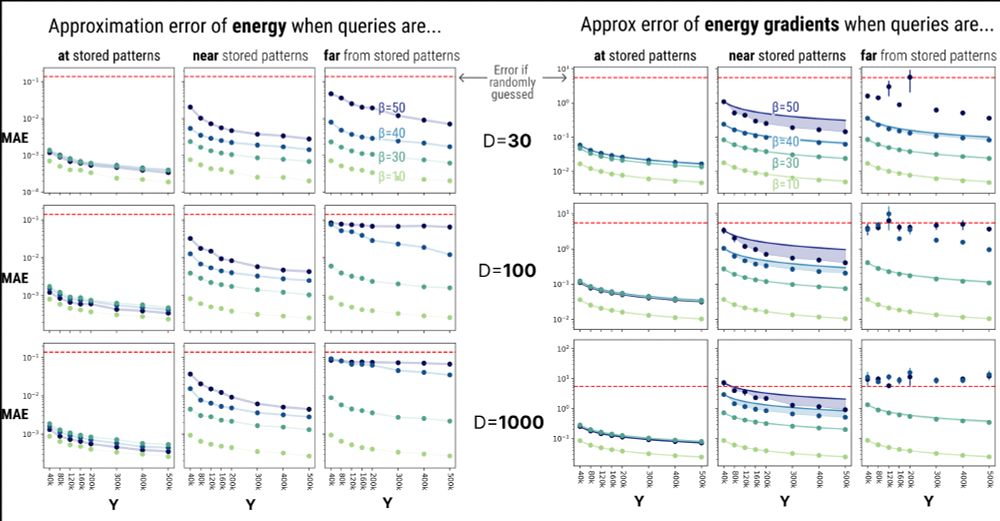
There is of course a trade off. DrDAM poorly approximates energy landscapes that are:
1️⃣Far from memories
2️⃣“Spiky” (i.e., low temperature/high beta)
We need more random features Y to reconstruct highly occluded/correlated data!
1️⃣Far from memories
2️⃣“Spiky” (i.e., low temperature/high beta)
We need more random features Y to reconstruct highly occluded/correlated data!
December 3, 2024 at 4:33 PM
There is of course a trade off. DrDAM poorly approximates energy landscapes that are:
1️⃣Far from memories
2️⃣“Spiky” (i.e., low temperature/high beta)
We need more random features Y to reconstruct highly occluded/correlated data!
1️⃣Far from memories
2️⃣“Spiky” (i.e., low temperature/high beta)
We need more random features Y to reconstruct highly occluded/correlated data!
DrDAM can meaningfully approximate the memory retrievals of MrDAM! Shown are reconstructions of occluded imgs from TinyImagenet, retrieved by strictly minimizing the energies of both DrDAM and MrDAM.

December 3, 2024 at 4:33 PM
DrDAM can meaningfully approximate the memory retrievals of MrDAM! Shown are reconstructions of occluded imgs from TinyImagenet, retrieved by strictly minimizing the energies of both DrDAM and MrDAM.
MrDAM energies can be decomposed into:
1️⃣A similarity func between stored patterns & noisy input
2️⃣A rapidly growing separation func (e.g., exponential)
Together, they reveal kernels (e.g., RBF) that can be approximated via the kernel trick & random features (Rahimi&Recht, 2007)
1️⃣A similarity func between stored patterns & noisy input
2️⃣A rapidly growing separation func (e.g., exponential)
Together, they reveal kernels (e.g., RBF) that can be approximated via the kernel trick & random features (Rahimi&Recht, 2007)
December 3, 2024 at 4:33 PM
MrDAM energies can be decomposed into:
1️⃣A similarity func between stored patterns & noisy input
2️⃣A rapidly growing separation func (e.g., exponential)
Together, they reveal kernels (e.g., RBF) that can be approximated via the kernel trick & random features (Rahimi&Recht, 2007)
1️⃣A similarity func between stored patterns & noisy input
2️⃣A rapidly growing separation func (e.g., exponential)
Together, they reveal kernels (e.g., RBF) that can be approximated via the kernel trick & random features (Rahimi&Recht, 2007)
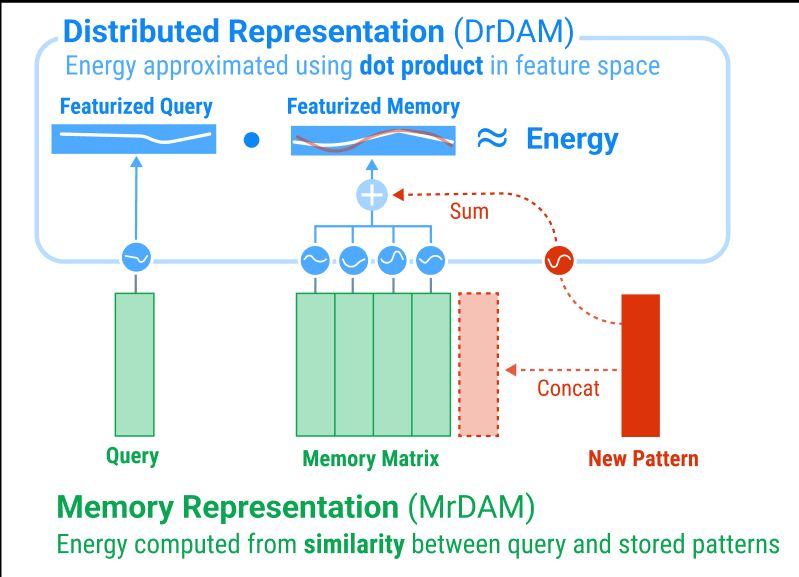
Why say “Distributed”?🤔
In traditional Memory representations of DenseAMs (MrDAM) one row in the weight matrix stores one pattern. In our new Distributed representation (DrDAM) patterns are entangled via superposition, “distributed” across all dims of a featurized memory vector
In traditional Memory representations of DenseAMs (MrDAM) one row in the weight matrix stores one pattern. In our new Distributed representation (DrDAM) patterns are entangled via superposition, “distributed” across all dims of a featurized memory vector
December 3, 2024 at 4:33 PM
Why say “Distributed”?🤔
In traditional Memory representations of DenseAMs (MrDAM) one row in the weight matrix stores one pattern. In our new Distributed representation (DrDAM) patterns are entangled via superposition, “distributed” across all dims of a featurized memory vector
In traditional Memory representations of DenseAMs (MrDAM) one row in the weight matrix stores one pattern. In our new Distributed representation (DrDAM) patterns are entangled via superposition, “distributed” across all dims of a featurized memory vector