



Benoît Sagot
@bensagot.bsky.social
Directeur de recherche at Inria, former invited professor at Collège de France, co-founder of opensquare
I'm proud to share that at @inriaparisnlp.bsky.social we have released Gaperon — a suite of generative language models trained on French, English and code data, the largest of which has 24 billion parameters. Both the models and the code are being published under open licences. Short thread🧵
We are proud to announce that we trained 1.5B, 8B, and 24B generative language models from scratch on 2 to 4 tera-tokens of carefully curated, high-quality data covering French, English and code. We release our models and code under open-source licences. Thread👇

November 12, 2025 at 5:26 PM
I'm proud to share that at @inriaparisnlp.bsky.social we have released Gaperon — a suite of generative language models trained on French, English and code data, the largest of which has 24 billion parameters. Both the models and the code are being published under open licences. Short thread🧵
Reposted by Benoît Sagot

We are delighted to announce our next seminar by Hal Daumé III @haldaume3.bsky.social (@univofmaryland.bsky.social, currently on sabbatical at @sorbonne-universite.fr) entitled "Fairness and Trustworthiness in Generative Al" on Friday 20th June at 11am CEST.

June 18, 2025 at 8:09 AM
We are delighted to announce our next seminar by Hal Daumé III @haldaume3.bsky.social (@univofmaryland.bsky.social, currently on sabbatical at @sorbonne-universite.fr) entitled "Fairness and Trustworthiness in Generative Al" on Friday 20th June at 11am CEST.
Reposted by Benoît Sagot

Does your LLM truly comprehend the complexity of the code it generates? 🥰
Introducing our new non-saturated (for at least the coming week? 😉) benchmark:
✨BigO(Bench)✨ - Can LLMs Generate Code with Controlled Time and Space Complexity?
Check out the details below !👇
Introducing our new non-saturated (for at least the coming week? 😉) benchmark:
✨BigO(Bench)✨ - Can LLMs Generate Code with Controlled Time and Space Complexity?
Check out the details below !👇

March 20, 2025 at 4:48 PM
Does your LLM truly comprehend the complexity of the code it generates? 🥰
Introducing our new non-saturated (for at least the coming week? 😉) benchmark:
✨BigO(Bench)✨ - Can LLMs Generate Code with Controlled Time and Space Complexity?
Check out the details below !👇
Introducing our new non-saturated (for at least the coming week? 😉) benchmark:
✨BigO(Bench)✨ - Can LLMs Generate Code with Controlled Time and Space Complexity?
Check out the details below !👇
Reposted by Benoît Sagot

🚀 New Paper Alert! 🚀
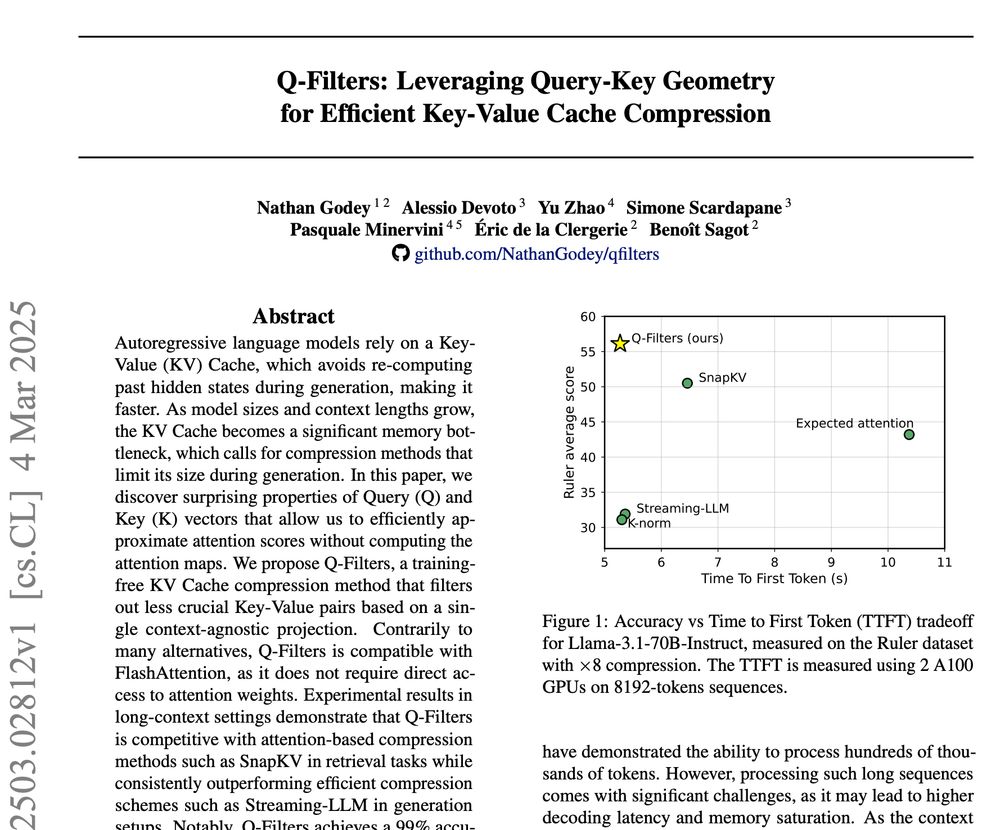
We introduce Q-Filters, a training-free method for efficient KV Cache compression!
It is compatible with FlashAttention and can compress along generation which is particularly useful for reasoning models ⚡
TLDR: we make Streaming-LLM smarter using the geometry of attention
We introduce Q-Filters, a training-free method for efficient KV Cache compression!
It is compatible with FlashAttention and can compress along generation which is particularly useful for reasoning models ⚡
TLDR: we make Streaming-LLM smarter using the geometry of attention
March 6, 2025 at 4:02 PM
🚀 New Paper Alert! 🚀
We introduce Q-Filters, a training-free method for efficient KV Cache compression!
It is compatible with FlashAttention and can compress along generation which is particularly useful for reasoning models ⚡
TLDR: we make Streaming-LLM smarter using the geometry of attention
We introduce Q-Filters, a training-free method for efficient KV Cache compression!
It is compatible with FlashAttention and can compress along generation which is particularly useful for reasoning models ⚡
TLDR: we make Streaming-LLM smarter using the geometry of attention