




Pinned
Biggest takeaway from KubeCon: People want Neki badly.
We're building the solution for scaling and managing huge Postgres databases.
More to come, but in the meantime: neki.dev
We're building the solution for scaling and managing huge Postgres databases.
More to come, but in the meantime: neki.dev

Neki - Sign Up
Join Neki and stay updated with our latest news and updates.
neki.dev
November 14, 2025 at 5:40 PM
Biggest takeaway from KubeCon: People want Neki badly.
We're building the solution for scaling and managing huge Postgres databases.
More to come, but in the meantime: neki.dev
We're building the solution for scaling and managing huge Postgres databases.
More to come, but in the meantime: neki.dev
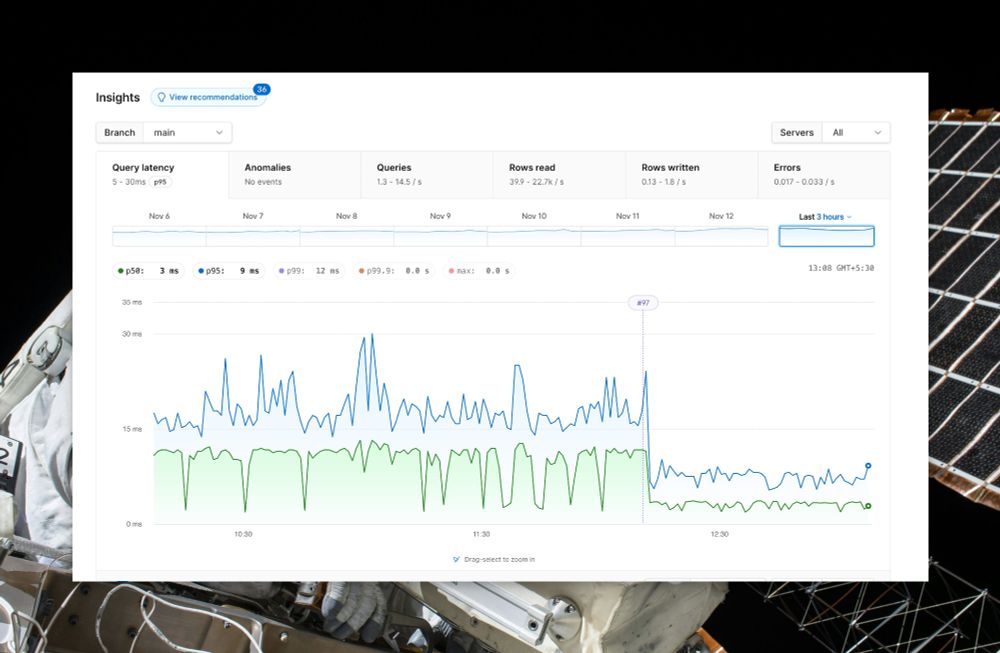
PlanetScale Insights is amazing.
Correlating schema/config changes and performance has never been easier.
The perfect tool for squeezing every ounce of performance out of your database resources.
Correlating schema/config changes and performance has never been easier.
The perfect tool for squeezing every ounce of performance out of your database resources.
November 13, 2025 at 2:49 PM
PlanetScale Insights is amazing.
Correlating schema/config changes and performance has never been easier.
The perfect tool for squeezing every ounce of performance out of your database resources.
Correlating schema/config changes and performance has never been easier.
The perfect tool for squeezing every ounce of performance out of your database resources.
Postgres handles MVCC with per-row transaction ID metadata.
Every row (tuple) you insert into a Postgres table includes xmin and xmax metadata. xmin is the transaction that created the row, and xmax the one that updates or deleted it.
Every row (tuple) you insert into a Postgres table includes xmin and xmax metadata. xmin is the transaction that created the row, and xmax the one that updates or deleted it.

November 12, 2025 at 7:37 PM
Postgres handles MVCC with per-row transaction ID metadata.
Every row (tuple) you insert into a Postgres table includes xmin and xmax metadata. xmin is the transaction that created the row, and xmax the one that updates or deleted it.
Every row (tuple) you insert into a Postgres table includes xmin and xmax metadata. xmin is the transaction that created the row, and xmax the one that updates or deleted it.
Not all CPUs are created equal.
This latency graph shows a r6id → i7i upgrade. Same vCPU count. Same amount of RAM. Both using local SSDs.
Upgrading to a newer instance makes a big difference.
This latency graph shows a r6id → i7i upgrade. Same vCPU count. Same amount of RAM. Both using local SSDs.
Upgrading to a newer instance makes a big difference.
November 10, 2025 at 12:25 PM
Not all CPUs are created equal.
This latency graph shows a r6id → i7i upgrade. Same vCPU count. Same amount of RAM. Both using local SSDs.
Upgrading to a newer instance makes a big difference.
This latency graph shows a r6id → i7i upgrade. Same vCPU count. Same amount of RAM. Both using local SSDs.
Upgrading to a newer instance makes a big difference.
The database community needs better benchmarks.
TPCC is widely used for OLTP, but was published in 1992.
Who's working on this? What do you want to see in a modern OLTP benchmark?
TPCC is widely used for OLTP, but was published in 1992.
Who's working on this? What do you want to see in a modern OLTP benchmark?
November 9, 2025 at 1:41 PM
The database community needs better benchmarks.
TPCC is widely used for OLTP, but was published in 1992.
Who's working on this? What do you want to see in a modern OLTP benchmark?
TPCC is widely used for OLTP, but was published in 1992.
Who's working on this? What do you want to see in a modern OLTP benchmark?
What happens when you INSERT a row in Postgres?
Postgres needs to ensure that data is durable while maintaining good write performance + crash recovery ability. The key is in the Write-Ahead Log (WAL).
Postgres needs to ensure that data is durable while maintaining good write performance + crash recovery ability. The key is in the Write-Ahead Log (WAL).

November 7, 2025 at 3:47 PM
What happens when you INSERT a row in Postgres?
Postgres needs to ensure that data is durable while maintaining good write performance + crash recovery ability. The key is in the Write-Ahead Log (WAL).
Postgres needs to ensure that data is durable while maintaining good write performance + crash recovery ability. The key is in the Write-Ahead Log (WAL).
PlanetScale now supports PgBouncers (connection poolers) for your replicas.
Connection pooling is broadly important for databases, but especially for Postgres because of its process-per-connection architecture.
Don't know what that means? I have the perfect article!
Connection pooling is broadly important for databases, but especially for Postgres because of its process-per-connection architecture.
Don't know what that means? I have the perfect article!
November 6, 2025 at 6:59 PM
PlanetScale now supports PgBouncers (connection poolers) for your replicas.
Connection pooling is broadly important for databases, but especially for Postgres because of its process-per-connection architecture.
Don't know what that means? I have the perfect article!
Connection pooling is broadly important for databases, but especially for Postgres because of its process-per-connection architecture.
Don't know what that means? I have the perfect article!
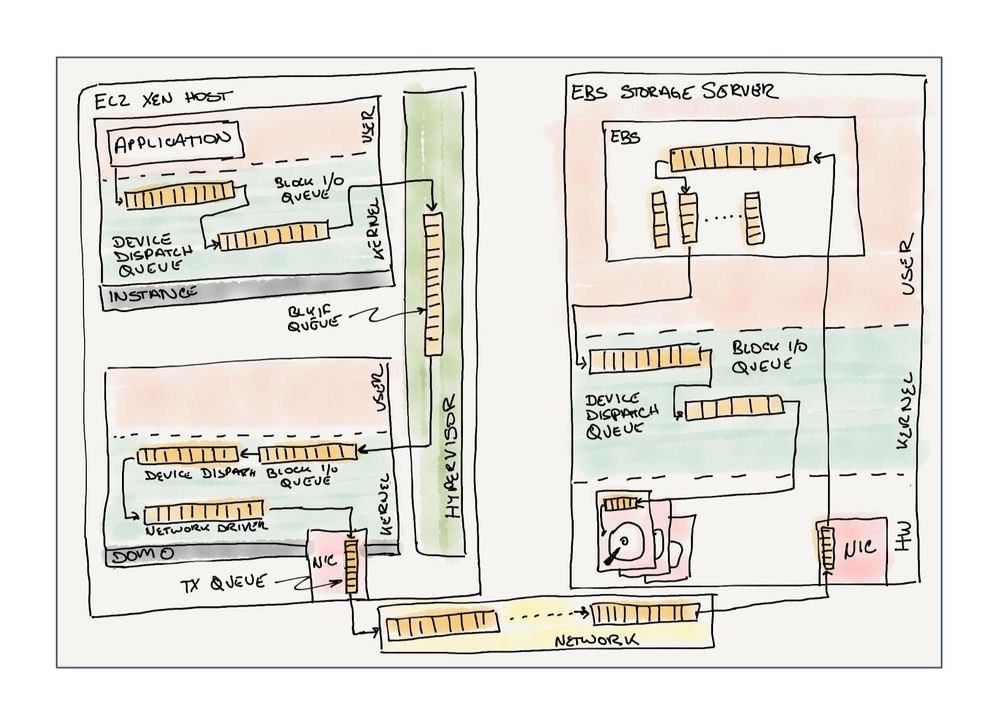
Much of the the internet runs on Elastic Block Storage.
It's the default (and in most cases, required) storage layer for every EC2 instance running in AWS.
This article by Marc Olson was a delightful read on its history and engineering challenges.
www.allthingsdistributed.com/2024/08/cont...
It's the default (and in most cases, required) storage layer for every EC2 instance running in AWS.
This article by Marc Olson was a delightful read on its history and engineering challenges.
www.allthingsdistributed.com/2024/08/cont...
November 6, 2025 at 2:55 PM
Much of the the internet runs on Elastic Block Storage.
It's the default (and in most cases, required) storage layer for every EC2 instance running in AWS.
This article by Marc Olson was a delightful read on its history and engineering challenges.
www.allthingsdistributed.com/2024/08/cont...
It's the default (and in most cases, required) storage layer for every EC2 instance running in AWS.
This article by Marc Olson was a delightful read on its history and engineering challenges.
www.allthingsdistributed.com/2024/08/cont...
Want to understand B-trees better?
Try btree.app and bplustree.app.
These are standalone sandboxes of the visuals I built for my "B-trees and database indexes" article. Helpful for learning B-tree insertion, search, and node splits.
Try btree.app and bplustree.app.
These are standalone sandboxes of the visuals I built for my "B-trees and database indexes" article. Helpful for learning B-tree insertion, search, and node splits.
November 5, 2025 at 3:53 PM
Want to understand B-trees better?
Try btree.app and bplustree.app.
These are standalone sandboxes of the visuals I built for my "B-trees and database indexes" article. Helpful for learning B-tree insertion, search, and node splits.
Try btree.app and bplustree.app.
These are standalone sandboxes of the visuals I built for my "B-trees and database indexes" article. Helpful for learning B-tree insertion, search, and node splits.
Explain is a powerful tool in Postgres.
If you care about performance, get comfortable running `explain` and `explain analyze` commands regularly, and learn how to interpret its output.
This blog is a great intro.
www.depesz.com/2013/04/16/e...
If you care about performance, get comfortable running `explain` and `explain analyze` commands regularly, and learn how to interpret its output.
This blog is a great intro.
www.depesz.com/2013/04/16/e...

November 4, 2025 at 2:59 PM
Explain is a powerful tool in Postgres.
If you care about performance, get comfortable running `explain` and `explain analyze` commands regularly, and learn how to interpret its output.
This blog is a great intro.
www.depesz.com/2013/04/16/e...
If you care about performance, get comfortable running `explain` and `explain analyze` commands regularly, and learn how to interpret its output.
This blog is a great intro.
www.depesz.com/2013/04/16/e...
Reposted by Ben

All the IOPS you can eat, now on a smaller plate.

Coming soon: $50 PlanetScale Metal and the ability to dynamically allocate CPU and memory independent of storage size.
planetscale.com/blog/50-doll...
planetscale.com/blog/50-doll...

$50 PlanetScale Metal — PlanetScale
Introducing $50 PlanetScale Metal
planetscale.com
November 3, 2025 at 7:37 PM
All the IOPS you can eat, now on a smaller plate.
I'm baffled that Postgres logical replication doesn't fully support sequences.
Keeping nextval() in sync shouldn't be that hard. What am I missing?
Keeping nextval() in sync shouldn't be that hard. What am I missing?
November 3, 2025 at 2:42 PM
I'm baffled that Postgres logical replication doesn't fully support sequences.
Keeping nextval() in sync shouldn't be that hard. What am I missing?
Keeping nextval() in sync shouldn't be that hard. What am I missing?
Choose your storage layer carefully!
Elastic Block Storage (EBS) is great for low-I/O workloads, but becomes a bottleneck or cost sink for heavy workloads.
Two common types of EBS are gp3 and io2. Both are network-attached storage backed by SSDs, but have different performance characteristics.
Elastic Block Storage (EBS) is great for low-I/O workloads, but becomes a bottleneck or cost sink for heavy workloads.
Two common types of EBS are gp3 and io2. Both are network-attached storage backed by SSDs, but have different performance characteristics.

November 2, 2025 at 1:38 PM
Choose your storage layer carefully!
Elastic Block Storage (EBS) is great for low-I/O workloads, but becomes a bottleneck or cost sink for heavy workloads.
Two common types of EBS are gp3 and io2. Both are network-attached storage backed by SSDs, but have different performance characteristics.
Elastic Block Storage (EBS) is great for low-I/O workloads, but becomes a bottleneck or cost sink for heavy workloads.
Two common types of EBS are gp3 and io2. Both are network-attached storage backed by SSDs, but have different performance characteristics.
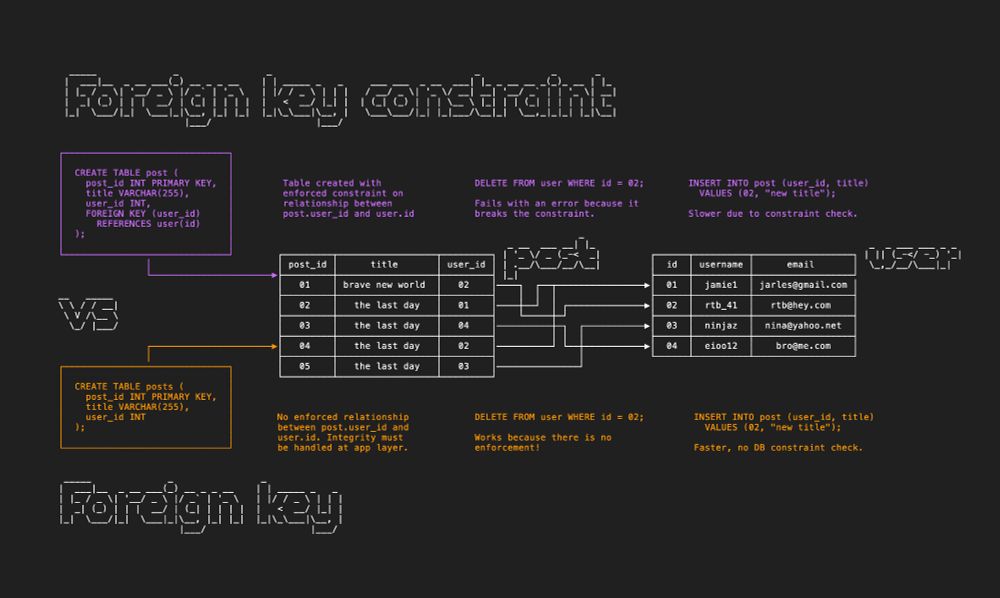
Foreign keys vs constraints. Many conflate the two.
Foreign key: A column that establishes a relationship between two tables. This is frequently set up as a column in one table (post) that stores primary key values from another table (user) so that it can join between the two.
Foreign key: A column that establishes a relationship between two tables. This is frequently set up as a column in one table (post) that stores primary key values from another table (user) so that it can join between the two.
October 29, 2025 at 3:02 PM
Foreign keys vs constraints. Many conflate the two.
Foreign key: A column that establishes a relationship between two tables. This is frequently set up as a column in one table (post) that stores primary key values from another table (user) so that it can join between the two.
Foreign key: A column that establishes a relationship between two tables. This is frequently set up as a column in one table (post) that stores primary key values from another table (user) so that it can join between the two.
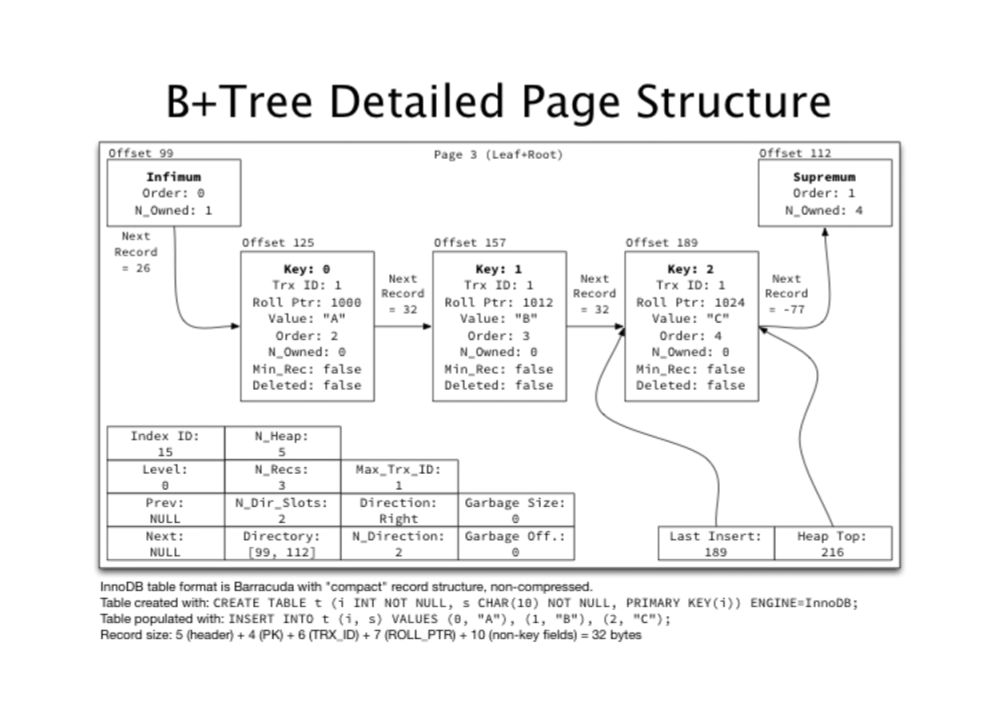
This is my favorite article on B-tree internals.
Jeremy Cole has done MySQL at Twitter, Google, and Shopify. One of the most knowledgeable MySQL engineers in the world, and his blog is an information goldmine.
blog.jcole.us/2013/01/10/b...
Jeremy Cole has done MySQL at Twitter, Google, and Shopify. One of the most knowledgeable MySQL engineers in the world, and his blog is an information goldmine.
blog.jcole.us/2013/01/10/b...
October 27, 2025 at 2:36 PM
This is my favorite article on B-tree internals.
Jeremy Cole has done MySQL at Twitter, Google, and Shopify. One of the most knowledgeable MySQL engineers in the world, and his blog is an information goldmine.
blog.jcole.us/2013/01/10/b...
Jeremy Cole has done MySQL at Twitter, Google, and Shopify. One of the most knowledgeable MySQL engineers in the world, and his blog is an information goldmine.
blog.jcole.us/2013/01/10/b...
Comparing latencies for Claude, GPT-5, Grok, and Gemini.
My personal biggest takeaway? Gemini is fast! I mostly stick with Claude but maybe I should give it a go.
My personal biggest takeaway? Gemini is fast! I mostly stick with Claude but maybe I should give it a go.
October 26, 2025 at 2:45 PM
Comparing latencies for Claude, GPT-5, Grok, and Gemini.
My personal biggest takeaway? Gemini is fast! I mostly stick with Claude but maybe I should give it a go.
My personal biggest takeaway? Gemini is fast! I mostly stick with Claude but maybe I should give it a go.
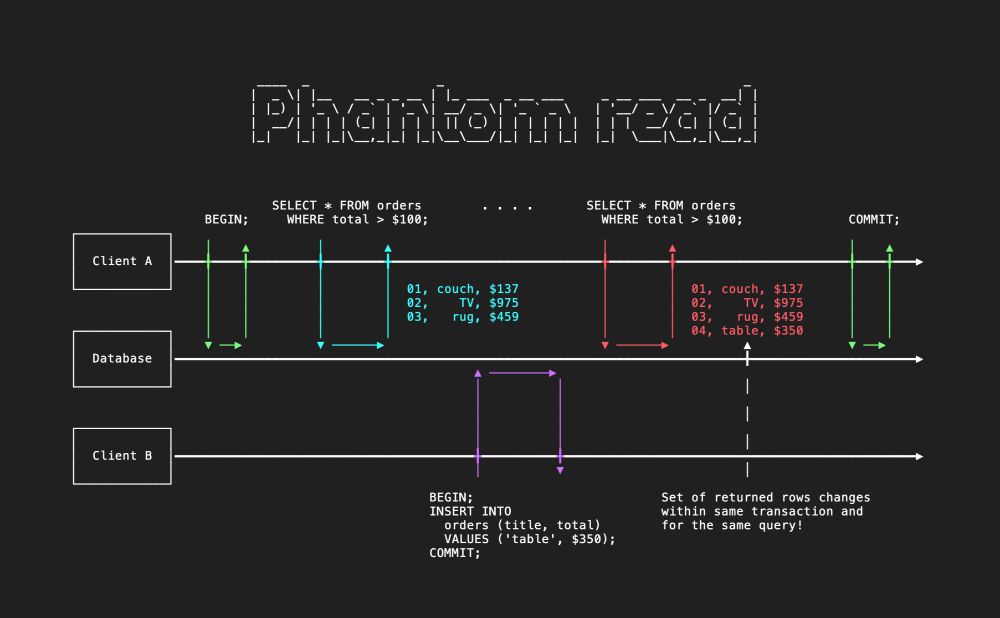
Beware of phantom reads.
In both Postgres and MySQL, it's possible for identical SELECTs in the same transaction to see different results.
In both Postgres and MySQL, it's possible for identical SELECTs in the same transaction to see different results.
October 23, 2025 at 2:33 PM
Beware of phantom reads.
In both Postgres and MySQL, it's possible for identical SELECTs in the same transaction to see different results.
In both Postgres and MySQL, it's possible for identical SELECTs in the same transaction to see different results.
Years of database operations compressed into a 5 minute read.
Required reading for everyone building applications in the cloud.
Required reading for everyone building applications in the cloud.
PlanetScale's fault tolerance relies on simple principles, processes, and architectures, but the real work is in the execution. These are the principles we follow to keep our systems reliable.
planetscale.com/blog/the-pri...
planetscale.com/blog/the-pri...

The principles of extreme fault tolerance — PlanetScale
The principles and processes we follow for fault tolerance.
planetscale.com
October 21, 2025 at 4:57 PM
Years of database operations compressed into a 5 minute read.
Required reading for everyone building applications in the cloud.
Required reading for everyone building applications in the cloud.
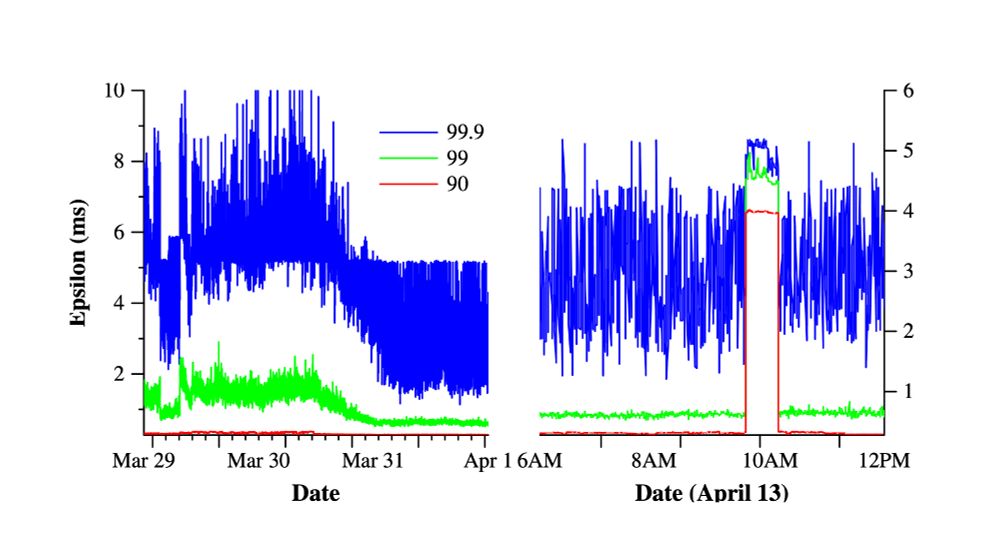
The Google Spanner paper is a 10/10 read.
The most interesting bit? TrueTime, an API that gives time results with error bounds, and one that guarantees <= 7 ms of clock skew. Impressive!
The downside? Not OSS. Even if it were, would require reproducing the timing hardware.
The most interesting bit? TrueTime, an API that gives time results with error bounds, and one that guarantees <= 7 ms of clock skew. Impressive!
The downside? Not OSS. Even if it were, would require reproducing the timing hardware.
October 20, 2025 at 2:39 PM
The Google Spanner paper is a 10/10 read.
The most interesting bit? TrueTime, an API that gives time results with error bounds, and one that guarantees <= 7 ms of clock skew. Impressive!
The downside? Not OSS. Even if it were, would require reproducing the timing hardware.
The most interesting bit? TrueTime, an API that gives time results with error bounds, and one that guarantees <= 7 ms of clock skew. Impressive!
The downside? Not OSS. Even if it were, would require reproducing the timing hardware.
My half-finished "Transactions" article has been sitting dormant for awhile.
Time to bring it back?
Started this long before PlanetScale Postgres. Would be a fun opportunity to compare the MVCC models of Postgres and MySQL.
Time to bring it back?
Started this long before PlanetScale Postgres. Would be a fun opportunity to compare the MVCC models of Postgres and MySQL.
October 17, 2025 at 2:54 PM
My half-finished "Transactions" article has been sitting dormant for awhile.
Time to bring it back?
Started this long before PlanetScale Postgres. Would be a fun opportunity to compare the MVCC models of Postgres and MySQL.
Time to bring it back?
Started this long before PlanetScale Postgres. Would be a fun opportunity to compare the MVCC models of Postgres and MySQL.
Any component can fail at any time in distributed systems.
How do you communicate in the face of unreliability? It's not easy!
This is classically known as the "two generals problem" and is a great way to think about communicating over unreliable channels.
How do you communicate in the face of unreliability? It's not easy!
This is classically known as the "two generals problem" and is a great way to think about communicating over unreliable channels.

October 16, 2025 at 2:06 PM
Any component can fail at any time in distributed systems.
How do you communicate in the face of unreliability? It's not easy!
This is classically known as the "two generals problem" and is a great way to think about communicating over unreliable channels.
How do you communicate in the face of unreliability? It's not easy!
This is classically known as the "two generals problem" and is a great way to think about communicating over unreliable channels.
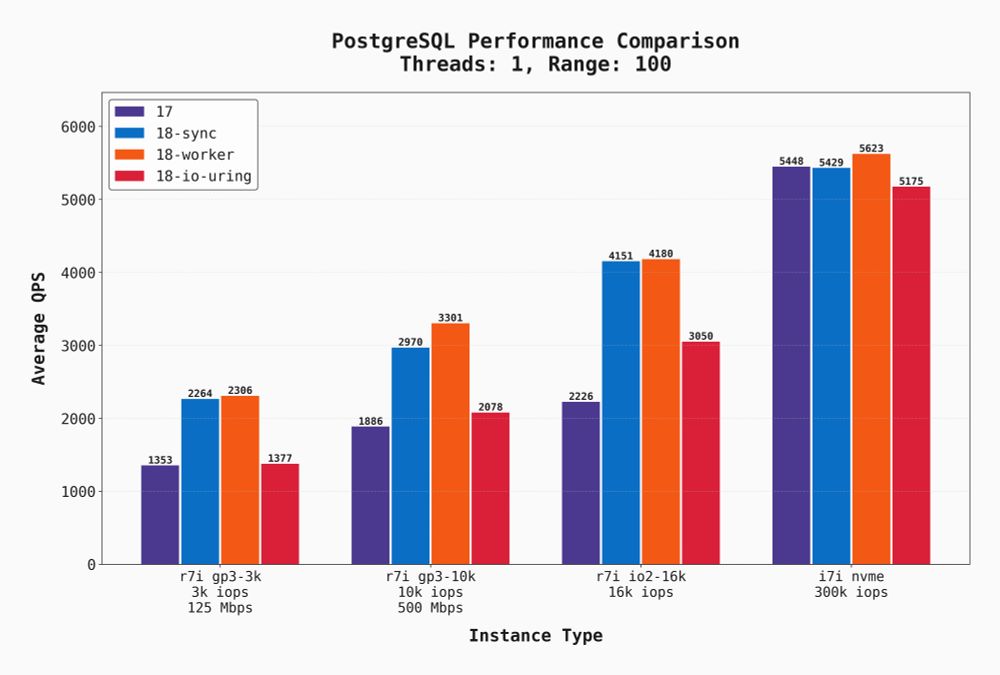
Biggest surprise from my Postgres 17 vs 18 benchmarks?
io_uring was frequently the worst performer!
It was slower than both `sync` and `worker` in many cases. Tomas Vondra has a wonderful article explaining why it isn't always the best choice.
vondra.me/posts/tuning...
io_uring was frequently the worst performer!
It was slower than both `sync` and `worker` in many cases. Tomas Vondra has a wonderful article explaining why it isn't always the best choice.
vondra.me/posts/tuning...
October 15, 2025 at 2:24 PM
Biggest surprise from my Postgres 17 vs 18 benchmarks?
io_uring was frequently the worst performer!
It was slower than both `sync` and `worker` in many cases. Tomas Vondra has a wonderful article explaining why it isn't always the best choice.
vondra.me/posts/tuning...
io_uring was frequently the worst performer!
It was slower than both `sync` and `worker` in many cases. Tomas Vondra has a wonderful article explaining why it isn't always the best choice.
vondra.me/posts/tuning...
I benchmarked 96 combinations of Postgres 17 and 18.
There's a few surprising results, but overall Postgres 18 has some nice improvements.
Read all about it at the link below.
There's a few surprising results, but overall Postgres 18 has some nice improvements.
Read all about it at the link below.
October 14, 2025 at 3:47 PM
I benchmarked 96 combinations of Postgres 17 and 18.
There's a few surprising results, but overall Postgres 18 has some nice improvements.
Read all about it at the link below.
There's a few surprising results, but overall Postgres 18 has some nice improvements.
Read all about it at the link below.
Two ways to replicate in Postgres: Physical and Logical.
Both great features with different tradeoffs.
Both great features with different tradeoffs.

October 13, 2025 at 3:38 PM
Two ways to replicate in Postgres: Physical and Logical.
Both great features with different tradeoffs.
Both great features with different tradeoffs.
Have a row contention problem? Try slotted counters!
This is a neat technique for spreading out increments across many rows to reduce contention.
This is a neat technique for spreading out increments across many rows to reduce contention.

October 9, 2025 at 2:31 PM
Have a row contention problem? Try slotted counters!
This is a neat technique for spreading out increments across many rows to reduce contention.
This is a neat technique for spreading out increments across many rows to reduce contention.