



Augment Code
@augmentcode.com
The Developer AI that deeply understands your codebase and how your team builds software. Augment puts your team’s collective knowledge at your fingertips.
Claude Sonnet 4.5 from Anthropic is now the default model for Augment Code.
We’re rolling it out to all customers over the next 24 hours, where it will be available alongside Sonnet 4 (for a limited time) and GPT-5 in the model picker.
We’re rolling it out to all customers over the next 24 hours, where it will be available alongside Sonnet 4 (for a limited time) and GPT-5 in the model picker.
September 29, 2025 at 5:08 PM
Claude Sonnet 4.5 from Anthropic is now the default model for Augment Code.
We’re rolling it out to all customers over the next 24 hours, where it will be available alongside Sonnet 4 (for a limited time) and GPT-5 in the model picker.
We’re rolling it out to all customers over the next 24 hours, where it will be available alongside Sonnet 4 (for a limited time) and GPT-5 in the model picker.
The Auggie CLI is now available for everyone.
Auggie brings Augment’s industry-leading context engine to every part of your stack—terminal, CI, and beyond.
Getting started is simple:
npm install -g @augmentcode/auggie
www.augmentcode.com/product/CLI
Auggie brings Augment’s industry-leading context engine to every part of your stack—terminal, CI, and beyond.
Getting started is simple:
npm install -g @augmentcode/auggie
www.augmentcode.com/product/CLI

August 28, 2025 at 8:32 PM
The Auggie CLI is now available for everyone.
Auggie brings Augment’s industry-leading context engine to every part of your stack—terminal, CI, and beyond.
Getting started is simple:
npm install -g @augmentcode/auggie
www.augmentcode.com/product/CLI
Auggie brings Augment’s industry-leading context engine to every part of your stack—terminal, CI, and beyond.
Getting started is simple:
npm install -g @augmentcode/auggie
www.augmentcode.com/product/CLI
Every project, team, and workflow is unique.
Augment Rules empower you to specify exactly how your agent should behave. Simply add instruction files to .augment/rules/ and your agent will adapt.
Augment Rules empower you to specify exactly how your agent should behave. Simply add instruction files to .augment/rules/ and your agent will adapt.

July 9, 2025 at 9:22 PM
Every project, team, and workflow is unique.
Augment Rules empower you to specify exactly how your agent should behave. Simply add instruction files to .augment/rules/ and your agent will adapt.
Augment Rules empower you to specify exactly how your agent should behave. Simply add instruction files to .augment/rules/ and your agent will adapt.
With Augment Rules, your software agent can build just like your team does.

July 9, 2025 at 9:22 PM
With Augment Rules, your software agent can build just like your team does.
PS: That’s why we built Prompt Enhancer —it auto-pulls context from your codebase and rewrites your prompt for clarity.
Available now in VS Code & JetBrains: just click ✨ and ship better prompts, faster.
Available now in VS Code & JetBrains: just click ✨ and ship better prompts, faster.
July 3, 2025 at 5:15 PM
PS: That’s why we built Prompt Enhancer —it auto-pulls context from your codebase and rewrites your prompt for clarity.
Available now in VS Code & JetBrains: just click ✨ and ship better prompts, faster.
Available now in VS Code & JetBrains: just click ✨ and ship better prompts, faster.
Guess now we can predict Asia's lunch time 💀
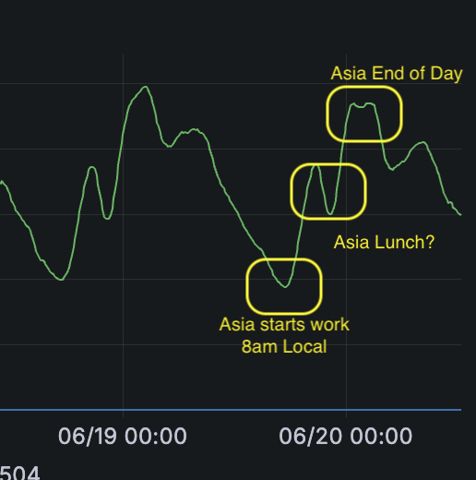
July 2, 2025 at 4:14 PM
Guess now we can predict Asia's lunch time 💀
🆕 Mermaid diagrams in Augment Agent
Agent reads your codebase, understands structure, and renders a Mermaid diagram—directly from your prompt.
Agent reads your codebase, understands structure, and renders a Mermaid diagram—directly from your prompt.
May 29, 2025 at 3:39 PM
🆕 Mermaid diagrams in Augment Agent
Agent reads your codebase, understands structure, and renders a Mermaid diagram—directly from your prompt.
Agent reads your codebase, understands structure, and renders a Mermaid diagram—directly from your prompt.
But it’s not just about question quality.
We needed a benchmark that could evolve with the product. So we designed AugmentQA as a loop — not a static test.
The cycle looks like this:
We needed a benchmark that could evolve with the product. So we designed AugmentQA as a loop — not a static test.
The cycle looks like this:

May 16, 2025 at 6:06 PM
But it’s not just about question quality.
We needed a benchmark that could evolve with the product. So we designed AugmentQA as a loop — not a static test.
The cycle looks like this:
We needed a benchmark that could evolve with the product. So we designed AugmentQA as a loop — not a static test.
The cycle looks like this:
❌ “Write better prompts.”
✅ Just click Enhance ✨
✅ Just click Enhance ✨
May 14, 2025 at 5:09 PM
❌ “Write better prompts.”
✅ Just click Enhance ✨
✅ Just click Enhance ✨
Is left vs right panel chat placement the new tabs vs spaces?
Drop your take in the comments
Drop your take in the comments

May 1, 2025 at 5:04 PM
Is left vs right panel chat placement the new tabs vs spaces?
Drop your take in the comments
Drop your take in the comments
UI’s broken. It’s obvious on screen.
But tracking down the cause? Hours of inspecting styles and guessing at layout logic.
Drag the bug into our agent. It analyzes the UI, finds the root cause, and proposes a fix — with context.
But tracking down the cause? Hours of inspecting styles and guessing at layout logic.
Drag the bug into our agent. It analyzes the UI, finds the root cause, and proposes a fix — with context.
April 18, 2025 at 5:29 PM
UI’s broken. It’s obvious on screen.
But tracking down the cause? Hours of inspecting styles and guessing at layout logic.
Drag the bug into our agent. It analyzes the UI, finds the root cause, and proposes a fix — with context.
But tracking down the cause? Hours of inspecting styles and guessing at layout logic.
Drag the bug into our agent. It analyzes the UI, finds the root cause, and proposes a fix — with context.
𝐆𝐏𝐓-𝟒.𝟏 𝐚𝐥𝐦𝐨𝐬𝐭 𝐭𝐨𝐩𝐬 𝐂𝐥𝐚𝐮𝐝𝐞 𝟑.𝟕 𝐨𝐧 𝐜𝐨𝐝𝐢𝐧𝐠?!
New eval dropping using our #1 SWE-bench coding agent!
- GPT-4.1 beats Gemini 2.5 Pro and almost tops Claude
3.7 Sonnet!
- Even GPT-4.1 mini matches Claude 3.5 Sonnet V2
performance. It was the top model just 2mo ago!
New eval dropping using our #1 SWE-bench coding agent!
- GPT-4.1 beats Gemini 2.5 Pro and almost tops Claude
3.7 Sonnet!
- Even GPT-4.1 mini matches Claude 3.5 Sonnet V2
performance. It was the top model just 2mo ago!

April 15, 2025 at 12:04 AM
𝐆𝐏𝐓-𝟒.𝟏 𝐚𝐥𝐦𝐨𝐬𝐭 𝐭𝐨𝐩𝐬 𝐂𝐥𝐚𝐮𝐝𝐞 𝟑.𝟕 𝐨𝐧 𝐜𝐨𝐝𝐢𝐧𝐠?!
New eval dropping using our #1 SWE-bench coding agent!
- GPT-4.1 beats Gemini 2.5 Pro and almost tops Claude
3.7 Sonnet!
- Even GPT-4.1 mini matches Claude 3.5 Sonnet V2
performance. It was the top model just 2mo ago!
New eval dropping using our #1 SWE-bench coding agent!
- GPT-4.1 beats Gemini 2.5 Pro and almost tops Claude
3.7 Sonnet!
- Even GPT-4.1 mini matches Claude 3.5 Sonnet V2
performance. It was the top model just 2mo ago!
LLaMa 4 beats Deepseek-R1 and V3 on coding?!
Fresh evaluation using our #1 SWE-bench coding agent and >200,000,000 tokens of production-grade code:
Claude 3.7 Sonnet > Gemini 2.5 Pro > LLaMA 4 Maverick > DeepSeek-V3 > Deepseek-R1
Fresh evaluation using our #1 SWE-bench coding agent and >200,000,000 tokens of production-grade code:
Claude 3.7 Sonnet > Gemini 2.5 Pro > LLaMA 4 Maverick > DeepSeek-V3 > Deepseek-R1

April 10, 2025 at 8:19 PM
LLaMa 4 beats Deepseek-R1 and V3 on coding?!
Fresh evaluation using our #1 SWE-bench coding agent and >200,000,000 tokens of production-grade code:
Claude 3.7 Sonnet > Gemini 2.5 Pro > LLaMA 4 Maverick > DeepSeek-V3 > Deepseek-R1
Fresh evaluation using our #1 SWE-bench coding agent and >200,000,000 tokens of production-grade code:
Claude 3.7 Sonnet > Gemini 2.5 Pro > LLaMA 4 Maverick > DeepSeek-V3 > Deepseek-R1
9/ While Agent is running…
- Skill grows over time.
- Beginners: observe and approve
- Intermediates: multitask
Power users: collaborate + course-correct in real time
- Skill grows over time.
- Beginners: observe and approve
- Intermediates: multitask
Power users: collaborate + course-correct in real time

April 4, 2025 at 7:29 PM
9/ While Agent is running…
- Skill grows over time.
- Beginners: observe and approve
- Intermediates: multitask
Power users: collaborate + course-correct in real time
- Skill grows over time.
- Beginners: observe and approve
- Intermediates: multitask
Power users: collaborate + course-correct in real time
7/ What if it messes up?
- If it's totally off: start a new session
- If it's slightly off: nudge it back
Bonus: Use checkpoints to undo mistakes.
- If it's totally off: start a new session
- If it's slightly off: nudge it back
Bonus: Use checkpoints to undo mistakes.

April 4, 2025 at 7:29 PM
7/ What if it messes up?
- If it's totally off: start a new session
- If it's slightly off: nudge it back
Bonus: Use checkpoints to undo mistakes.
- If it's totally off: start a new session
- If it's slightly off: nudge it back
Bonus: Use checkpoints to undo mistakes.
2/ How should I prompt?
Don't under-specify.
More details → better results.
Don't under-specify.
More details → better results.

April 4, 2025 at 7:29 PM
2/ How should I prompt?
Don't under-specify.
More details → better results.
Don't under-specify.
More details → better results.
Unlimited Agent, for a limited time.
We want to hear from our community and see how you use agents, because pricing should be fair and predictable.
Try it out now. We’ll update to usage pricing in the future.
We want to hear from our community and see how you use agents, because pricing should be fair and predictable.
Try it out now. We’ll update to usage pricing in the future.

April 3, 2025 at 12:08 AM
Unlimited Agent, for a limited time.
We want to hear from our community and see how you use agents, because pricing should be fair and predictable.
Try it out now. We’ll update to usage pricing in the future.
We want to hear from our community and see how you use agents, because pricing should be fair and predictable.
Try it out now. We’ll update to usage pricing in the future.
Built on our Context Engine and extended via MCP:
- Supabase, Figma, Vercel, Cloudflare, Sentry, and more
- Connect your stack in seconds
- Add your own tools to the agent's context
Don’t just write code, build software.
- Supabase, Figma, Vercel, Cloudflare, Sentry, and more
- Connect your stack in seconds
- Add your own tools to the agent's context
Don’t just write code, build software.
April 3, 2025 at 12:08 AM
Built on our Context Engine and extended via MCP:
- Supabase, Figma, Vercel, Cloudflare, Sentry, and more
- Connect your stack in seconds
- Add your own tools to the agent's context
Don’t just write code, build software.
- Supabase, Figma, Vercel, Cloudflare, Sentry, and more
- Connect your stack in seconds
- Add your own tools to the agent's context
Don’t just write code, build software.
🛡️ Code Checkpoints
Every step is logged. Every edit is reversible.
Agent creates checkpoints before running actions — giving you full control without slowing you down.
Like version control for your AI.
Every step is logged. Every edit is reversible.
Agent creates checkpoints before running actions — giving you full control without slowing you down.
Like version control for your AI.
April 3, 2025 at 12:08 AM
🛡️ Code Checkpoints
Every step is logged. Every edit is reversible.
Agent creates checkpoints before running actions — giving you full control without slowing you down.
Like version control for your AI.
Every step is logged. Every edit is reversible.
Agent creates checkpoints before running actions — giving you full control without slowing you down.
Like version control for your AI.
🐛Visual debugging.
- Drag in a screenshot.
- Agent identifies the UI issue (CSS, layout, logic).
- Suggests a fix.
- Runs only the relevant tests.
Debugging becomes: drop, fix, confirm.
- Drag in a screenshot.
- Agent identifies the UI issue (CSS, layout, logic).
- Suggests a fix.
- Runs only the relevant tests.
Debugging becomes: drop, fix, confirm.
April 3, 2025 at 12:08 AM
🐛Visual debugging.
- Drag in a screenshot.
- Agent identifies the UI issue (CSS, layout, logic).
- Suggests a fix.
- Runs only the relevant tests.
Debugging becomes: drop, fix, confirm.
- Drag in a screenshot.
- Agent identifies the UI issue (CSS, layout, logic).
- Suggests a fix.
- Runs only the relevant tests.
Debugging becomes: drop, fix, confirm.
⚙️ Integrated Dev Workflows
Use Agent to go from ticket → code → PR without switching tools:
- GitHub: branch, commit, PR
- Linear: issue detection + resolution
- Notion, JIRA, Confluence: context → implementation
AI becomes part of your actual workflow.
Use Agent to go from ticket → code → PR without switching tools:
- GitHub: branch, commit, PR
- Linear: issue detection + resolution
- Notion, JIRA, Confluence: context → implementation
AI becomes part of your actual workflow.
April 3, 2025 at 12:08 AM
⚙️ Integrated Dev Workflows
Use Agent to go from ticket → code → PR without switching tools:
- GitHub: branch, commit, PR
- Linear: issue detection + resolution
- Notion, JIRA, Confluence: context → implementation
AI becomes part of your actual workflow.
Use Agent to go from ticket → code → PR without switching tools:
- GitHub: branch, commit, PR
- Linear: issue detection + resolution
- Notion, JIRA, Confluence: context → implementation
AI becomes part of your actual workflow.
🧩 Persistent Memory
Agent adapts to how you work:
- Learns your coding style
- Remembers previous refactors
- Adjusts to your infra and conventions
Memory builds over time. You don’t have to re-teach it on every session.
Agent adapts to how you work:
- Learns your coding style
- Remembers previous refactors
- Adjusts to your infra and conventions
Memory builds over time. You don’t have to re-teach it on every session.
April 3, 2025 at 12:08 AM
🧩 Persistent Memory
Agent adapts to how you work:
- Learns your coding style
- Remembers previous refactors
- Adjusts to your infra and conventions
Memory builds over time. You don’t have to re-teach it on every session.
Agent adapts to how you work:
- Learns your coding style
- Remembers previous refactors
- Adjusts to your infra and conventions
Memory builds over time. You don’t have to re-teach it on every session.
🧵 We just released the #1 open-source agent on the SWE-bench Verified leaderboard by assembling the best of Claude Sonnet 3.7 and O1.
Open-source repo here: github.com/augmentcode/...
Here's how we achieved 65.4% success rate on the hardest coding benchmark in the industry: 🧠👇
Open-source repo here: github.com/augmentcode/...
Here's how we achieved 65.4% success rate on the hardest coding benchmark in the industry: 🧠👇

March 31, 2025 at 9:30 PM
🧵 We just released the #1 open-source agent on the SWE-bench Verified leaderboard by assembling the best of Claude Sonnet 3.7 and O1.
Open-source repo here: github.com/augmentcode/...
Here's how we achieved 65.4% success rate on the hardest coding benchmark in the industry: 🧠👇
Open-source repo here: github.com/augmentcode/...
Here's how we achieved 65.4% success rate on the hardest coding benchmark in the industry: 🧠👇
When tested against leading open-source models from the CoIR leaderboard, Augment's retrieval system significantly outperformed them on real tasks—even though those models ranked higher on synthetic tests. This demonstrates a critical gap between benchmark performance and practical utility.

March 25, 2025 at 9:16 PM
When tested against leading open-source models from the CoIR leaderboard, Augment's retrieval system significantly outperformed them on real tasks—even though those models ranked higher on synthetic tests. This demonstrates a critical gap between benchmark performance and practical utility.