



Atlas Wang
@atlaswang.bsky.social
https://www.vita-group.space/ 👨🏫 UT Austin ML Professor (on leave)
https://www.xtxmarkets.com/ 🏦 XTX Markets Research Director (NYC AI Lab)
Superpower is trying everything 🪅
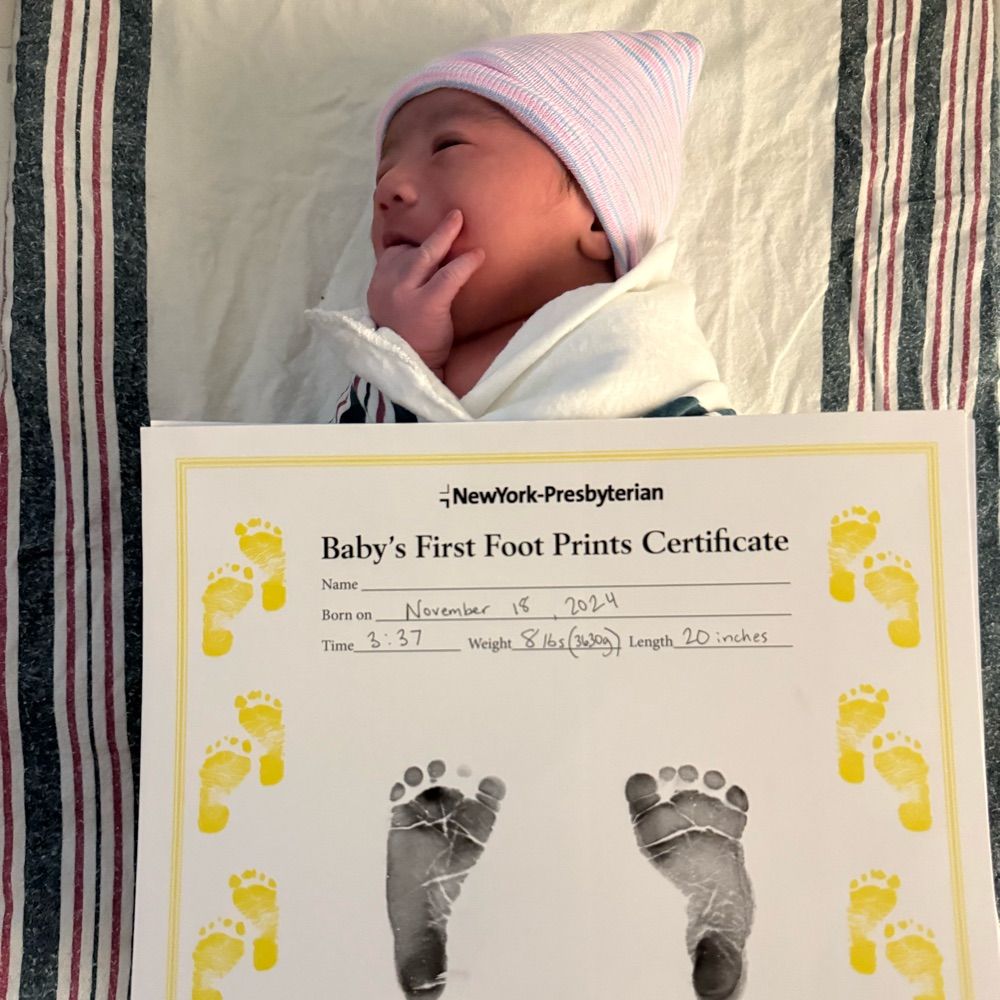
Newest focus: training next-generation super intelligence - Preview above 👶
https://www.xtxmarkets.com/ 🏦 XTX Markets Research Director (NYC AI Lab)
Superpower is trying everything 🪅
Newest focus: training next-generation super intelligence - Preview above 👶
Paying for a dinner I wasn’t even at 🤣 — momentum’s strong, keep it up team!
www.vita-group.space/team
www.vita-group.space/team

August 31, 2025 at 4:14 PM
Paying for a dinner I wasn’t even at 🤣 — momentum’s strong, keep it up team!
www.vita-group.space/team
www.vita-group.space/team
Making a new website of my research group, and did a visualization of all our papers from 2018 to present: clustered into 10 topics.
One can clearly see how this group evolves its own tastes!
… and deeper in my heart: long live optimization!! ❤️
One can clearly see how this group evolves its own tastes!
… and deeper in my heart: long live optimization!! ❤️

June 11, 2025 at 2:49 PM
Making a new website of my research group, and did a visualization of all our papers from 2018 to present: clustered into 10 topics.
One can clearly see how this group evolves its own tastes!
… and deeper in my heart: long live optimization!! ❤️
One can clearly see how this group evolves its own tastes!
… and deeper in my heart: long live optimization!! ❤️
Quoting one slides from @yann-lecun.bsky.social talk…
arxiv is filled by papers that treat symptoms (or not even!) without ever diagnosing the disease
arxiv is filled by papers that treat symptoms (or not even!) without ever diagnosing the disease

May 25, 2025 at 12:29 PM
Quoting one slides from @yann-lecun.bsky.social talk…
arxiv is filled by papers that treat symptoms (or not even!) without ever diagnosing the disease
arxiv is filled by papers that treat symptoms (or not even!) without ever diagnosing the disease
This accidental photo feels distinctly #american —industry and technology advancing, sometimes hesitantly, beneath the weight of religion and firearms

March 18, 2025 at 12:16 PM
This accidental photo feels distinctly #american —industry and technology advancing, sometimes hesitantly, beneath the weight of religion and firearms
🌍 Diplomacy – The ultimate test! Models had to negotiate, forge alliances, and occasionally backstab. Result? Even the best LLMs floundered, struggling to juggle complex social interactions and strategic depth.

March 18, 2025 at 11:18 AM
🌍 Diplomacy – The ultimate test! Models had to negotiate, forge alliances, and occasionally backstab. Result? Even the best LLMs floundered, struggling to juggle complex social interactions and strategic depth.
🎴 Cooperative Games (Hanabi): Coordination among teammates dramatically challenges models, causing their performance to dip sharply as complexity ramps up. Turns out, keeping track of your teammates’ intentions isn’t an easy task—even for GPTs!

March 18, 2025 at 11:18 AM
🎴 Cooperative Games (Hanabi): Coordination among teammates dramatically challenges models, causing their performance to dip sharply as complexity ramps up. Turns out, keeping track of your teammates’ intentions isn’t an easy task—even for GPTs!
Results fascinatingly reveal:
🔹 Classic Planning: LLMs ace simpler puzzles but struggle badly as complexity grows—losing track at longer-term decisions
🔎 Competitive Games: Top chess engines swept every LLM clean. Even simple tactical awareness quickly fades when facing deeper strategic branches
🔹 Classic Planning: LLMs ace simpler puzzles but struggle badly as complexity grows—losing track at longer-term decisions
🔎 Competitive Games: Top chess engines swept every LLM clean. Even simple tactical awareness quickly fades when facing deeper strategic branches

March 18, 2025 at 11:17 AM
Results fascinatingly reveal:
🔹 Classic Planning: LLMs ace simpler puzzles but struggle badly as complexity grows—losing track at longer-term decisions
🔎 Competitive Games: Top chess engines swept every LLM clean. Even simple tactical awareness quickly fades when facing deeper strategic branches
🔹 Classic Planning: LLMs ace simpler puzzles but struggle badly as complexity grows—losing track at longer-term decisions
🔎 Competitive Games: Top chess engines swept every LLM clean. Even simple tactical awareness quickly fades when facing deeper strategic branches
🚀 Thrilled to announce SPIN-Bench!🚀
We all love seeing how smart LLMs can be-solving complex math, crafting beautiful text, and coding effortlessly. But how well do they handle real-world strategic complexity, cooperation, & social negotiation? Can they play well when things get tricky?
Not quite!
We all love seeing how smart LLMs can be-solving complex math, crafting beautiful text, and coding effortlessly. But how well do they handle real-world strategic complexity, cooperation, & social negotiation? Can they play well when things get tricky?
Not quite!

March 18, 2025 at 11:14 AM
🚀 Thrilled to announce SPIN-Bench!🚀
We all love seeing how smart LLMs can be-solving complex math, crafting beautiful text, and coding effortlessly. But how well do they handle real-world strategic complexity, cooperation, & social negotiation? Can they play well when things get tricky?
Not quite!
We all love seeing how smart LLMs can be-solving complex math, crafting beautiful text, and coding effortlessly. But how well do they handle real-world strategic complexity, cooperation, & social negotiation? Can they play well when things get tricky?
Not quite!
The not-so-great-yet human intelligence wishes y’all Happy Holidays! 🎁🎄

December 24, 2024 at 3:29 PM
The not-so-great-yet human intelligence wishes y’all Happy Holidays! 🎁🎄
Bonus: It’s truly exciting to see how far strong optimization algorithms can push the boundaries.
The insights were drawn from the good old compressive sensing — RIP!!(optimization forks shall get my joke!) 😆
The insights were drawn from the good old compressive sensing — RIP!!(optimization forks shall get my joke!) 😆

December 10, 2024 at 1:14 PM
Bonus: It’s truly exciting to see how far strong optimization algorithms can push the boundaries.
The insights were drawn from the good old compressive sensing — RIP!!(optimization forks shall get my joke!) 😆
The insights were drawn from the good old compressive sensing — RIP!!(optimization forks shall get my joke!) 😆
(3/n) Why APOLLO⁉️
👊Memory❗
It for the first time enables pre-training LLaMA-13B with naive DDP on A100-80G without other system-level optimizations
👊Throughput❗
For LLaMA-7B pre-training 8×A100-80GB, supports 4× larger batch sizes, 3× training throughput, & maintaining the best perplexity reported
👊Memory❗
It for the first time enables pre-training LLaMA-13B with naive DDP on A100-80G without other system-level optimizations
👊Throughput❗
For LLaMA-7B pre-training 8×A100-80GB, supports 4× larger batch sizes, 3× training throughput, & maintaining the best perplexity reported

December 10, 2024 at 12:58 PM
(3/n) Why APOLLO⁉️
👊Memory❗
It for the first time enables pre-training LLaMA-13B with naive DDP on A100-80G without other system-level optimizations
👊Throughput❗
For LLaMA-7B pre-training 8×A100-80GB, supports 4× larger batch sizes, 3× training throughput, & maintaining the best perplexity reported
👊Memory❗
It for the first time enables pre-training LLaMA-13B with naive DDP on A100-80G without other system-level optimizations
👊Throughput❗
For LLaMA-7B pre-training 8×A100-80GB, supports 4× larger batch sizes, 3× training throughput, & maintaining the best perplexity reported
(2/n) We investigate the redundancy in Adam(W) and identify that it can be coarsened as a structured learning rate SGD.
APOLLO approximates channel/tensor-wise learning rate scaling with low-rank state, via pure random projection - no SVD!
It is highly tolerant to extremely low rank (even rank-1)
APOLLO approximates channel/tensor-wise learning rate scaling with low-rank state, via pure random projection - no SVD!
It is highly tolerant to extremely low rank (even rank-1)

December 10, 2024 at 12:54 PM
(2/n) We investigate the redundancy in Adam(W) and identify that it can be coarsened as a structured learning rate SGD.
APOLLO approximates channel/tensor-wise learning rate scaling with low-rank state, via pure random projection - no SVD!
It is highly tolerant to extremely low rank (even rank-1)
APOLLO approximates channel/tensor-wise learning rate scaling with low-rank state, via pure random projection - no SVD!
It is highly tolerant to extremely low rank (even rank-1)
(1/n) My favorite "optimizer" work of 2024:
📢 Introducing APOLLO! 🚀: SGD-like memory cost, yet AdamW-level performance (or better!).
❓ How much memory do we need for optimization states in LLM training ? 🧐
Almost zero.
📜 Paper: arxiv.org/abs/2412.05270
🔗 GitHub: github.com/zhuhanqing/A...
📢 Introducing APOLLO! 🚀: SGD-like memory cost, yet AdamW-level performance (or better!).
❓ How much memory do we need for optimization states in LLM training ? 🧐
Almost zero.
📜 Paper: arxiv.org/abs/2412.05270
🔗 GitHub: github.com/zhuhanqing/A...
December 10, 2024 at 12:53 PM
(1/n) My favorite "optimizer" work of 2024:
📢 Introducing APOLLO! 🚀: SGD-like memory cost, yet AdamW-level performance (or better!).
❓ How much memory do we need for optimization states in LLM training ? 🧐
Almost zero.
📜 Paper: arxiv.org/abs/2412.05270
🔗 GitHub: github.com/zhuhanqing/A...
📢 Introducing APOLLO! 🚀: SGD-like memory cost, yet AdamW-level performance (or better!).
❓ How much memory do we need for optimization states in LLM training ? 🧐
Almost zero.
📜 Paper: arxiv.org/abs/2412.05270
🔗 GitHub: github.com/zhuhanqing/A...

December 3, 2024 at 5:34 PM
🎉 #NeurIPS2024 is almost here, and the VITA group is bringing the heat (even if most of us are skipping the trip this year for family commitments, vacations...etc. Students and postdocs actually have lives! 😄)
We’re thrilled to present 9 main conference papers, 5 workshop papers and a keynote talk:
We’re thrilled to present 9 main conference papers, 5 workshop papers and a keynote talk:


December 3, 2024 at 12:08 PM
🎉 #NeurIPS2024 is almost here, and the VITA group is bringing the heat (even if most of us are skipping the trip this year for family commitments, vacations...etc. Students and postdocs actually have lives! 😄)
We’re thrilled to present 9 main conference papers, 5 workshop papers and a keynote talk:
We’re thrilled to present 9 main conference papers, 5 workshop papers and a keynote talk:
Seeing this from a quant finance textbook. Well said, calling out the pretense …

December 2, 2024 at 3:24 PM
Seeing this from a quant finance textbook. Well said, calling out the pretense …
First week of parenthood, I’ve discovered the ultimate productivity hack: feeding, burping, or changing diapers overnight. My email replies are sharp, and my brainstorming ideas flow like never before…Just don’t ask my sleep-deprived brain to remember any of them by morning!

November 24, 2024 at 9:25 PM
First week of parenthood, I’ve discovered the ultimate productivity hack: feeding, burping, or changing diapers overnight. My email replies are sharp, and my brainstorming ideas flow like never before…Just don’t ask my sleep-deprived brain to remember any of them by morning!
Received a PhD applicant email where the student dreams of developing AI for dementia care — and hopes it will ‘assist me in my senior age.’ Guess I should start training the model now… just in case!😂

November 22, 2024 at 2:27 AM
Received a PhD applicant email where the student dreams of developing AI for dementia care — and hopes it will ‘assist me in my senior age.’ Guess I should start training the model now… just in case!😂
The gradient oscillates rapidly during training of the next-generation superintelligence model (preview version).
Wanna call it Edge of Stability?
Wanna call it Edge of Stability?
November 21, 2024 at 7:31 PM
The gradient oscillates rapidly during training of the next-generation superintelligence model (preview version).
Wanna call it Edge of Stability?
Wanna call it Edge of Stability?