




Alexandra Proca
@aproca.bsky.social
PhD student at Imperial College London, currently visiting researcher at ENS Paris. theoretical neuroscience, machine learning. aproca.github.io
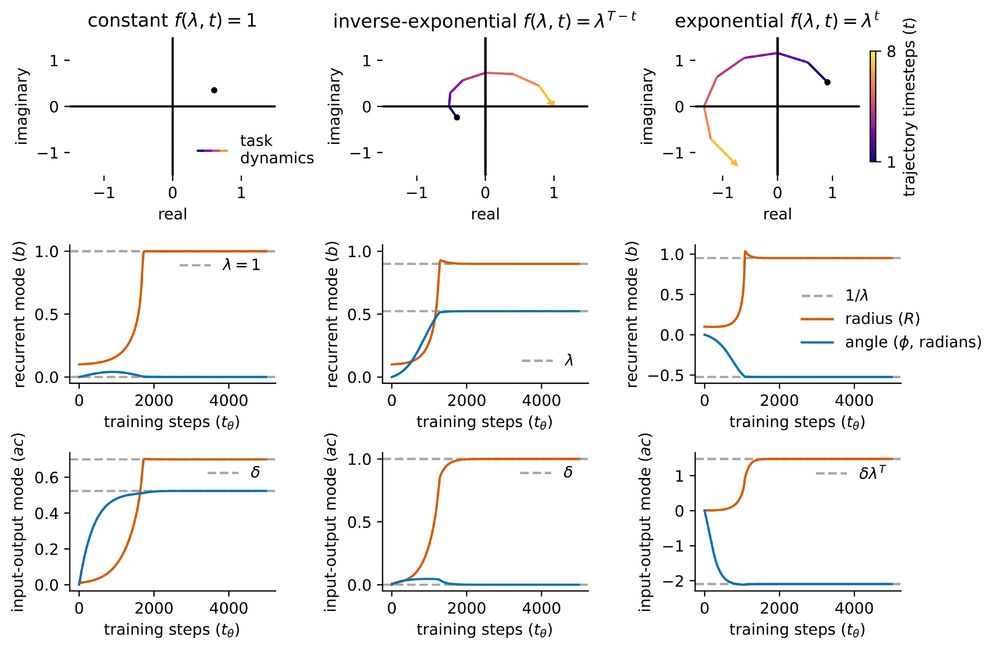
Finally, although many results we present are based on SVD, we also derive a form based on an eigendecomposition, allowing for rotational dynamics and to which our framework naturally extends to. We use this to study learning in terms of polar coordinates in the complex plane.
June 20, 2025 at 5:29 PM
Finally, although many results we present are based on SVD, we also derive a form based on an eigendecomposition, allowing for rotational dynamics and to which our framework naturally extends to. We use this to study learning in terms of polar coordinates in the complex plane.
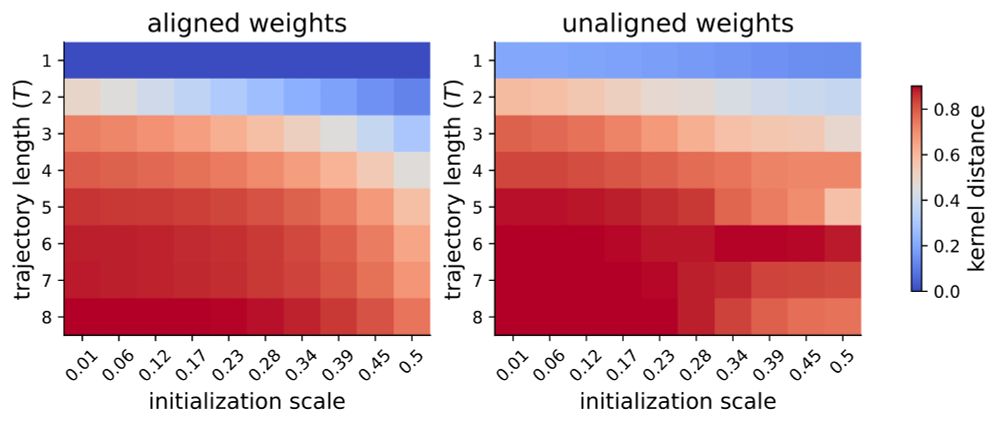
To study how recurrence might impact feature learning, we derive the NTK for finite-width LRNNs and evaluate its movement during training. We find that recurrence appears to facilitate kernel movement across many settings, suggesting a bias towards rich learning.
June 20, 2025 at 5:29 PM
To study how recurrence might impact feature learning, we derive the NTK for finite-width LRNNs and evaluate its movement during training. We find that recurrence appears to facilitate kernel movement across many settings, suggesting a bias towards rich learning.
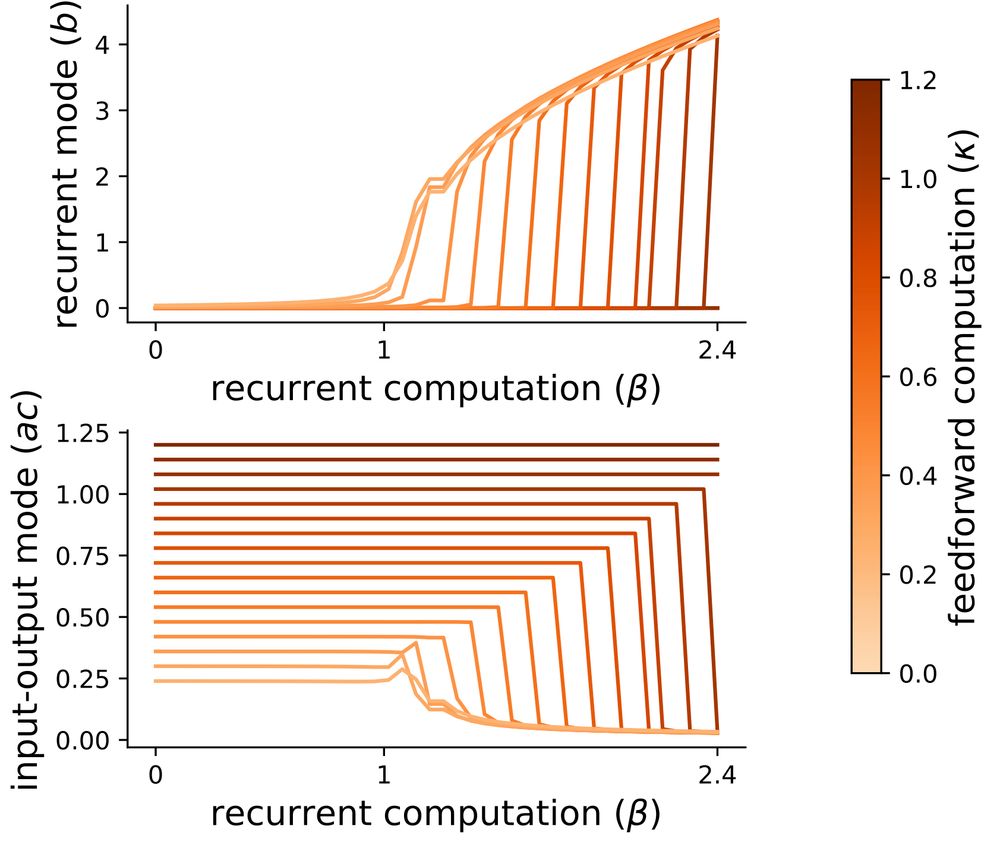
Motivated by this, we study task dynamics without zero-loss solutions and find that there exists a tradeoff between recurrent and feedforward computations that is characterized by a phase transition and leads to low-rank connectivity.
June 20, 2025 at 5:29 PM
Motivated by this, we study task dynamics without zero-loss solutions and find that there exists a tradeoff between recurrent and feedforward computations that is characterized by a phase transition and leads to low-rank connectivity.
By analyzing the energy function, we identify an effective regularization term that incentivizes small weights, especially when task dynamics are not perfectly learnable.
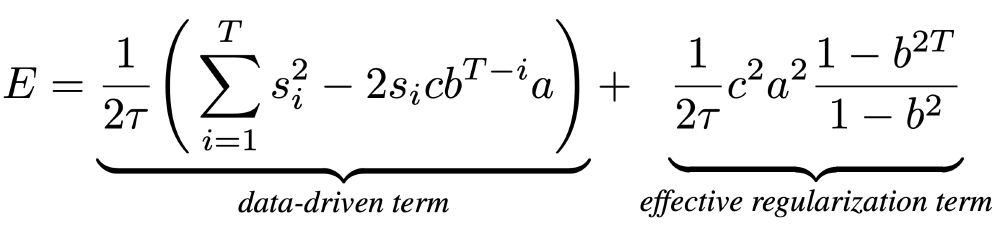
June 20, 2025 at 5:29 PM
By analyzing the energy function, we identify an effective regularization term that incentivizes small weights, especially when task dynamics are not perfectly learnable.
Additionally, these results predict behavior in networks performing integration tasks, where we relax our theoretical assumptions.
June 20, 2025 at 5:29 PM
Additionally, these results predict behavior in networks performing integration tasks, where we relax our theoretical assumptions.
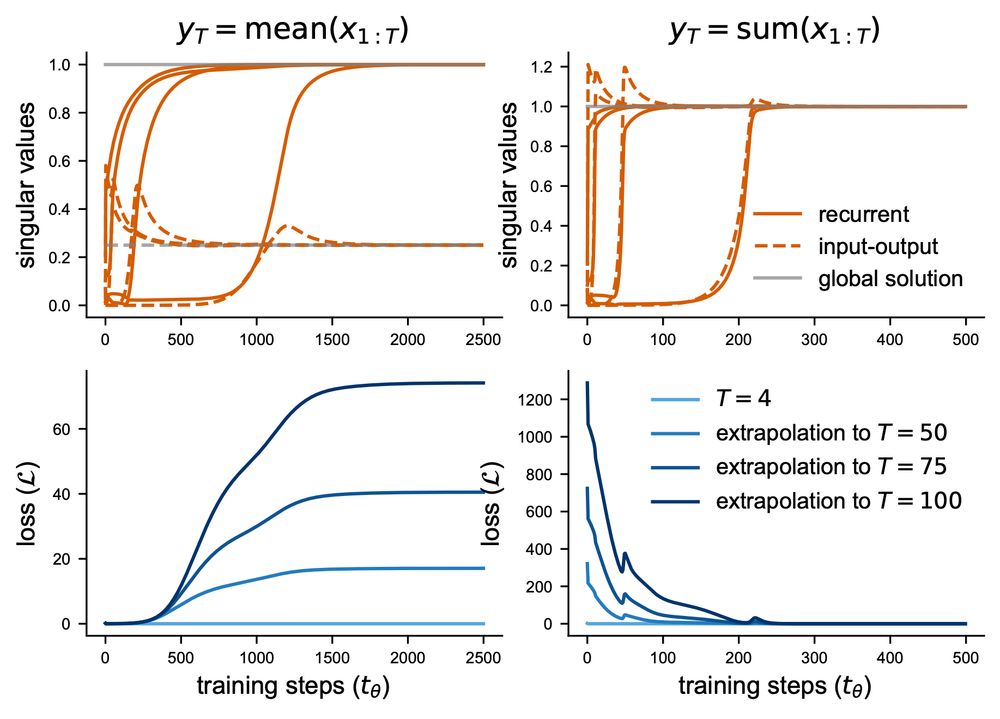
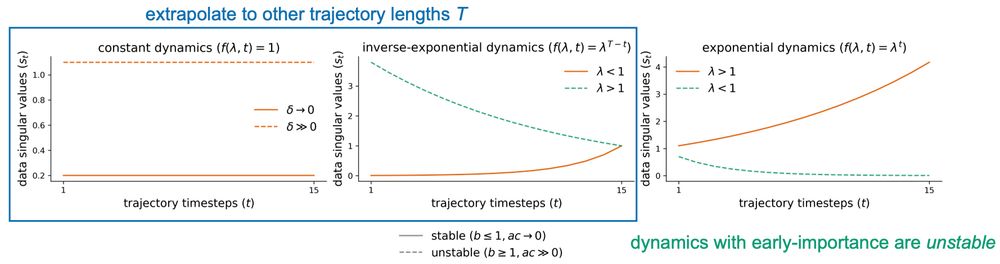
Next, we show that task dynamics determine a RNN’s ability to extrapolate to other sequence lengths and its hidden layer stability, even if there exists a perfect zero-loss solution.
June 20, 2025 at 5:29 PM
Next, we show that task dynamics determine a RNN’s ability to extrapolate to other sequence lengths and its hidden layer stability, even if there exists a perfect zero-loss solution.
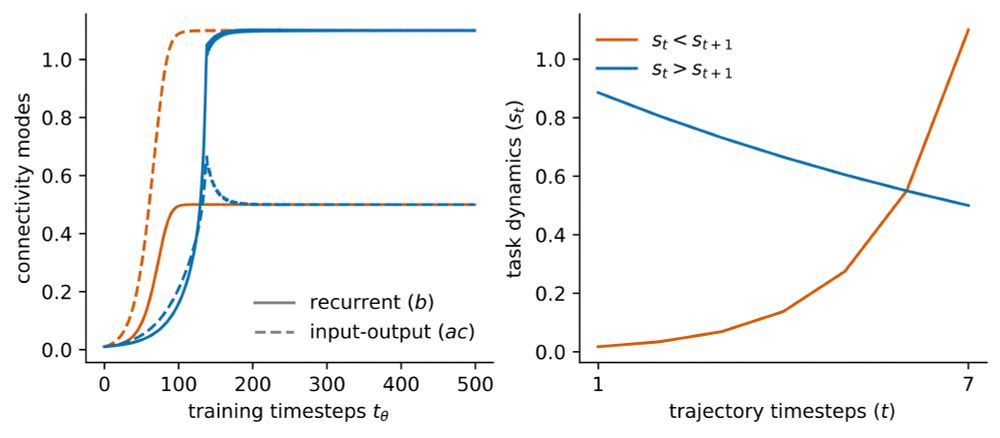
We find that learning speed is dependent on both the scale of SVs and their temporal ordering, such that SVs occurring later in the trajectory have a greater impact on learning speed.
June 20, 2025 at 5:29 PM
We find that learning speed is dependent on both the scale of SVs and their temporal ordering, such that SVs occurring later in the trajectory have a greater impact on learning speed.
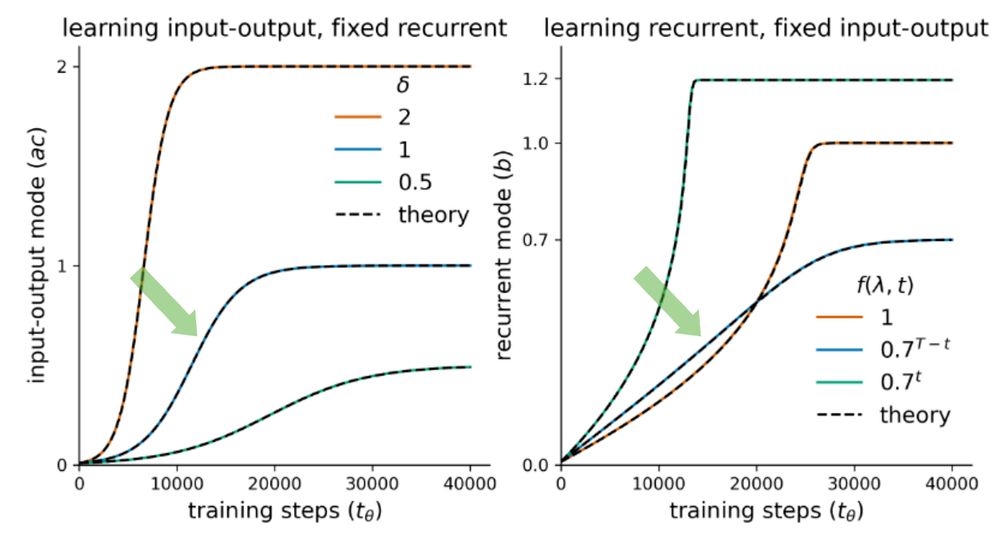
Using this form, we derive solutions to the learning dynamics of the input-output modes and local approximations of the recurrent modes separately, and identify differences in the learning dynamics of recurrent networks compared to feedforward ones.
June 20, 2025 at 5:29 PM
Using this form, we derive solutions to the learning dynamics of the input-output modes and local approximations of the recurrent modes separately, and identify differences in the learning dynamics of recurrent networks compared to feedforward ones.
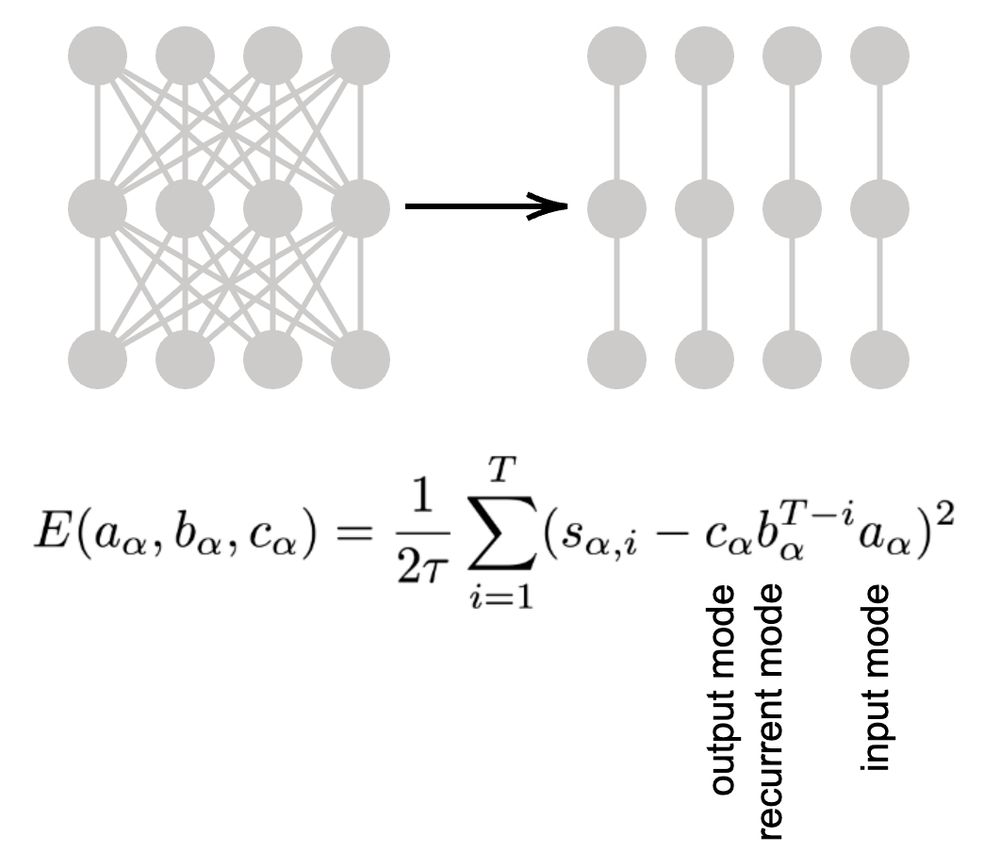
We derive a form where the task dynamics are fully specified by the data correlation singular values (or eigenvalues) across time (t=1:T), and learning is characterized by a set of gradient flow equations and energy function that are decoupled across different dimensions.
June 20, 2025 at 5:29 PM
We derive a form where the task dynamics are fully specified by the data correlation singular values (or eigenvalues) across time (t=1:T), and learning is characterized by a set of gradient flow equations and energy function that are decoupled across different dimensions.
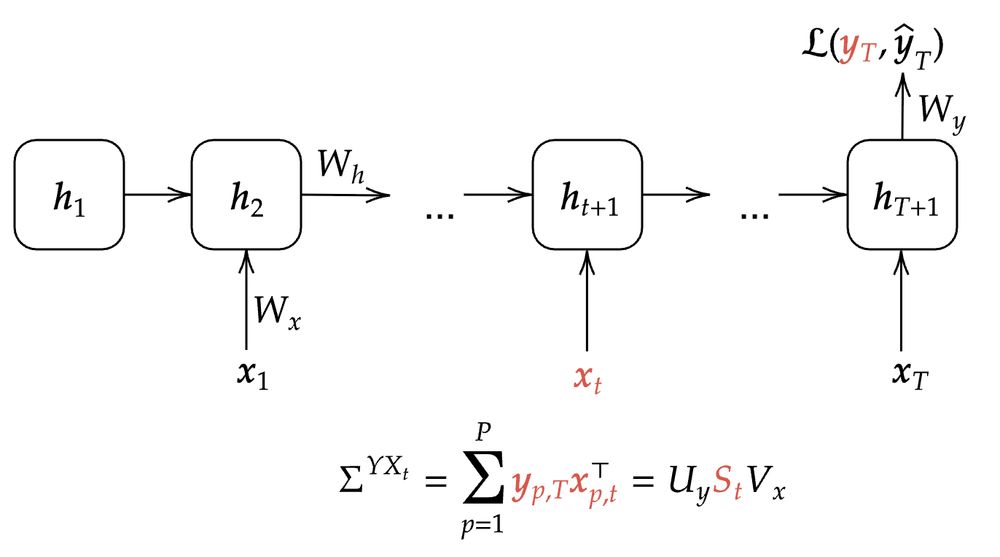
We study a RNN that receives an input at each timestep and produces a final output at the last timestep (and generalize to the autoregressive case later). For each input at time t and the output, we can construct correlation matrices and compute their SVD (or eigendecomposition).
June 20, 2025 at 5:29 PM
We study a RNN that receives an input at each timestep and produces a final output at the last timestep (and generalize to the autoregressive case later). For each input at time t and the output, we can construct correlation matrices and compute their SVD (or eigendecomposition).