



Andrew Lee
@ajyl.bsky.social
Post-doc @ Harvard. PhD UMich. Spent time at FAIR and MSR. ML/NLP/Interpretability
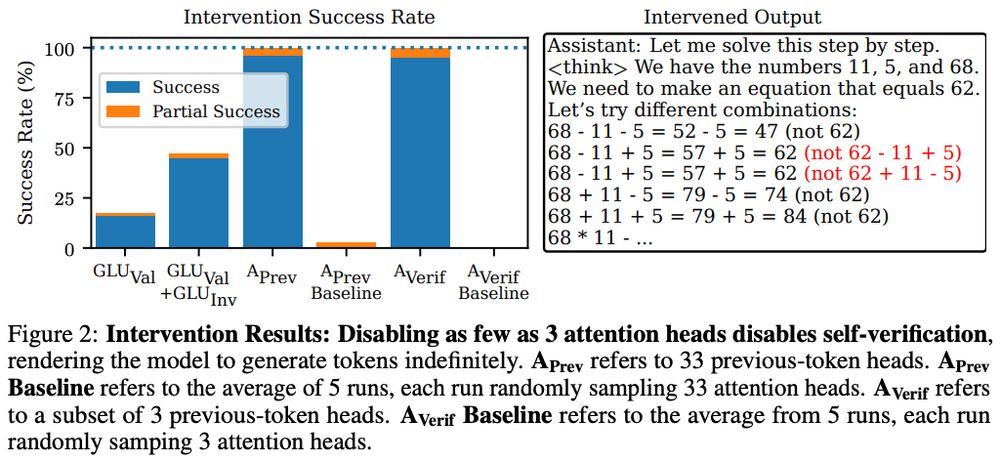
We find similar verif. subspaces in our base model and general reasoning model (DeepSeek R1-14B).
Here we provide CountDown as a ICL task.
Interestingly, in R1-14B, our interventions lead to partial success - the LM fails self-verification but then self-corrects itself.
7/n
Here we provide CountDown as a ICL task.
Interestingly, in R1-14B, our interventions lead to partial success - the LM fails self-verification but then self-corrects itself.
7/n

May 13, 2025 at 6:52 PM
We find similar verif. subspaces in our base model and general reasoning model (DeepSeek R1-14B).
Here we provide CountDown as a ICL task.
Interestingly, in R1-14B, our interventions lead to partial success - the LM fails self-verification but then self-corrects itself.
7/n
Here we provide CountDown as a ICL task.
Interestingly, in R1-14B, our interventions lead to partial success - the LM fails self-verification but then self-corrects itself.
7/n
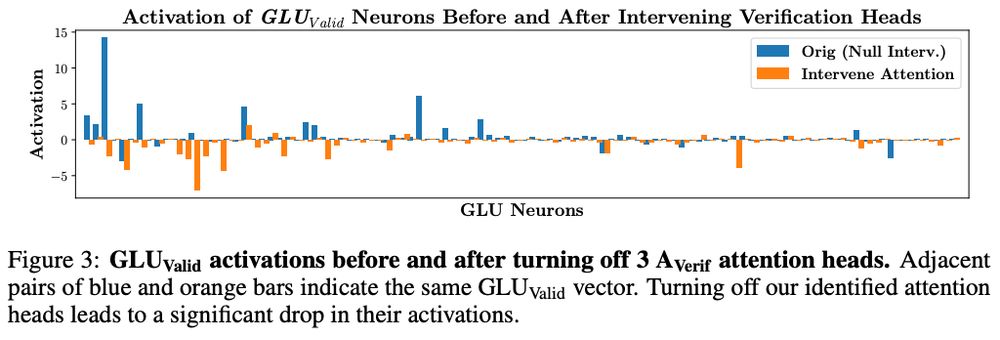
Our analyses meet in the middle:
We use “interlayer communication channels” to rank how much each head (OV circuit) aligns with the “receptive fields” of verification-related MLP weights.
Disable *three* heads → disables self-verif. and deactivates verif.-MLP weights.
6/n
We use “interlayer communication channels” to rank how much each head (OV circuit) aligns with the “receptive fields” of verification-related MLP weights.
Disable *three* heads → disables self-verif. and deactivates verif.-MLP weights.
6/n
May 13, 2025 at 6:52 PM
Our analyses meet in the middle:
We use “interlayer communication channels” to rank how much each head (OV circuit) aligns with the “receptive fields” of verification-related MLP weights.
Disable *three* heads → disables self-verif. and deactivates verif.-MLP weights.
6/n
We use “interlayer communication channels” to rank how much each head (OV circuit) aligns with the “receptive fields” of verification-related MLP weights.
Disable *three* heads → disables self-verif. and deactivates verif.-MLP weights.
6/n
Bottom-up, we find previous-token heads (i.e., parts of induction heads) are responsible for self-verification in our setup. Disabling previous-token heads disables self-verification.
5/n
5/n
May 13, 2025 at 6:52 PM
Bottom-up, we find previous-token heads (i.e., parts of induction heads) are responsible for self-verification in our setup. Disabling previous-token heads disables self-verification.
5/n
5/n
More importantly, we can use the probe to find MLP weights related to verification. Simply check for MLP weights with high cosine similarity to our probe.
Interestingly, we often see Eng. tokens for "valid direction" and Chinese tokens for "invalid direction".
4/n
Interestingly, we often see Eng. tokens for "valid direction" and Chinese tokens for "invalid direction".
4/n

May 13, 2025 at 6:52 PM
More importantly, we can use the probe to find MLP weights related to verification. Simply check for MLP weights with high cosine similarity to our probe.
Interestingly, we often see Eng. tokens for "valid direction" and Chinese tokens for "invalid direction".
4/n
Interestingly, we often see Eng. tokens for "valid direction" and Chinese tokens for "invalid direction".
4/n
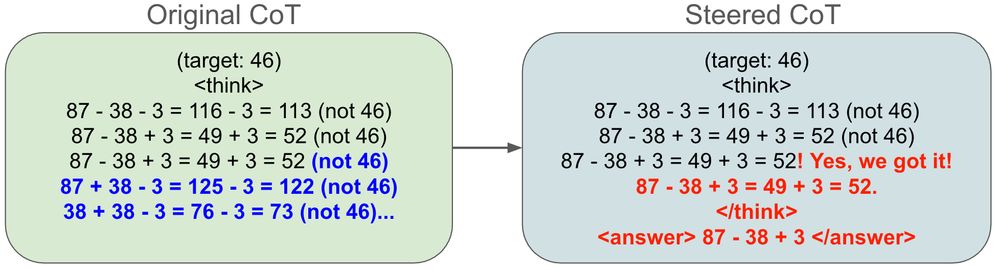
We do a “top-down” and “bottom-up” analysis. Top-down, we train a probe. We can use our probe to steer the model and trick it to have found a solution.
3/n
3/n
May 13, 2025 at 6:52 PM
We do a “top-down” and “bottom-up” analysis. Top-down, we train a probe. We can use our probe to steer the model and trick it to have found a solution.
3/n
3/n
CoT is unfaithful. Can we monitor inner computations in latent space instead?
Case study: Let’s study self-verification!
Setup: We train Qwen-3B on CountDown until mode collapse, resulting in nicely structured CoT that’s easy to parse+analyze
2/n
Case study: Let’s study self-verification!
Setup: We train Qwen-3B on CountDown until mode collapse, resulting in nicely structured CoT that’s easy to parse+analyze
2/n

May 13, 2025 at 6:52 PM
CoT is unfaithful. Can we monitor inner computations in latent space instead?
Case study: Let’s study self-verification!
Setup: We train Qwen-3B on CountDown until mode collapse, resulting in nicely structured CoT that’s easy to parse+analyze
2/n
Case study: Let’s study self-verification!
Setup: We train Qwen-3B on CountDown until mode collapse, resulting in nicely structured CoT that’s easy to parse+analyze
2/n
🚨New preprint!
How do reasoning models verify their own CoT?
We reverse-engineer LMs and find critical components and subspaces needed for self-verification!
1/n
How do reasoning models verify their own CoT?
We reverse-engineer LMs and find critical components and subspaces needed for self-verification!
1/n

May 13, 2025 at 6:52 PM
🚨New preprint!
How do reasoning models verify their own CoT?
We reverse-engineer LMs and find critical components and subspaces needed for self-verification!
1/n
How do reasoning models verify their own CoT?
We reverse-engineer LMs and find critical components and subspaces needed for self-verification!
1/n
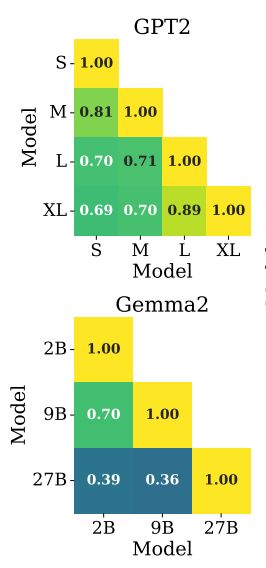
Interesting, I didn't know that! BTW, we find similar trends in GPT2 and Gemma2
May 7, 2025 at 1:56 PM
Interesting, I didn't know that! BTW, we find similar trends in GPT2 and Gemma2
We call this simple approach Emb2Emb: Here we steer Llama8B using steering vectors from Llama1B and 3B:
May 7, 2025 at 1:38 PM
We call this simple approach Emb2Emb: Here we steer Llama8B using steering vectors from Llama1B and 3B:
Now, steering vectors can be transferred across LMs. Given LM1, LM2 & their embeddings E1, E2, fit a linear transform T from E1 to E2. Given steering vector V for LM1, apply T onto V, and now TV can steer LM2. Unembedding V or TV shows similar nearest neighbors encoding the steer vector’s concept:

May 7, 2025 at 1:38 PM
Now, steering vectors can be transferred across LMs. Given LM1, LM2 & their embeddings E1, E2, fit a linear transform T from E1 to E2. Given steering vector V for LM1, apply T onto V, and now TV can steer LM2. Unembedding V or TV shows similar nearest neighbors encoding the steer vector’s concept:
Local2: We measure intrinsic dimension (ID) of token embeddings. Interestingly, ID reveals that tokens with low ID form very coherent semantic clusters, while tokens with higher ID do not!

May 7, 2025 at 1:38 PM
Local2: We measure intrinsic dimension (ID) of token embeddings. Interestingly, ID reveals that tokens with low ID form very coherent semantic clusters, while tokens with higher ID do not!
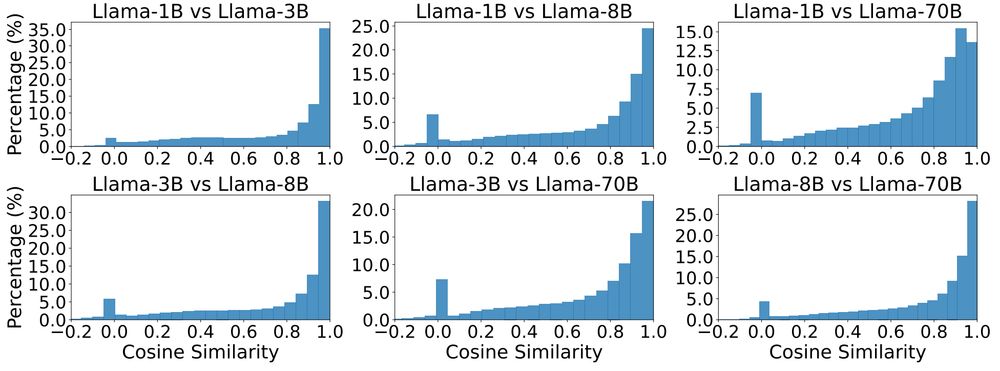
Local: we characterize two ways: first using Locally Linear Embeddings (LLE), in which we express each token embedding as the weighted sum of its k-nearest neighbors. It turns out, the LLE weights for most tokens look very similar across language models, indicating similar local geometry:
May 7, 2025 at 1:38 PM
Local: we characterize two ways: first using Locally Linear Embeddings (LLE), in which we express each token embedding as the weighted sum of its k-nearest neighbors. It turns out, the LLE weights for most tokens look very similar across language models, indicating similar local geometry:
We characterize “global” and “local” geometry in simple terms.
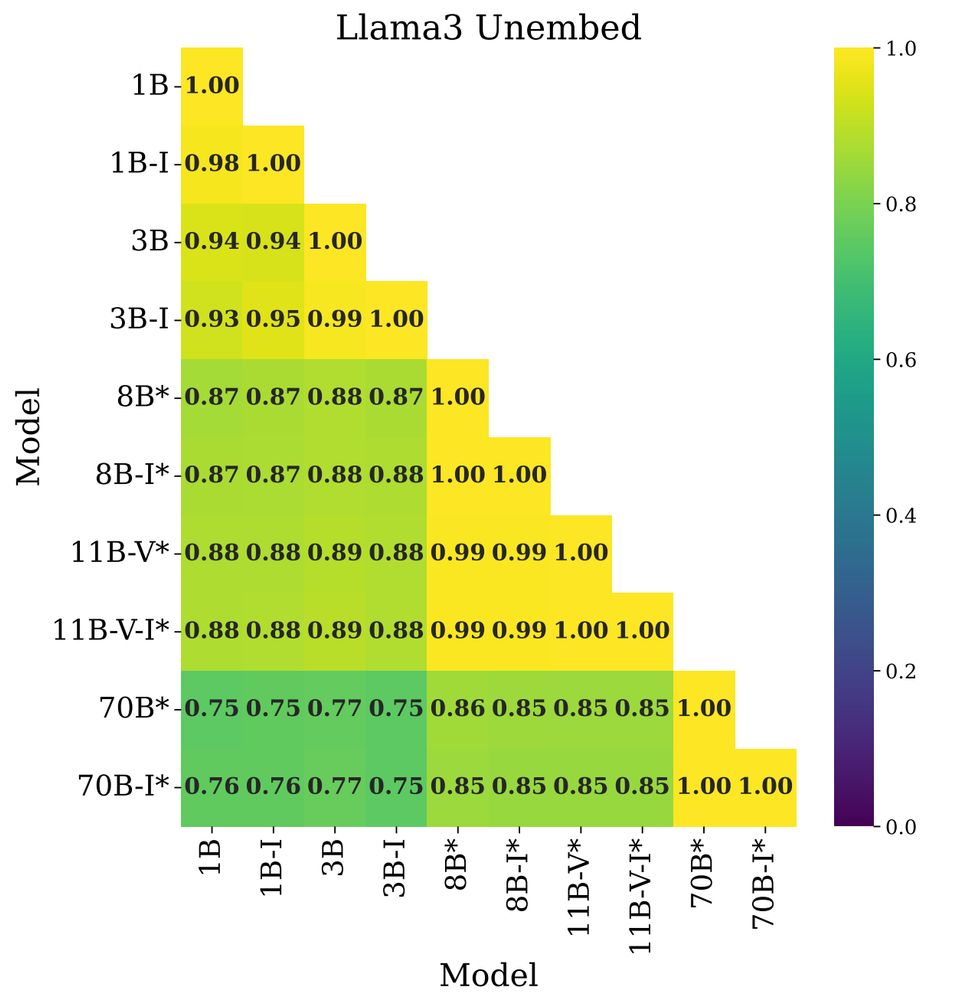
Global: how similar are the distance matrices of embeddings across LMs? We can check with Pearson correlation between distance matrices: high correlation indicates similar relative orientations of token embeddings, which is what we find
Global: how similar are the distance matrices of embeddings across LMs? We can check with Pearson correlation between distance matrices: high correlation indicates similar relative orientations of token embeddings, which is what we find
May 7, 2025 at 1:38 PM
We characterize “global” and “local” geometry in simple terms.
Global: how similar are the distance matrices of embeddings across LMs? We can check with Pearson correlation between distance matrices: high correlation indicates similar relative orientations of token embeddings, which is what we find
Global: how similar are the distance matrices of embeddings across LMs? We can check with Pearson correlation between distance matrices: high correlation indicates similar relative orientations of token embeddings, which is what we find
🚨New Preprint! Did you know that steering vectors from one LM can be transferred and re-used in another LM? We argue this is because token embeddings across LMs share many “global” and “local” geometric similarities!

May 7, 2025 at 1:38 PM
🚨New Preprint! Did you know that steering vectors from one LM can be transferred and re-used in another LM? We argue this is because token embeddings across LMs share many “global” and “local” geometric similarities!
Similarly, I find linear vectors that seem to encode whether R1 has found a solution or not. We can steer the model to think that it’s found a solution during its CoT with simple linear interventions:
ajyl.github.io/2025/02/16/s...
5/N
ajyl.github.io/2025/02/16/s...
5/N

February 20, 2025 at 7:55 PM
Similarly, I find linear vectors that seem to encode whether R1 has found a solution or not. We can steer the model to think that it’s found a solution during its CoT with simple linear interventions:
ajyl.github.io/2025/02/16/s...
5/N
ajyl.github.io/2025/02/16/s...
5/N
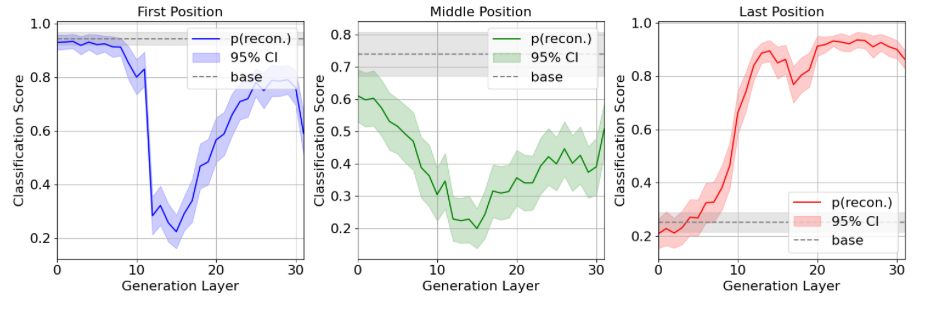
We have some preliminary findings. @wendlerc.bsky.social find simple steering vectors to either make the model continue its CoT (ie, double check its answers) or finish its thought on a GSM8K
github.com/ARBORproject...
github.com/ARBORproject...
February 20, 2025 at 7:55 PM
We have some preliminary findings. @wendlerc.bsky.social find simple steering vectors to either make the model continue its CoT (ie, double check its answers) or finish its thought on a GSM8K
github.com/ARBORproject...
github.com/ARBORproject...
Interestingly, similar observations have been made in humans: human brains also construct graphical (spatial+relational) representations given enough observations of random images from a graph! doi.org/10.7554/eLif...
8/N
8/N

January 5, 2025 at 3:49 PM
Interestingly, similar observations have been made in humans: human brains also construct graphical (spatial+relational) representations given enough observations of random images from a graph! doi.org/10.7554/eLif...
8/N
8/N
Why does this happen? We hypothesize LMs internally perform a graph spectral energy minimization process: Thus we quantify + measure energy of model activations: when energy is reduced, in-context task accuracy *jumps* to near 100%. Phase-transition of in-context reps?
7/N
7/N

January 5, 2025 at 3:49 PM
Why does this happen? We hypothesize LMs internally perform a graph spectral energy minimization process: Thus we quantify + measure energy of model activations: when energy is reduced, in-context task accuracy *jumps* to near 100%. Phase-transition of in-context reps?
7/N
7/N
In-context representations form across models and various graphs. We can intervene on the principal components to alter the model’s belief-state of the graph, and change the model’s in-context task predictions accordingly (ie, causality).
6/N
6/N

January 5, 2025 at 3:49 PM
In-context representations form across models and various graphs. We can intervene on the principal components to alter the model’s belief-state of the graph, and change the model’s in-context task predictions accordingly (ie, causality).
6/N
6/N
Instead of random words, we also try words w/ a semantic prior (ex: days of week).
We make an in-context task with a new ordering of days (Mon,Thurs,Sun,Wed…): The orig. semantic prior shows up in first principal components & in-context reps in latter ones! The two co-exist.
5/N
We make an in-context task with a new ordering of days (Mon,Thurs,Sun,Wed…): The orig. semantic prior shows up in first principal components & in-context reps in latter ones! The two co-exist.
5/N

January 5, 2025 at 3:49 PM
Instead of random words, we also try words w/ a semantic prior (ex: days of week).
We make an in-context task with a new ordering of days (Mon,Thurs,Sun,Wed…): The orig. semantic prior shows up in first principal components & in-context reps in latter ones! The two co-exist.
5/N
We make an in-context task with a new ordering of days (Mon,Thurs,Sun,Wed…): The orig. semantic prior shows up in first principal components & in-context reps in latter ones! The two co-exist.
5/N
@JoshAEngels find that words with a semantic prior (ex: days of the week) can form a ring (x.com/JoshAEngels/...)
These rings can also be formed in-context!
4/N
These rings can also be formed in-context!
4/N

January 5, 2025 at 3:49 PM
@JoshAEngels find that words with a semantic prior (ex: days of the week) can form a ring (x.com/JoshAEngels/...)
These rings can also be formed in-context!
4/N
These rings can also be formed in-context!
4/N
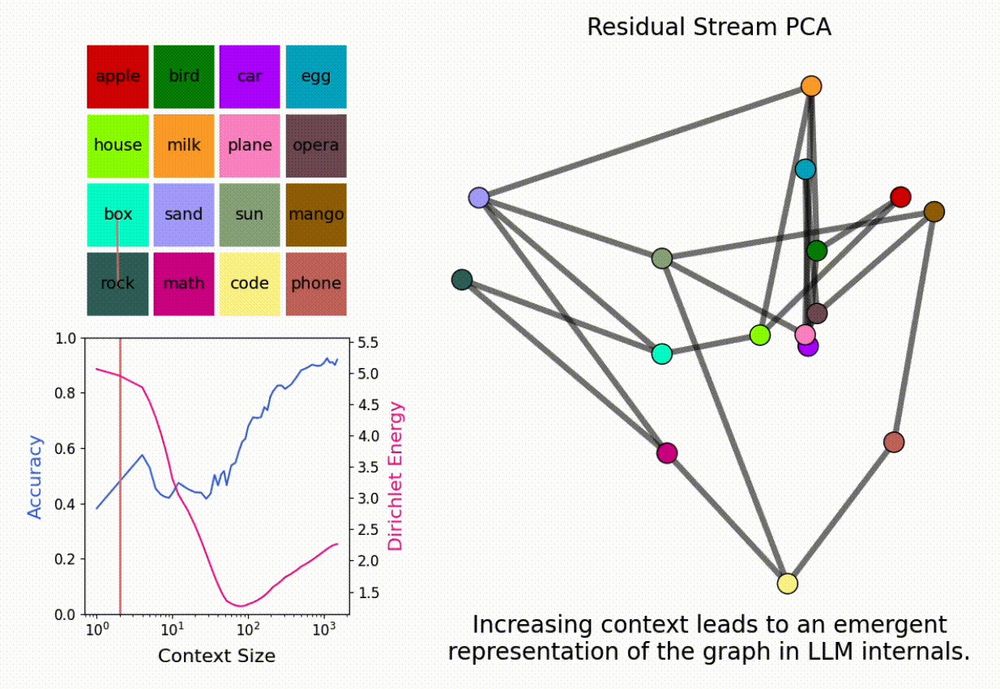
What are in-context representations?
We build a graph with random words as nodes, randomly walk the graph, and input the resulting seq to LMs. With a long enough context, LMs start adhering to the graph
When this happens, PCA of LM activations reveals the graph (task) structure
3/N
We build a graph with random words as nodes, randomly walk the graph, and input the resulting seq to LMs. With a long enough context, LMs start adhering to the graph
When this happens, PCA of LM activations reveals the graph (task) structure
3/N

January 5, 2025 at 3:49 PM
What are in-context representations?
We build a graph with random words as nodes, randomly walk the graph, and input the resulting seq to LMs. With a long enough context, LMs start adhering to the graph
When this happens, PCA of LM activations reveals the graph (task) structure
3/N
We build a graph with random words as nodes, randomly walk the graph, and input the resulting seq to LMs. With a long enough context, LMs start adhering to the graph
When this happens, PCA of LM activations reveals the graph (task) structure
3/N
Given an in-context task, and as context is scaled, LMs can form ‘in-context representations’ that reflect the task.
Team: @corefpark.bsky.social @ekdeepl.bsky.social YongyiYang MayaOkawa KentoNishi @wattenberg.bsky.social @hidenori8tanaka.bsky.social
arxiv.org/pdf/2501.00070
2/N
Team: @corefpark.bsky.social @ekdeepl.bsky.social YongyiYang MayaOkawa KentoNishi @wattenberg.bsky.social @hidenori8tanaka.bsky.social
arxiv.org/pdf/2501.00070
2/N

January 5, 2025 at 3:49 PM
Given an in-context task, and as context is scaled, LMs can form ‘in-context representations’ that reflect the task.
Team: @corefpark.bsky.social @ekdeepl.bsky.social YongyiYang MayaOkawa KentoNishi @wattenberg.bsky.social @hidenori8tanaka.bsky.social
arxiv.org/pdf/2501.00070
2/N
Team: @corefpark.bsky.social @ekdeepl.bsky.social YongyiYang MayaOkawa KentoNishi @wattenberg.bsky.social @hidenori8tanaka.bsky.social
arxiv.org/pdf/2501.00070
2/N
New paper <3
Interested in inference-time scaling? In-context Learning? Mech Interp?
LMs can solve novel in-context tasks, with sufficient examples (longer contexts). Why? Bc they dynamically form *in-context representations*!
1/N
Interested in inference-time scaling? In-context Learning? Mech Interp?
LMs can solve novel in-context tasks, with sufficient examples (longer contexts). Why? Bc they dynamically form *in-context representations*!
1/N
January 5, 2025 at 3:49 PM
New paper <3
Interested in inference-time scaling? In-context Learning? Mech Interp?
LMs can solve novel in-context tasks, with sufficient examples (longer contexts). Why? Bc they dynamically form *in-context representations*!
1/N
Interested in inference-time scaling? In-context Learning? Mech Interp?
LMs can solve novel in-context tasks, with sufficient examples (longer contexts). Why? Bc they dynamically form *in-context representations*!
1/N