



Vignesh Padmanabhan
@ai-slayer.bsky.social
🌟 Lead Data Scientist @ Codvo.ai
🔬 Expertise in:
- LLMs
- Optimization Problems
- Computer Vision
- Recommendation Systems
🔬 Expertise in:
- LLMs
- Optimization Problems
- Computer Vision
- Recommendation Systems
Reposted by Vignesh Padmanabhan

A common trend across recent research in using reinforcement learning to train reasoning models is that the clipping operation within a trust region (core to PPO, adopted by GRPO) is squashing rare tokens that are key to clever behaviors like verification or backtracking.

June 17, 2025 at 2:38 AM
A common trend across recent research in using reinforcement learning to train reasoning models is that the clipping operation within a trust region (core to PPO, adopted by GRPO) is squashing rare tokens that are key to clever behaviors like verification or backtracking.

Reposted by Vignesh Padmanabhan

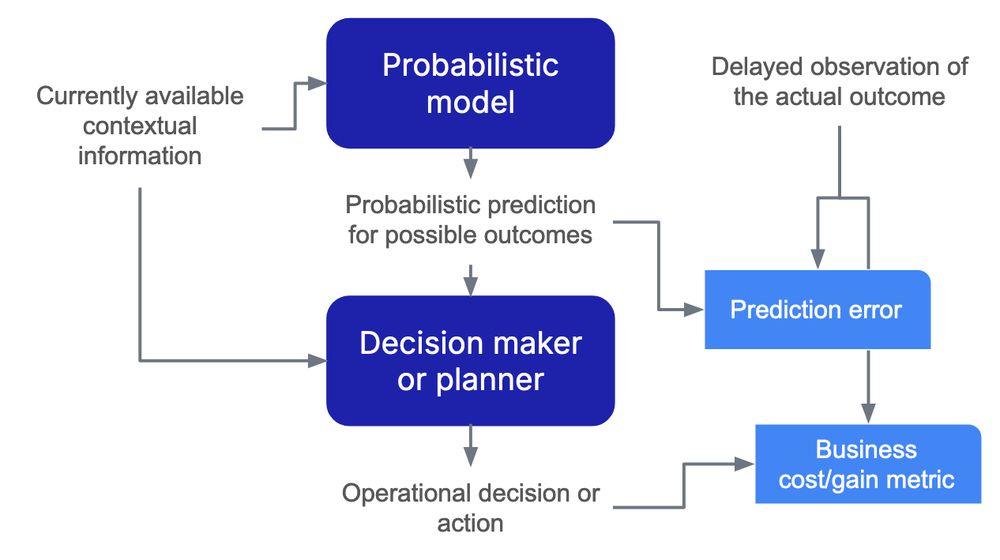
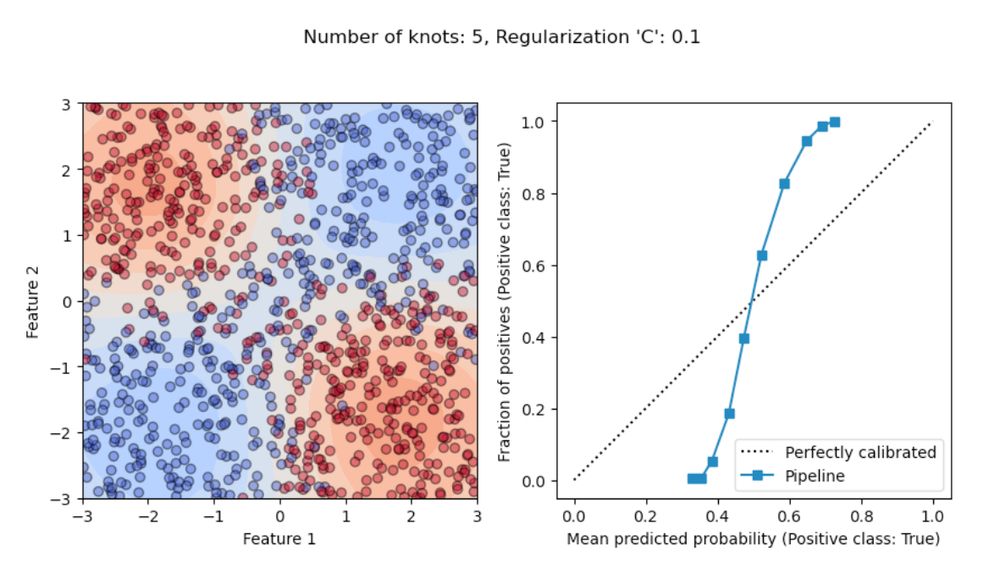
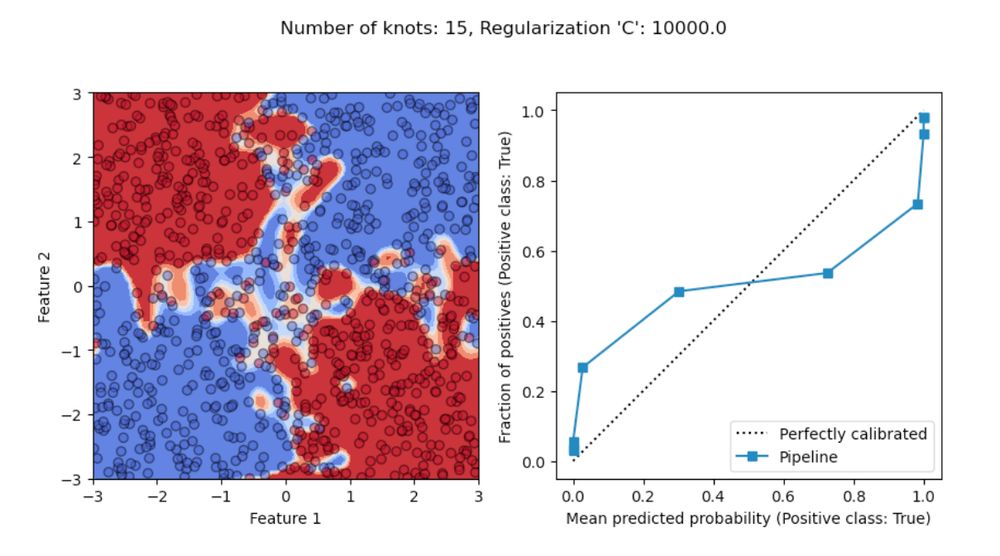
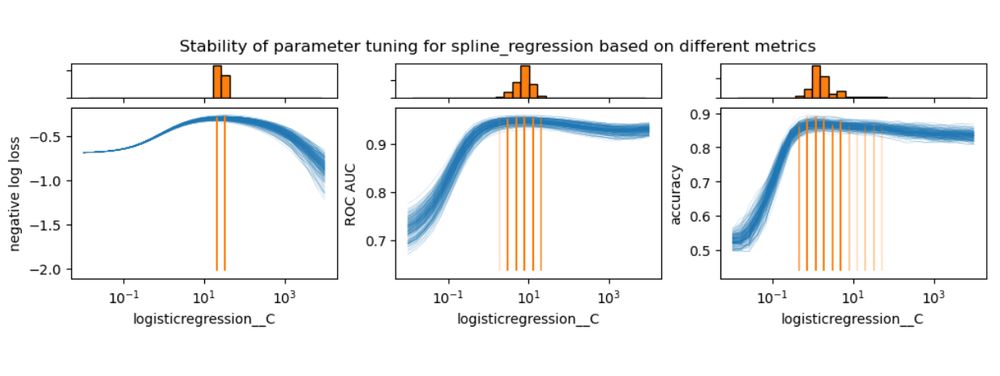
I recently shared some of my reflections on how to use probabilistic classifiers for optimal decision-making under uncertainty at @pydataparis.bsky.social 2024.
Here is the recording of the presentation:
www.youtube.com/watch?v=-gYn...
Here is the recording of the presentation:
www.youtube.com/watch?v=-gYn...
November 27, 2024 at 2:17 PM
I recently shared some of my reflections on how to use probabilistic classifiers for optimal decision-making under uncertainty at @pydataparis.bsky.social 2024.
Here is the recording of the presentation:
www.youtube.com/watch?v=-gYn...
Here is the recording of the presentation:
www.youtube.com/watch?v=-gYn...
Reposted by Vignesh Padmanabhan

Bringing structure and recommended practices to Machine Learning projects can be challenging. Even experienced data scientists struggle with it.
That's why we built skore – your companion when modeling with scikit-learn. Check it out and let us know what you think!
github.com/probabl-ai/s...
That's why we built skore – your companion when modeling with scikit-learn. Check it out and let us know what you think!
github.com/probabl-ai/s...

GitHub - probabl-ai/skore: Your scikit-learn Modeling Companion
Your scikit-learn Modeling Companion. Contribute to probabl-ai/skore development by creating an account on GitHub.
github.com
December 13, 2024 at 9:30 AM
Bringing structure and recommended practices to Machine Learning projects can be challenging. Even experienced data scientists struggle with it.
That's why we built skore – your companion when modeling with scikit-learn. Check it out and let us know what you think!
github.com/probabl-ai/s...
That's why we built skore – your companion when modeling with scikit-learn. Check it out and let us know what you think!
github.com/probabl-ai/s...
Which setup would you choose for running large language models (LLMs) locally ?
Option 1:
• Apple M4 Max
• 14-core CPU, 32-core GPU
• 36 GB unified memory
• 1 TB SSD
Option 2:
• Apple M4 Pro
• 14-core CPU, 20-core GPU
• 48 GB unified memory
• 1 TB SSD
Option 1:
• Apple M4 Max
• 14-core CPU, 32-core GPU
• 36 GB unified memory
• 1 TB SSD
Option 2:
• Apple M4 Pro
• 14-core CPU, 20-core GPU
• 48 GB unified memory
• 1 TB SSD
November 25, 2024 at 6:31 PM
Which setup would you choose for running large language models (LLMs) locally ?
Option 1:
• Apple M4 Max
• 14-core CPU, 32-core GPU
• 36 GB unified memory
• 1 TB SSD
Option 2:
• Apple M4 Pro
• 14-core CPU, 20-core GPU
• 48 GB unified memory
• 1 TB SSD
Option 1:
• Apple M4 Max
• 14-core CPU, 32-core GPU
• 36 GB unified memory
• 1 TB SSD
Option 2:
• Apple M4 Pro
• 14-core CPU, 20-core GPU
• 48 GB unified memory
• 1 TB SSD
Reposted by Vignesh Padmanabhan

Everything you always wanted to ask about entropy but didn't know whom by John Baez.
arxiv.org/abs/2409.09232
arxiv.org/abs/2409.09232

What is Entropy?
This short book is an elementary course on entropy, leading up to a calculation of the entropy of hydrogen gas at standard temperature and pressure. Topics covered include information, Shannon entropy...
arxiv.org
November 24, 2024 at 6:48 AM
Everything you always wanted to ask about entropy but didn't know whom by John Baez.
arxiv.org/abs/2409.09232
arxiv.org/abs/2409.09232
Reposted by Vignesh Padmanabhan

We're always updating the pydata & scipy project starter pack:
go.bsky.app/6HkrMcp
Hello @scikit-learn.bsky.social , @networkx.bsky.social , @scipyconf.bsky.social
go.bsky.app/6HkrMcp
Hello @scikit-learn.bsky.social , @networkx.bsky.social , @scipyconf.bsky.social
November 22, 2024 at 5:46 PM
We're always updating the pydata & scipy project starter pack:
go.bsky.app/6HkrMcp
Hello @scikit-learn.bsky.social , @networkx.bsky.social , @scipyconf.bsky.social
go.bsky.app/6HkrMcp
Hello @scikit-learn.bsky.social , @networkx.bsky.social , @scipyconf.bsky.social
Reposted by Vignesh Padmanabhan

One of my fav projects: LeanRL, a simple RL library that provides recipes for fast RL training using torch.compile and cudagraphs.
Using these, we got >6x speed-ups compared to the original CleanRL implementations.
github.com/pytorch-labs...
Using these, we got >6x speed-ups compared to the original CleanRL implementations.
github.com/pytorch-labs...

November 22, 2024 at 6:38 AM
One of my fav projects: LeanRL, a simple RL library that provides recipes for fast RL training using torch.compile and cudagraphs.
Using these, we got >6x speed-ups compared to the original CleanRL implementations.
github.com/pytorch-labs...
Using these, we got >6x speed-ups compared to the original CleanRL implementations.
github.com/pytorch-labs...
Reposted by Vignesh Padmanabhan

www.anthropic.com/research/sta...
This is an excellent attempt (blog & paper) at bringing more statistical rigor to evaluation of ML models (this is specifically focused on LLM evals).
I feel like we need to have similar clear standards for many types of predictive models in biology. 1/
This is an excellent attempt (blog & paper) at bringing more statistical rigor to evaluation of ML models (this is specifically focused on LLM evals).
I feel like we need to have similar clear standards for many types of predictive models in biology. 1/

A statistical approach to model evaluations
A research paper from Anthropic on how to apply statistics to improve language model evaluations
www.anthropic.com
November 22, 2024 at 8:29 AM
www.anthropic.com/research/sta...
This is an excellent attempt (blog & paper) at bringing more statistical rigor to evaluation of ML models (this is specifically focused on LLM evals).
I feel like we need to have similar clear standards for many types of predictive models in biology. 1/
This is an excellent attempt (blog & paper) at bringing more statistical rigor to evaluation of ML models (this is specifically focused on LLM evals).
I feel like we need to have similar clear standards for many types of predictive models in biology. 1/
Reposted by Vignesh Padmanabhan

Just put together a list of papers to highlight 4 interesting things about transformers & LLMs.
Including a discussion on why the original transformer architecture figure is wrong, and a related approach published in 1991!
https://magazine.sebastianraschka.com/p/why-the-original-transformer-figure
Including a discussion on why the original transformer architecture figure is wrong, and a related approach published in 1991!
https://magazine.sebastianraschka.com/p/why-the-original-transformer-figure

Why the Original Transformer Figure Is Wrong, and Some Other Interesting Historical Tidbits About LLMs
A few months ago, I shared the article, Understanding Large Language Models: A Cross-Section of the Most Relevant Literature To Get Up to Speed, and the positive feedback was very motivating! So, I also added a few papers here and there to keep the list fresh and relevant.
magazine.sebastianraschka.com
May 25, 2023 at 4:12 PM
Just put together a list of papers to highlight 4 interesting things about transformers & LLMs.
Including a discussion on why the original transformer architecture figure is wrong, and a related approach published in 1991!
https://magazine.sebastianraschka.com/p/why-the-original-transformer-figure
Including a discussion on why the original transformer architecture figure is wrong, and a related approach published in 1991!
https://magazine.sebastianraschka.com/p/why-the-original-transformer-figure
Reposted by Vignesh Padmanabhan
The Llama 3.2 1B and 3B models are my favorite LLMs -- small but very capable.
If you want to understand how the architectures look like under the hood, I implemented them from scratch (one of the best ways to learn): github.com/rasbt/LLMs-f...
If you want to understand how the architectures look like under the hood, I implemented them from scratch (one of the best ways to learn): github.com/rasbt/LLMs-f...

November 20, 2024 at 8:33 AM
The Llama 3.2 1B and 3B models are my favorite LLMs -- small but very capable.
If you want to understand how the architectures look like under the hood, I implemented them from scratch (one of the best ways to learn): github.com/rasbt/LLMs-f...
If you want to understand how the architectures look like under the hood, I implemented them from scratch (one of the best ways to learn): github.com/rasbt/LLMs-f...