



@aakriti1kumar.bsky.social
There’s a lot more detail in the full paper, and I would love to hear your thoughts and feedback on it!
Check out the preprint here: arxiv.org/pdf/2506.10150
Check out the preprint here: arxiv.org/pdf/2506.10150
arxiv.org
June 17, 2025 at 3:14 PM
There’s a lot more detail in the full paper, and I would love to hear your thoughts and feedback on it!
Check out the preprint here: arxiv.org/pdf/2506.10150
Check out the preprint here: arxiv.org/pdf/2506.10150
Huge thanks to my amazing collaborators: Fai Poungpeth, @diyiyang.bsky.social, Erina Farrell, @brucelambert.bsky.social, and @mattgroh.bsky.social 🙌
June 17, 2025 at 3:14 PM
Huge thanks to my amazing collaborators: Fai Poungpeth, @diyiyang.bsky.social, Erina Farrell, @brucelambert.bsky.social, and @mattgroh.bsky.social 🙌
LLMs, when benchmarked against reliable expert judgments, can be reliable tools for overseeing emotionally sensitive AI applications.
Our results show we can use LLMs-as-judge to monitor LLMs-as-companion!
Our results show we can use LLMs-as-judge to monitor LLMs-as-companion!
June 17, 2025 at 3:14 PM
LLMs, when benchmarked against reliable expert judgments, can be reliable tools for overseeing emotionally sensitive AI applications.
Our results show we can use LLMs-as-judge to monitor LLMs-as-companion!
Our results show we can use LLMs-as-judge to monitor LLMs-as-companion!
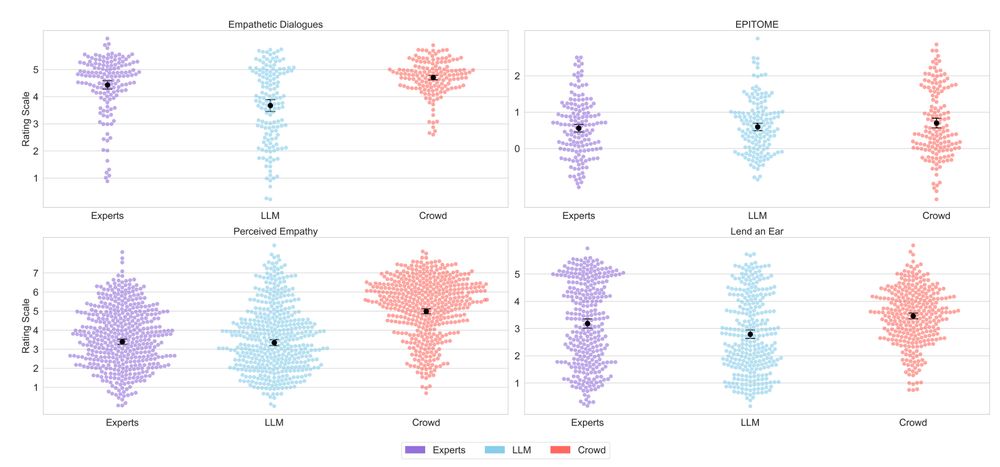
For example, in one of the conversations in our dataset, a response that an expert saw as "dismissing” the speaker’s emotions, a crowdworker interpreted as "validating" their emotions instead!
June 17, 2025 at 3:14 PM
For example, in one of the conversations in our dataset, a response that an expert saw as "dismissing” the speaker’s emotions, a crowdworker interpreted as "validating" their emotions instead!
These misjudgments from crowdworkers have huge implications for AI training and deployment❌
If we use flawed evaluations to train and monitor "empathic" AI, we risk creating systems that propagate a broken standard of what good communication looks like.
If we use flawed evaluations to train and monitor "empathic" AI, we risk creating systems that propagate a broken standard of what good communication looks like.
June 17, 2025 at 3:14 PM
These misjudgments from crowdworkers have huge implications for AI training and deployment❌
If we use flawed evaluations to train and monitor "empathic" AI, we risk creating systems that propagate a broken standard of what good communication looks like.
If we use flawed evaluations to train and monitor "empathic" AI, we risk creating systems that propagate a broken standard of what good communication looks like.
So why the gap between experts/LLMs and crowds?
Crowdworkers often
- have limited attention
- rely on heuristics like “it’s the thought that counts”
- focusing on intentions rather than actual wording
show systematic rating inflation due to social desirability bias
Crowdworkers often
- have limited attention
- rely on heuristics like “it’s the thought that counts”
- focusing on intentions rather than actual wording
show systematic rating inflation due to social desirability bias
June 17, 2025 at 3:14 PM
So why the gap between experts/LLMs and crowds?
Crowdworkers often
- have limited attention
- rely on heuristics like “it’s the thought that counts”
- focusing on intentions rather than actual wording
show systematic rating inflation due to social desirability bias
Crowdworkers often
- have limited attention
- rely on heuristics like “it’s the thought that counts”
- focusing on intentions rather than actual wording
show systematic rating inflation due to social desirability bias
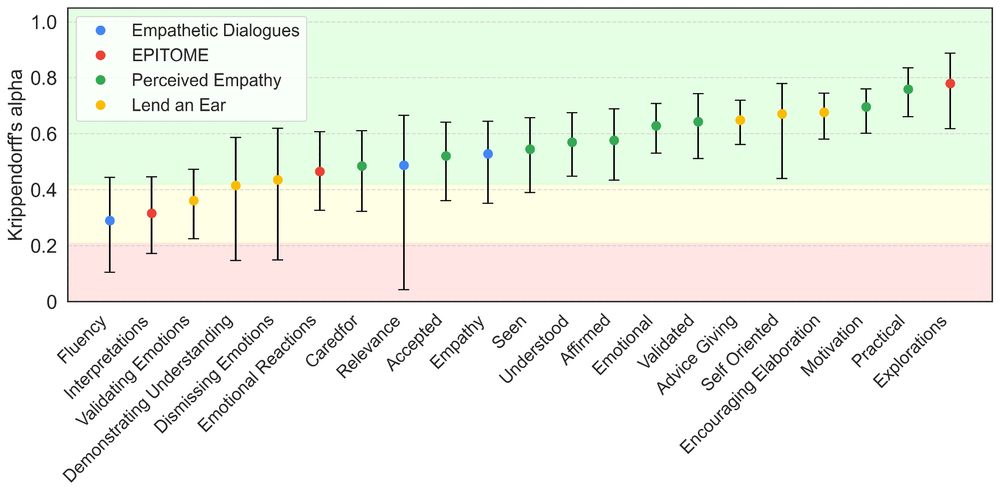
And when experts disagree, LLMs struggle to find a consistent signal too.
Here’s how expert agreement (Krippendorff's alpha) varied across empathy sub-components:
Here’s how expert agreement (Krippendorff's alpha) varied across empathy sub-components:
June 17, 2025 at 3:14 PM
And when experts disagree, LLMs struggle to find a consistent signal too.
Here’s how expert agreement (Krippendorff's alpha) varied across empathy sub-components:
Here’s how expert agreement (Krippendorff's alpha) varied across empathy sub-components:
But here’s the catch: LLMs are reliable when experts are reliable.
The reliability of expert judgments depends on the clarity of the construct. For nuanced, subjective components of empathic communication, experts often disagree.
The reliability of expert judgments depends on the clarity of the construct. For nuanced, subjective components of empathic communication, experts often disagree.
June 17, 2025 at 3:14 PM
But here’s the catch: LLMs are reliable when experts are reliable.
The reliability of expert judgments depends on the clarity of the construct. For nuanced, subjective components of empathic communication, experts often disagree.
The reliability of expert judgments depends on the clarity of the construct. For nuanced, subjective components of empathic communication, experts often disagree.
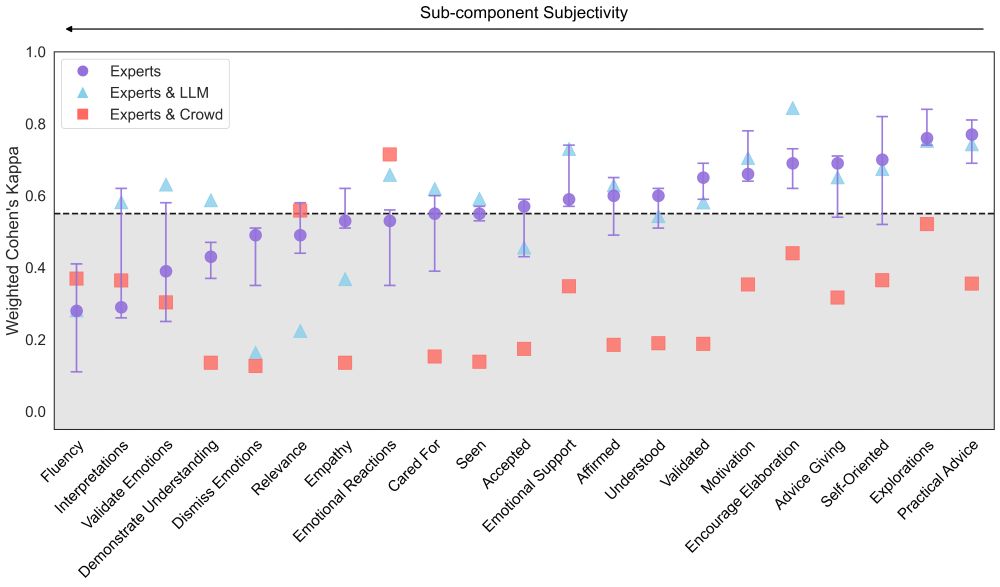
We analyzed thousands of annotations from LLMs, crowdworkers, and experts on 200 real-world conversations
And specifically looked at 21 sub-components of empathic communication from 4 evaluative frameworks
The result? LLMs consistently matched expert judgments better than crowdworkers did! 🔥
And specifically looked at 21 sub-components of empathic communication from 4 evaluative frameworks
The result? LLMs consistently matched expert judgments better than crowdworkers did! 🔥
June 17, 2025 at 3:14 PM
We analyzed thousands of annotations from LLMs, crowdworkers, and experts on 200 real-world conversations
And specifically looked at 21 sub-components of empathic communication from 4 evaluative frameworks
The result? LLMs consistently matched expert judgments better than crowdworkers did! 🔥
And specifically looked at 21 sub-components of empathic communication from 4 evaluative frameworks
The result? LLMs consistently matched expert judgments better than crowdworkers did! 🔥
Reposted

Our paper: Decision-Point Guided Safe Policy Improvement
We show that a simple approach to learn safe RL policies can outperform most offline RL methods. (+theoretical guarantees!)
How? Just allow the state-actions that have been seen enough times! 🤯
arxiv.org/abs/2410.09361
We show that a simple approach to learn safe RL policies can outperform most offline RL methods. (+theoretical guarantees!)
How? Just allow the state-actions that have been seen enough times! 🤯
arxiv.org/abs/2410.09361

Decision-Point Guided Safe Policy Improvement
Within batch reinforcement learning, safe policy improvement (SPI) seeks to ensure that the learnt policy performs at least as well as the behavior policy that generated the dataset. The core challeng...
arxiv.org
January 23, 2025 at 6:23 PM
Our paper: Decision-Point Guided Safe Policy Improvement
We show that a simple approach to learn safe RL policies can outperform most offline RL methods. (+theoretical guarantees!)
How? Just allow the state-actions that have been seen enough times! 🤯
arxiv.org/abs/2410.09361
We show that a simple approach to learn safe RL policies can outperform most offline RL methods. (+theoretical guarantees!)
How? Just allow the state-actions that have been seen enough times! 🤯
arxiv.org/abs/2410.09361