




Venkat
@venkatasg.net
Assistant Professor CS @ Ithaca College. Computational Linguist interested in pragmatics & social aspects of communication.
venkatasg.net
venkatasg.net
Reposted by Venkat

New work to appear @ TACL!
Language models (LMs) are remarkably good at generating novel well-formed sentences, leading to claims that they have mastered grammar.
Yet they often assign higher probability to ungrammatical strings than to grammatical strings.
How can both things be true? 🧵👇
Language models (LMs) are remarkably good at generating novel well-formed sentences, leading to claims that they have mastered grammar.
Yet they often assign higher probability to ungrammatical strings than to grammatical strings.
How can both things be true? 🧵👇

November 10, 2025 at 10:11 PM
New work to appear @ TACL!
Language models (LMs) are remarkably good at generating novel well-formed sentences, leading to claims that they have mastered grammar.
Yet they often assign higher probability to ungrammatical strings than to grammatical strings.
How can both things be true? 🧵👇
Language models (LMs) are remarkably good at generating novel well-formed sentences, leading to claims that they have mastered grammar.
Yet they often assign higher probability to ungrammatical strings than to grammatical strings.
How can both things be true? 🧵👇
Reposted by Venkat

Syntax that spuriously correlates with safe domains can jailbreak LLMs - e.g. below with GPT4o mini
Our paper (co w/ Vinith Suriyakumar) on syntax-domain spurious correlations will appear at #NeurIPS2025 as a ✨spotlight!
+ @marzyehghassemi.bsky.social, @byron.bsky.social, Levent Sagun
Our paper (co w/ Vinith Suriyakumar) on syntax-domain spurious correlations will appear at #NeurIPS2025 as a ✨spotlight!
+ @marzyehghassemi.bsky.social, @byron.bsky.social, Levent Sagun


October 24, 2025 at 4:23 PM
Syntax that spuriously correlates with safe domains can jailbreak LLMs - e.g. below with GPT4o mini
Our paper (co w/ Vinith Suriyakumar) on syntax-domain spurious correlations will appear at #NeurIPS2025 as a ✨spotlight!
+ @marzyehghassemi.bsky.social, @byron.bsky.social, Levent Sagun
Our paper (co w/ Vinith Suriyakumar) on syntax-domain spurious correlations will appear at #NeurIPS2025 as a ✨spotlight!
+ @marzyehghassemi.bsky.social, @byron.bsky.social, Levent Sagun
Reposted by Venkat

"Although I hate leafy vegetables, I prefer daxes to blickets." Can you tell if daxes are leafy vegetables? LM's can't seem to! 📷
We investigate if LMs capture these inferences from connectives when they cannot rely on world knowledge.
New paper w/ Daniel, Will, @jessyjli.bsky.social
We investigate if LMs capture these inferences from connectives when they cannot rely on world knowledge.
New paper w/ Daniel, Will, @jessyjli.bsky.social

October 16, 2025 at 3:27 PM
"Although I hate leafy vegetables, I prefer daxes to blickets." Can you tell if daxes are leafy vegetables? LM's can't seem to! 📷
We investigate if LMs capture these inferences from connectives when they cannot rely on world knowledge.
New paper w/ Daniel, Will, @jessyjli.bsky.social
We investigate if LMs capture these inferences from connectives when they cannot rely on world knowledge.
New paper w/ Daniel, Will, @jessyjli.bsky.social
Reposted by Venkat

UT Austin Linguistics is hiring in computational linguistics!
Asst or Assoc.
We have a thriving group sites.utexas.edu/compling/ and a long proud history in the space. (For instance, fun fact, Jeff Elman was a UT Austin Linguistics Ph.D.)
faculty.utexas.edu/career/170793
🤘
Asst or Assoc.
We have a thriving group sites.utexas.edu/compling/ and a long proud history in the space. (For instance, fun fact, Jeff Elman was a UT Austin Linguistics Ph.D.)
faculty.utexas.edu/career/170793
🤘
UT Austin Computational Linguistics Research Group – Humans processing computers processing humans processing language
sites.utexas.edu
October 7, 2025 at 8:53 PM
UT Austin Linguistics is hiring in computational linguistics!
Asst or Assoc.
We have a thriving group sites.utexas.edu/compling/ and a long proud history in the space. (For instance, fun fact, Jeff Elman was a UT Austin Linguistics Ph.D.)
faculty.utexas.edu/career/170793
🤘
Asst or Assoc.
We have a thriving group sites.utexas.edu/compling/ and a long proud history in the space. (For instance, fun fact, Jeff Elman was a UT Austin Linguistics Ph.D.)
faculty.utexas.edu/career/170793
🤘
Reposted by Venkat

Excited to present this at #COLM2025 tomorrow! (Tuesday, 11:00 AM poster session)
One of the ways that LLMs can be inconsistent is the "generator-validator gap," where LLMs deem their own answers incorrect.
🎯 We demonstrate that ranking-based discriminator training can significantly reduce this gap, and improvements on one task often generalize to others!
🧵👇
🎯 We demonstrate that ranking-based discriminator training can significantly reduce this gap, and improvements on one task often generalize to others!
🧵👇


October 6, 2025 at 8:40 PM
Excited to present this at #COLM2025 tomorrow! (Tuesday, 11:00 AM poster session)
Reposted by Venkat

I will be giving a short talk on this work at the COLM Interplay workshop on Friday (also to appear at EMNLP)!
Will be in Montreal all week and excited to chat about LM interpretability + its interaction with human cognition and ling theory.
Will be in Montreal all week and excited to chat about LM interpretability + its interaction with human cognition and ling theory.
A key hypothesis in the history of linguistics is that different constructions share underlying structure. We take advantage of recent advances in mechanistic interpretability to test this hypothesis in Language Models.
New work with @kmahowald.bsky.social and @cgpotts.bsky.social!
🧵👇!
New work with @kmahowald.bsky.social and @cgpotts.bsky.social!
🧵👇!

October 6, 2025 at 12:05 PM
I will be giving a short talk on this work at the COLM Interplay workshop on Friday (also to appear at EMNLP)!
Will be in Montreal all week and excited to chat about LM interpretability + its interaction with human cognition and ling theory.
Will be in Montreal all week and excited to chat about LM interpretability + its interaction with human cognition and ling theory.
Reposted by Venkat
I’m excited for COLM this week!
Looking forward to chatting with people about interpretability, data efficient training, cog sci and LLM consistency.
Looking forward to chatting with people about interpretability, data efficient training, cog sci and LLM consistency.
October 4, 2025 at 2:53 PM
I’m excited for COLM this week!
Looking forward to chatting with people about interpretability, data efficient training, cog sci and LLM consistency.
Looking forward to chatting with people about interpretability, data efficient training, cog sci and LLM consistency.
Reposted by Venkat
The compling group at UT Austin (sites.utexas.edu/compling/) is looking for PhD students!
Come join me, @kmahowald.bsky.social, and @jessyjli.bsky.social as we tackle interesting research questions at the intersection of ling, cogsci, and ai!
Some topics I am particularly interested in:
Come join me, @kmahowald.bsky.social, and @jessyjli.bsky.social as we tackle interesting research questions at the intersection of ling, cogsci, and ai!
Some topics I am particularly interested in:

September 30, 2025 at 4:17 PM
The compling group at UT Austin (sites.utexas.edu/compling/) is looking for PhD students!
Come join me, @kmahowald.bsky.social, and @jessyjli.bsky.social as we tackle interesting research questions at the intersection of ling, cogsci, and ai!
Some topics I am particularly interested in:
Come join me, @kmahowald.bsky.social, and @jessyjli.bsky.social as we tackle interesting research questions at the intersection of ling, cogsci, and ai!
Some topics I am particularly interested in:


I love creating this graph every five years over ACL anthology titles and abstracts. Mentions of nuance/fine-grain seem to be doubling every five years 🙃 Nuance rising has yet to level off among *CL publications.

September 20, 2025 at 11:15 PM
I love creating this graph every five years over ACL anthology titles and abstracts. Mentions of nuance/fine-grain seem to be doubling every five years 🙃 Nuance rising has yet to level off among *CL publications.
Reposted by Venkat
Accepted at #NeurIPS2025! So proud of Yulu and Dheeraj for leading this! Be on the lookout for more "nuanced yes/no" work from them in the future 👀
Does vision training change how language is represented and used in meaningful ways?🤔The answer is a nuanced yes! Comparing VLM-LM minimal pairs, we find that while the taxonomic organization of the lexicon is similar, VLMs are better at _deploying_ this knowledge. [1/9]

September 18, 2025 at 4:12 PM
Accepted at #NeurIPS2025! So proud of Yulu and Dheeraj for leading this! Be on the lookout for more "nuanced yes/no" work from them in the future 👀
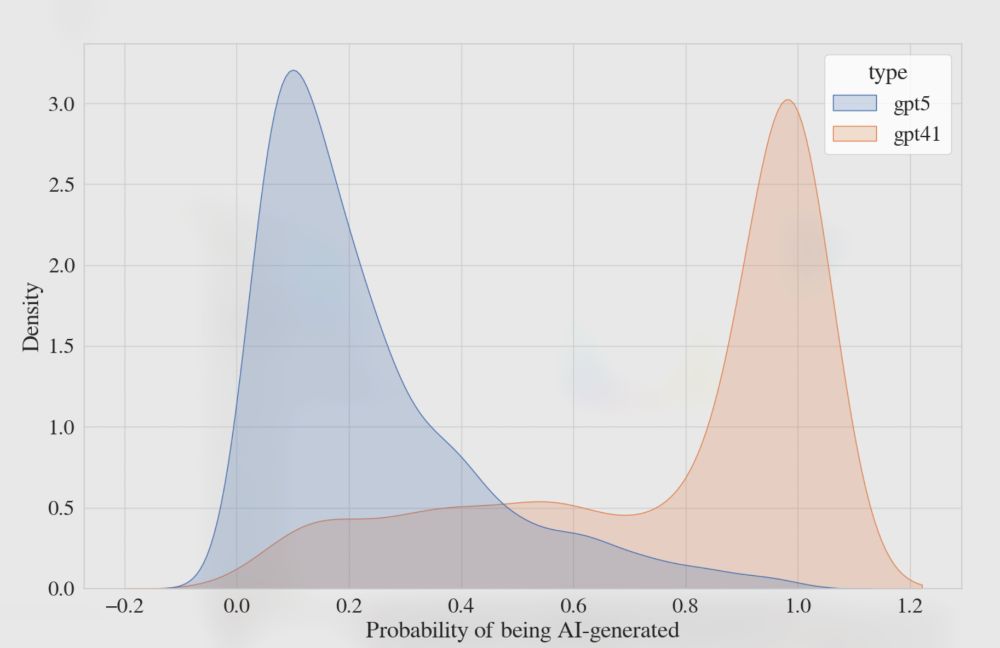
Exhibit N on how synthetic text/AI detectors just don't work reliably. Generating some (long) sentences from GPT4.1 and GPT5 with the same prompt, the top open-source model on the RAID benchmark classifies most GPT4.1 outputs as synthetic and most GPT5 as not synthetic.
September 10, 2025 at 8:05 PM
Exhibit N on how synthetic text/AI detectors just don't work reliably. Generating some (long) sentences from GPT4.1 and GPT5 with the same prompt, the top open-source model on the RAID benchmark classifies most GPT4.1 outputs as synthetic and most GPT5 as not synthetic.
Reposted by Venkat

A brilliant linguist and sociolinguist, RIP
Gift article from NYT www.nytimes.com/2025/08/15/u...
Gift article from NYT www.nytimes.com/2025/08/15/u...

Robin Lakoff, Expert on Language and Gender, Is Dead at 82
www.nytimes.com
August 17, 2025 at 12:23 PM
A brilliant linguist and sociolinguist, RIP
Gift article from NYT www.nytimes.com/2025/08/15/u...
Gift article from NYT www.nytimes.com/2025/08/15/u...
Reposted by Venkat

The Echoes in AI paper showed quite the opposite with also a story continuation setup.
Additionally, we present evidence that both *syntactic* and *discourse* diversity measures show strong homogenization that lexical and cosine used in this paper do not capture.
Additionally, we present evidence that both *syntactic* and *discourse* diversity measures show strong homogenization that lexical and cosine used in this paper do not capture.



August 12, 2025 at 9:01 PM
The Echoes in AI paper showed quite the opposite with also a story continuation setup.
Additionally, we present evidence that both *syntactic* and *discourse* diversity measures show strong homogenization that lexical and cosine used in this paper do not capture.
Additionally, we present evidence that both *syntactic* and *discourse* diversity measures show strong homogenization that lexical and cosine used in this paper do not capture.
Reposted by Venkat

ACL shortpaper appreciation thread because shortpapers are the best papers. What's the best <=5 pager? I'm nominating an oldie but a goodie

Stolen Probability: A Structural Weakness of Neural Language Models
Neural Network Language Models (NNLMs) generate probability distributions by applying a softmax function to a distance metric formed by taking the dot product of a prediction vector with all word vect...
arxiv.org
August 8, 2025 at 6:49 PM
ACL shortpaper appreciation thread because shortpapers are the best papers. What's the best <=5 pager? I'm nominating an oldie but a goodie
Reposted by Venkat

Happy to share the published version of "Art, Understanding, and Mystery"! I often hear some version of the thought that it's bad to understand artworks; this paper attempts to make that claim precise and show one way to defend artistic understanding! journals.publishing.umich.edu/ergo/article...
Art, Understanding, and Mystery
Apparent orthodoxy holds that artistic understanding is finally valuable. Artistic understanding—grasping, as such, the features of an artwork that make it aesthetically or artistically good or bad—is...
journals.publishing.umich.edu
August 6, 2025 at 9:12 PM
Happy to share the published version of "Art, Understanding, and Mystery"! I often hear some version of the thought that it's bad to understand artworks; this paper attempts to make that claim precise and show one way to defend artistic understanding! journals.publishing.umich.edu/ergo/article...
Decided to finally give programming 'agents'/vibe coding a whirl with something low-stakes/low-risk🤞🏾. Typeproof (built almost entirely with Gemini CLI) lets you view Jonathan Hoefler's (non-pangram) typeface proofs for any Google web font...(1/3) venkatasg.net/typeproof/
Typeface Proof
venkatasg.net
July 30, 2025 at 11:08 AM
Decided to finally give programming 'agents'/vibe coding a whirl with something low-stakes/low-risk🤞🏾. Typeproof (built almost entirely with Gemini CLI) lets you view Jonathan Hoefler's (non-pangram) typeface proofs for any Google web font...(1/3) venkatasg.net/typeproof/
Reposted by Venkat
🎉 New Benchmark Alert: KRISTEVA – Close‑Reading for LLMs📚
I’m excited to announce a new paper accepted to ACL 2025, in collaboration with Patrick Sui, Philippe Laban, and others!
I’m excited to announce a new paper accepted to ACL 2025, in collaboration with Patrick Sui, Philippe Laban, and others!

July 27, 2025 at 7:19 PM
🎉 New Benchmark Alert: KRISTEVA – Close‑Reading for LLMs📚
I’m excited to announce a new paper accepted to ACL 2025, in collaboration with Patrick Sui, Philippe Laban, and others!
I’m excited to announce a new paper accepted to ACL 2025, in collaboration with Patrick Sui, Philippe Laban, and others!
Reposted by Venkat

🇦🇹I'll be at #ACL2025! Recently I've been thinking about:
✨linguistically + cognitively-motivated evals (as always!)
✨understanding multilingualism + representation learning (new!)
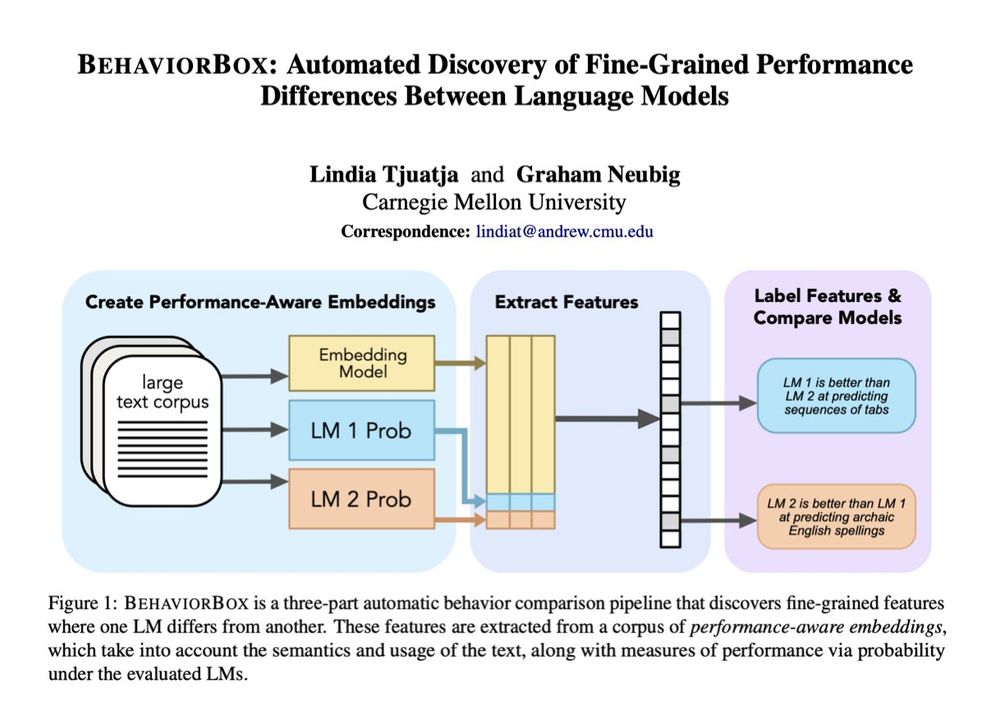
I'll also be presenting a poster for BehaviorBox on Wed @ Poster Session 4 (Hall 4/5, 10-11:30)!
✨linguistically + cognitively-motivated evals (as always!)
✨understanding multilingualism + representation learning (new!)
I'll also be presenting a poster for BehaviorBox on Wed @ Poster Session 4 (Hall 4/5, 10-11:30)!
When it comes to text prediction, where does one LM outperform another? If you've ever worked on LM evals, you know this question is a lot more complex than it seems. In our new #acl2025 paper, we developed a method to find fine-grained differences between LMs:
🧵1/9
🧵1/9
July 25, 2025 at 6:06 PM
🇦🇹I'll be at #ACL2025! Recently I've been thinking about:
✨linguistically + cognitively-motivated evals (as always!)
✨understanding multilingualism + representation learning (new!)
I'll also be presenting a poster for BehaviorBox on Wed @ Poster Session 4 (Hall 4/5, 10-11:30)!
✨linguistically + cognitively-motivated evals (as always!)
✨understanding multilingualism + representation learning (new!)
I'll also be presenting a poster for BehaviorBox on Wed @ Poster Session 4 (Hall 4/5, 10-11:30)!
@simonwillison.net I think you might be the best person to answer this question - but does gemini CLI (free tier) save the output of the chat session somewhere as a log file? Or is it possible to configure that?
July 25, 2025 at 7:22 AM
@simonwillison.net I think you might be the best person to answer this question - but does gemini CLI (free tier) save the output of the chat session somewhere as a log file? Or is it possible to configure that?
Reposted by Venkat

Does vision training change how language is represented and used in meaningful ways?🤔The answer is a nuanced yes! Comparing VLM-LM minimal pairs, we find that while the taxonomic organization of the lexicon is similar, VLMs are better at _deploying_ this knowledge. [1/9]
July 22, 2025 at 4:46 AM
Does vision training change how language is represented and used in meaningful ways?🤔The answer is a nuanced yes! Comparing VLM-LM minimal pairs, we find that while the taxonomic organization of the lexicon is similar, VLMs are better at _deploying_ this knowledge. [1/9]
Have there been any re-analysis of the 'Is Google Making Us Stupid' article from 2008 in the news? I'm not saying LLMs are no different from Google, but if we're asking the same question again we need to revisit the old debate and reflect.
www.theatlantic.com/magazine/arc...
www.theatlantic.com/magazine/arc...

Is Google Making Us Stupid?
What the Internet is doing to our brains
www.theatlantic.com
July 15, 2025 at 10:44 AM
Have there been any re-analysis of the 'Is Google Making Us Stupid' article from 2008 in the news? I'm not saying LLMs are no different from Google, but if we're asking the same question again we need to revisit the old debate and reflect.
www.theatlantic.com/magazine/arc...
www.theatlantic.com/magazine/arc...
Reposted by Venkat

🦙 how well do LLMs encode discourse knowledge? does that generalize across languages?
🛎️ in our #ACL2025 paper, we uncover fascinating trends about multilingual discourse representations!
joint work w/ @florian-eichin.com @barbaraplank.bsky.social @mhedderich.bsky.social
📄 arxiv.org/abs/2503.10515
🛎️ in our #ACL2025 paper, we uncover fascinating trends about multilingual discourse representations!
joint work w/ @florian-eichin.com @barbaraplank.bsky.social @mhedderich.bsky.social
📄 arxiv.org/abs/2503.10515

July 10, 2025 at 12:38 PM
🦙 how well do LLMs encode discourse knowledge? does that generalize across languages?
🛎️ in our #ACL2025 paper, we uncover fascinating trends about multilingual discourse representations!
joint work w/ @florian-eichin.com @barbaraplank.bsky.social @mhedderich.bsky.social
📄 arxiv.org/abs/2503.10515
🛎️ in our #ACL2025 paper, we uncover fascinating trends about multilingual discourse representations!
joint work w/ @florian-eichin.com @barbaraplank.bsky.social @mhedderich.bsky.social
📄 arxiv.org/abs/2503.10515
Reposted by Venkat

I'll be at #ICML to present SPRI next week! Come by our poster on Tuesday, July 15, 4:30pm, and let’s catch up on LLM alignment! 😃
🚀TL;DR: We introduce Situated-PRInciples (SPRI), a framework that automatically generates input-specific principles to align responses — with minimal human effort.
🧵
🚀TL;DR: We introduce Situated-PRInciples (SPRI), a framework that automatically generates input-specific principles to align responses — with minimal human effort.
🧵

July 8, 2025 at 3:05 PM
I'll be at #ICML to present SPRI next week! Come by our poster on Tuesday, July 15, 4:30pm, and let’s catch up on LLM alignment! 😃
🚀TL;DR: We introduce Situated-PRInciples (SPRI), a framework that automatically generates input-specific principles to align responses — with minimal human effort.
🧵
🚀TL;DR: We introduce Situated-PRInciples (SPRI), a framework that automatically generates input-specific principles to align responses — with minimal human effort.
🧵
Reposted by Venkat

How do language models track mental states of each character in a story, often referred to as Theory of Mind?
We reverse-engineered how LLaMA-3-70B-Instruct handles a belief-tracking task and found something surprising: it uses mechanisms strikingly similar to pointer variables in C programming!
We reverse-engineered how LLaMA-3-70B-Instruct handles a belief-tracking task and found something surprising: it uses mechanisms strikingly similar to pointer variables in C programming!

June 24, 2025 at 5:13 PM
How do language models track mental states of each character in a story, often referred to as Theory of Mind?
We reverse-engineered how LLaMA-3-70B-Instruct handles a belief-tracking task and found something surprising: it uses mechanisms strikingly similar to pointer variables in C programming!
We reverse-engineered how LLaMA-3-70B-Instruct handles a belief-tracking task and found something surprising: it uses mechanisms strikingly similar to pointer variables in C programming!