




Stefano Palminteri
@stepalminteri.bsky.social
Computational cognitive scientist interested in learning and decision-making in human and machiches
Research director of the Human Reinforcement Learning team
Ecole Normale Supérieure (ENS)
Institut National de la Santé et Recherche Médicale (INSERM)
Research director of the Human Reinforcement Learning team
Ecole Normale Supérieure (ENS)
Institut National de la Santé et Recherche Médicale (INSERM)
Pinned


🚨Friends, we’re happy to share that our book is available for pre-order! 🎉
We aimed to cover all the foundations of the topic in an accessible manner for a large audience.
It could help set up a bachelor-level curriculum on the topic.
Pre-orders are very key for the fate of books: shorturl.at/Dxbif
We aimed to cover all the foundations of the topic in an accessible manner for a large audience.
It could help set up a bachelor-level curriculum on the topic.
Pre-orders are very key for the fate of books: shorturl.at/Dxbif
Reposted by Stefano Palminteri
🚨Friends, we’re happy to share that our book is available for pre-order! 🎉
We aimed to cover all the foundations of the topic in an accessible manner for a large audience.
It could help set up a bachelor-level curriculum on the topic.
Pre-orders are very key for the fate of books: shorturl.at/Dxbif
We aimed to cover all the foundations of the topic in an accessible manner for a large audience.
It could help set up a bachelor-level curriculum on the topic.
Pre-orders are very key for the fate of books: shorturl.at/Dxbif
November 26, 2025 at 11:38 AM
🚨Friends, we’re happy to share that our book is available for pre-order! 🎉
We aimed to cover all the foundations of the topic in an accessible manner for a large audience.
It could help set up a bachelor-level curriculum on the topic.
Pre-orders are very key for the fate of books: shorturl.at/Dxbif
We aimed to cover all the foundations of the topic in an accessible manner for a large audience.
It could help set up a bachelor-level curriculum on the topic.
Pre-orders are very key for the fate of books: shorturl.at/Dxbif
Wow — thanks to this amazing community (you! 🥰 ), our book is now #1 among Amazon’s “Hot New Releases” in Medical Cognitive Psychology! 🙏🤩
Pre-order here: shorturl.at/Dxbif
Pre-order here: shorturl.at/Dxbif

November 27, 2025 at 9:36 AM
Wow — thanks to this amazing community (you! 🥰 ), our book is now #1 among Amazon’s “Hot New Releases” in Medical Cognitive Psychology! 🙏🤩
Pre-order here: shorturl.at/Dxbif
Pre-order here: shorturl.at/Dxbif
🚨Friends, we’re happy to share that our book is available for pre-order! 🎉
We aimed to cover all the foundations of the topic in an accessible manner for a large audience.
It could help set up a bachelor-level curriculum on the topic.
Pre-orders are very key for the fate of books: shorturl.at/Dxbif
We aimed to cover all the foundations of the topic in an accessible manner for a large audience.
It could help set up a bachelor-level curriculum on the topic.
Pre-orders are very key for the fate of books: shorturl.at/Dxbif
November 26, 2025 at 11:38 AM
🚨Friends, we’re happy to share that our book is available for pre-order! 🎉
We aimed to cover all the foundations of the topic in an accessible manner for a large audience.
It could help set up a bachelor-level curriculum on the topic.
Pre-orders are very key for the fate of books: shorturl.at/Dxbif
We aimed to cover all the foundations of the topic in an accessible manner for a large audience.
It could help set up a bachelor-level curriculum on the topic.
Pre-orders are very key for the fate of books: shorturl.at/Dxbif
Reposted by Stefano Palminteri
Our latest preprint where we show (among other things!) that the main effect of complete feedback information is increase risk (not performance) in experience-based show. We also show that the description experience gap is not due to sampling issue
osf.io/preprints/ps...
osf.io/preprints/ps...
November 18, 2025 at 8:41 AM
Our latest preprint where we show (among other things!) that the main effect of complete feedback information is increase risk (not performance) in experience-based show. We also show that the description experience gap is not due to sampling issue
osf.io/preprints/ps...
osf.io/preprints/ps...
Reposted by Stefano Palminteri
"Adaptive biases in the wild: Advancing our understanding of the nature of biases"
The introduction (by Jochen Reb, Natalia Karelaia & Tomás Lejarraga )to the "Mind and Society" special issue on "adaptive biases" I had the pleasure to contribute to
link.springer.com/article/10.1...
The introduction (by Jochen Reb, Natalia Karelaia & Tomás Lejarraga )to the "Mind and Society" special issue on "adaptive biases" I had the pleasure to contribute to
link.springer.com/article/10.1...

Adaptive biases in the wild: Advancing our understanding of the nature of biases - Mind & Society
Bias is most often seen as a flaw: people are said to “suffer” from biases and need to be “debiased.” Yet a bias, defined simply as a systematic deviation from a norm or standard, can in principle hav...
link.springer.com
November 18, 2025 at 8:44 AM
"Adaptive biases in the wild: Advancing our understanding of the nature of biases"
The introduction (by Jochen Reb, Natalia Karelaia & Tomás Lejarraga )to the "Mind and Society" special issue on "adaptive biases" I had the pleasure to contribute to
link.springer.com/article/10.1...
The introduction (by Jochen Reb, Natalia Karelaia & Tomás Lejarraga )to the "Mind and Society" special issue on "adaptive biases" I had the pleasure to contribute to
link.springer.com/article/10.1...
"Adaptive biases in the wild: Advancing our understanding of the nature of biases"
The introduction (by Jochen Reb, Natalia Karelaia & Tomás Lejarraga )to the "Mind and Society" special issue on "adaptive biases" I had the pleasure to contribute to
link.springer.com/article/10.1...
The introduction (by Jochen Reb, Natalia Karelaia & Tomás Lejarraga )to the "Mind and Society" special issue on "adaptive biases" I had the pleasure to contribute to
link.springer.com/article/10.1...
Adaptive biases in the wild: Advancing our understanding of the nature of biases - Mind & Society
Bias is most often seen as a flaw: people are said to “suffer” from biases and need to be “debiased.” Yet a bias, defined simply as a systematic deviation from a norm or standard, can in principle hav...
link.springer.com
November 18, 2025 at 8:44 AM
"Adaptive biases in the wild: Advancing our understanding of the nature of biases"
The introduction (by Jochen Reb, Natalia Karelaia & Tomás Lejarraga )to the "Mind and Society" special issue on "adaptive biases" I had the pleasure to contribute to
link.springer.com/article/10.1...
The introduction (by Jochen Reb, Natalia Karelaia & Tomás Lejarraga )to the "Mind and Society" special issue on "adaptive biases" I had the pleasure to contribute to
link.springer.com/article/10.1...
Our latest preprint where we show (among other things!) that the main effect of complete feedback information is increase risk (not performance) in experience-based show. We also show that the description experience gap is not due to sampling issue
osf.io/preprints/ps...
osf.io/preprints/ps...
November 18, 2025 at 8:41 AM
Our latest preprint where we show (among other things!) that the main effect of complete feedback information is increase risk (not performance) in experience-based show. We also show that the description experience gap is not due to sampling issue
osf.io/preprints/ps...
osf.io/preprints/ps...
The winner’s curse — Behavioral economics anomalies, then and now.
The presentation of Richard Thaler's (Chicago Booth) latest book, followed by a roundtable discussion, organized by the "An integrated approach of economic decisions" project.
www.parisschoolofeconomics.eu/en/events/th...
The presentation of Richard Thaler's (Chicago Booth) latest book, followed by a roundtable discussion, organized by the "An integrated approach of economic decisions" project.
www.parisschoolofeconomics.eu/en/events/th...
www.parisschoolofeconomics.eu
November 13, 2025 at 8:13 PM
The winner’s curse — Behavioral economics anomalies, then and now.
The presentation of Richard Thaler's (Chicago Booth) latest book, followed by a roundtable discussion, organized by the "An integrated approach of economic decisions" project.
www.parisschoolofeconomics.eu/en/events/th...
The presentation of Richard Thaler's (Chicago Booth) latest book, followed by a roundtable discussion, organized by the "An integrated approach of economic decisions" project.
www.parisschoolofeconomics.eu/en/events/th...
Also found in the old sci-fi stash recently purchased in Bologna
The plot’s crux is an illustration of the alignment problem (an all-powerful AI with wildly misaligned goals). Basically, the paperclip maximiser has gone rogue.
(but do not expect great writing and depth of reflection)
The plot’s crux is an illustration of the alignment problem (an all-powerful AI with wildly misaligned goals). Basically, the paperclip maximiser has gone rogue.
(but do not expect great writing and depth of reflection)


November 10, 2025 at 8:25 AM
Also found in the old sci-fi stash recently purchased in Bologna
The plot’s crux is an illustration of the alignment problem (an all-powerful AI with wildly misaligned goals). Basically, the paperclip maximiser has gone rogue.
(but do not expect great writing and depth of reflection)
The plot’s crux is an illustration of the alignment problem (an all-powerful AI with wildly misaligned goals). Basically, the paperclip maximiser has gone rogue.
(but do not expect great writing and depth of reflection)
Reposted by Stefano Palminteri

🚨 New preprint 🚨
Are reinforcement learning models complete accounts of decisions from experience if they ignore explicit memory?
In this new preprint, we show that people indeed form robust explicit memory representations that flexibly guide later decisions.
🔗 Preprint: doi.org/10.1101/2025...
Are reinforcement learning models complete accounts of decisions from experience if they ignore explicit memory?
In this new preprint, we show that people indeed form robust explicit memory representations that flexibly guide later decisions.
🔗 Preprint: doi.org/10.1101/2025...

October 29, 2025 at 8:24 AM
🚨 New preprint 🚨
Are reinforcement learning models complete accounts of decisions from experience if they ignore explicit memory?
In this new preprint, we show that people indeed form robust explicit memory representations that flexibly guide later decisions.
🔗 Preprint: doi.org/10.1101/2025...
Are reinforcement learning models complete accounts of decisions from experience if they ignore explicit memory?
In this new preprint, we show that people indeed form robust explicit memory representations that flexibly guide later decisions.
🔗 Preprint: doi.org/10.1101/2025...
Reposted by Stefano Palminteri
🇪🇺 I am a bit late for this, but is important:
R.I.P. Sofia Corradi (1934 – 2025), the beautiful mind behind the ERASMUS project, one of the most successful and beloved EU programme.
It has changed the life (and mind) of ~15 million Europeans (including mine).
en.wikipedia.org/wiki/Sofia_C...
R.I.P. Sofia Corradi (1934 – 2025), the beautiful mind behind the ERASMUS project, one of the most successful and beloved EU programme.
It has changed the life (and mind) of ~15 million Europeans (including mine).
en.wikipedia.org/wiki/Sofia_C...

October 27, 2025 at 8:17 PM
🇪🇺 I am a bit late for this, but is important:
R.I.P. Sofia Corradi (1934 – 2025), the beautiful mind behind the ERASMUS project, one of the most successful and beloved EU programme.
It has changed the life (and mind) of ~15 million Europeans (including mine).
en.wikipedia.org/wiki/Sofia_C...
R.I.P. Sofia Corradi (1934 – 2025), the beautiful mind behind the ERASMUS project, one of the most successful and beloved EU programme.
It has changed the life (and mind) of ~15 million Europeans (including mine).
en.wikipedia.org/wiki/Sofia_C...
🇪🇺 I am a bit late for this, but is important:
R.I.P. Sofia Corradi (1934 – 2025), the beautiful mind behind the ERASMUS project, one of the most successful and beloved EU programme.
It has changed the life (and mind) of ~15 million Europeans (including mine).
en.wikipedia.org/wiki/Sofia_C...
R.I.P. Sofia Corradi (1934 – 2025), the beautiful mind behind the ERASMUS project, one of the most successful and beloved EU programme.
It has changed the life (and mind) of ~15 million Europeans (including mine).
en.wikipedia.org/wiki/Sofia_C...
October 27, 2025 at 8:17 PM
🇪🇺 I am a bit late for this, but is important:
R.I.P. Sofia Corradi (1934 – 2025), the beautiful mind behind the ERASMUS project, one of the most successful and beloved EU programme.
It has changed the life (and mind) of ~15 million Europeans (including mine).
en.wikipedia.org/wiki/Sofia_C...
R.I.P. Sofia Corradi (1934 – 2025), the beautiful mind behind the ERASMUS project, one of the most successful and beloved EU programme.
It has changed the life (and mind) of ~15 million Europeans (including mine).
en.wikipedia.org/wiki/Sofia_C...
Just read this old-school sci-fi gem I found in a vintage bookstore in Bologna, where a Practical Philosopher Corps is deployed across the galaxy to assess sentience and cognition in alien species.
I guess the dream job for @birchlse.bsky.social @petergs.bsky.social
I guess the dream job for @birchlse.bsky.social @petergs.bsky.social


October 26, 2025 at 4:22 PM
Just read this old-school sci-fi gem I found in a vintage bookstore in Bologna, where a Practical Philosopher Corps is deployed across the galaxy to assess sentience and cognition in alien species.
I guess the dream job for @birchlse.bsky.social @petergs.bsky.social
I guess the dream job for @birchlse.bsky.social @petergs.bsky.social
At a time when prominent thinkers like @anilseth.bsky.social Seth and Ned Block advocate a "strategic withdrawal" toward biologism in considering consciousness beyond the human case, our contrarian proposal is a methodological behaviourist computationalism.
www.linkedin.com/posts/stefan...
www.linkedin.com/posts/stefan...

October 26, 2025 at 1:22 PM
At a time when prominent thinkers like @anilseth.bsky.social Seth and Ned Block advocate a "strategic withdrawal" toward biologism in considering consciousness beyond the human case, our contrarian proposal is a methodological behaviourist computationalism.
www.linkedin.com/posts/stefan...
www.linkedin.com/posts/stefan...
Reposted by Stefano Palminteri
🚨 New publication: How to improve conceptual clarity in psychological science?
Thrilled to see this article with @ruimata.bsky.social out. We discuss how LLMs can be leveraged to map, clarify, and generate psychological measures and constructs.
Open access article: doi.org/10.1177/0963...
Thrilled to see this article with @ruimata.bsky.social out. We discuss how LLMs can be leveraged to map, clarify, and generate psychological measures and constructs.
Open access article: doi.org/10.1177/0963...

October 23, 2025 at 7:27 AM
🚨 New publication: How to improve conceptual clarity in psychological science?
Thrilled to see this article with @ruimata.bsky.social out. We discuss how LLMs can be leveraged to map, clarify, and generate psychological measures and constructs.
Open access article: doi.org/10.1177/0963...
Thrilled to see this article with @ruimata.bsky.social out. We discuss how LLMs can be leveraged to map, clarify, and generate psychological measures and constructs.
Open access article: doi.org/10.1177/0963...
Reposted by Stefano Palminteri
Very thought-provoking post by @prakhargodara.bsky.social. Is confirmation bias/positivity bias a statistical "ghost" of model specification? Specifically not including temporally decaying learning rates? The evidence suggests this is not the case and here is why (1/n)

Is confirmation bias a real cognitive flaw, or a statistical ghost created by our models? My new PNAS paper shows a startling result: fitting Q-learning models to behavior in bandit tasks detect a bias, even from the behavior of a perfectly rational Bayesian learner.
October 19, 2025 at 8:22 AM
Very thought-provoking post by @prakhargodara.bsky.social. Is confirmation bias/positivity bias a statistical "ghost" of model specification? Specifically not including temporally decaying learning rates? The evidence suggests this is not the case and here is why (1/n)
Very thought-provoking post by @prakhargodara.bsky.social. Is confirmation bias/positivity bias a statistical "ghost" of model specification? Specifically not including temporally decaying learning rates? The evidence suggests this is not the case and here is why (1/n)
Is confirmation bias a real cognitive flaw, or a statistical ghost created by our models? My new PNAS paper shows a startling result: fitting Q-learning models to behavior in bandit tasks detect a bias, even from the behavior of a perfectly rational Bayesian learner.
October 19, 2025 at 8:22 AM
Very thought-provoking post by @prakhargodara.bsky.social. Is confirmation bias/positivity bias a statistical "ghost" of model specification? Specifically not including temporally decaying learning rates? The evidence suggests this is not the case and here is why (1/n)
The associated online tool, however definitely nerdy, is addictive. Many kudos to @dirkwulff.bsky.social and co for setting this up and opening it to the community!
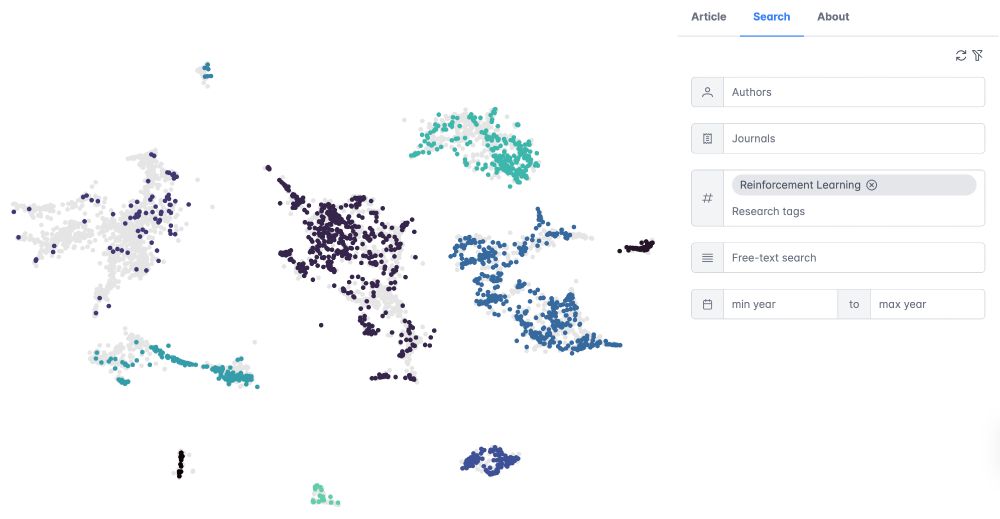
🚨 New preprint and online tool 🚨
Thrilled to share new work, mapping the 🗺️ landscape of behavioral reinforcement learning using an 🤖 LLM-powered bibliometric approach.
We built an online tool so you can explore the landscape yourself.
Online tool: mpib.berlin/vFVqU
Preprint: osf.io/6c2va_v1
Thrilled to share new work, mapping the 🗺️ landscape of behavioral reinforcement learning using an 🤖 LLM-powered bibliometric approach.
We built an online tool so you can explore the landscape yourself.
Online tool: mpib.berlin/vFVqU
Preprint: osf.io/6c2va_v1
October 19, 2025 at 7:50 AM
The associated online tool, however definitely nerdy, is addictive. Many kudos to @dirkwulff.bsky.social and co for setting this up and opening it to the community!
It was a real pleasure to be involved in the meta-scientific collaboration about the (historical, semantic and to some extent sociological) structure of the behavioral reinforcement learning field. Check @annaithoma.bsky.social thread below for more info!

🚨 New preprint: What does the research landscape of behavioral reinforcement learning look like 🌍?
We developed an LLM-powered bibliometric analysis to characterize article clusters, investigate their connections, and examine the distribution of topics across the landscape.
osf.io/6c2va_v1
We developed an LLM-powered bibliometric analysis to characterize article clusters, investigate their connections, and examine the distribution of topics across the landscape.
osf.io/6c2va_v1
OSF
osf.io
October 19, 2025 at 7:48 AM
It was a real pleasure to be involved in the meta-scientific collaboration about the (historical, semantic and to some extent sociological) structure of the behavioral reinforcement learning field. Check @annaithoma.bsky.social thread below for more info!
If you want to know more about the reinforcement learning biases framework, I summarised it here:
www.researchgate.net/publication/...
www.researchgate.net/publication/...
October 14, 2025 at 7:38 AM
If you want to know more about the reinforcement learning biases framework, I summarised it here:
www.researchgate.net/publication/...
www.researchgate.net/publication/...
Reposted by Stefano Palminteri
Very cool study showing that "apparent" asymmetric update in reinforcement learning can emerge from Bayes optimal principles by Prakhar Godara in @pnas.org
www.pnas.org/doi/abs/10.1...
www.pnas.org/doi/abs/10.1...

Apparent learning biases emerge from optimal inference: Insights from master equation analysis | PNAS
Recent studies [S. Palminteri, G. Lefebvre, E. J. Kilford, S. J. Blakemore, PLoS Comput.
Biol. 13, e1005684 (2017); G. Lefebvre, M. Lebreton, F. Me...
www.pnas.org
October 13, 2025 at 12:03 PM
Very cool study showing that "apparent" asymmetric update in reinforcement learning can emerge from Bayes optimal principles by Prakhar Godara in @pnas.org
www.pnas.org/doi/abs/10.1...
www.pnas.org/doi/abs/10.1...
Very cool study showing that "apparent" asymmetric update in reinforcement learning can emerge from Bayes optimal principles by Prakhar Godara in @pnas.org
www.pnas.org/doi/abs/10.1...
www.pnas.org/doi/abs/10.1...
Apparent learning biases emerge from optimal inference: Insights from master equation analysis | PNAS
Recent studies [S. Palminteri, G. Lefebvre, E. J. Kilford, S. J. Blakemore, PLoS Comput.
Biol. 13, e1005684 (2017); G. Lefebvre, M. Lebreton, F. Me...
www.pnas.org
October 13, 2025 at 12:03 PM
Very cool study showing that "apparent" asymmetric update in reinforcement learning can emerge from Bayes optimal principles by Prakhar Godara in @pnas.org
www.pnas.org/doi/abs/10.1...
www.pnas.org/doi/abs/10.1...
Reposted by Stefano Palminteri
Thought experiments such as the Blockhead and Super-Super Spartans are often taken as “definitive” arguments against behavior-based inference of cognitive processes.
In our review -with @thecharleywu.bsky.social- we argue they may not be as definitive as originally thought.
In our review -with @thecharleywu.bsky.social- we argue they may not be as definitive as originally thought.


October 9, 2025 at 12:34 PM
Thought experiments such as the Blockhead and Super-Super Spartans are often taken as “definitive” arguments against behavior-based inference of cognitive processes.
In our review -with @thecharleywu.bsky.social- we argue they may not be as definitive as originally thought.
In our review -with @thecharleywu.bsky.social- we argue they may not be as definitive as originally thought.
Reposted by Stefano Palminteri

I haven't given any news a while, I've been nose deep into this novel preprint with my excellent collaborators @stepalminteri.bsky.social, @urihertz.bsky.social and Bahador Bahrami: "Uncovering the semantics of teaching in
experiential learning with Large Language Models".
doi.org/10.31234/osf...
experiential learning with Large Language Models".
doi.org/10.31234/osf...
OSF
doi.org
October 11, 2025 at 5:32 AM
I haven't given any news a while, I've been nose deep into this novel preprint with my excellent collaborators @stepalminteri.bsky.social, @urihertz.bsky.social and Bahador Bahrami: "Uncovering the semantics of teaching in
experiential learning with Large Language Models".
doi.org/10.31234/osf...
experiential learning with Large Language Models".
doi.org/10.31234/osf...
Thought experiments such as the Blockhead and Super-Super Spartans are often taken as “definitive” arguments against behavior-based inference of cognitive processes.
In our review -with @thecharleywu.bsky.social- we argue they may not be as definitive as originally thought.
In our review -with @thecharleywu.bsky.social- we argue they may not be as definitive as originally thought.
October 9, 2025 at 12:34 PM
Thought experiments such as the Blockhead and Super-Super Spartans are often taken as “definitive” arguments against behavior-based inference of cognitive processes.
In our review -with @thecharleywu.bsky.social- we argue they may not be as definitive as originally thought.
In our review -with @thecharleywu.bsky.social- we argue they may not be as definitive as originally thought.