



Samira
@samiraabnar.bsky.social
Pinned
Samira
@samiraabnar.bsky.social
· Jan 28

🚨 One question that has always intrigued me is the role of different ways to increase a model's capacity: parameters, parallelizable compute, or sequential compute?
We explored this through the lens of MoEs:
We explored this through the lens of MoEs:
Reposted by Samira

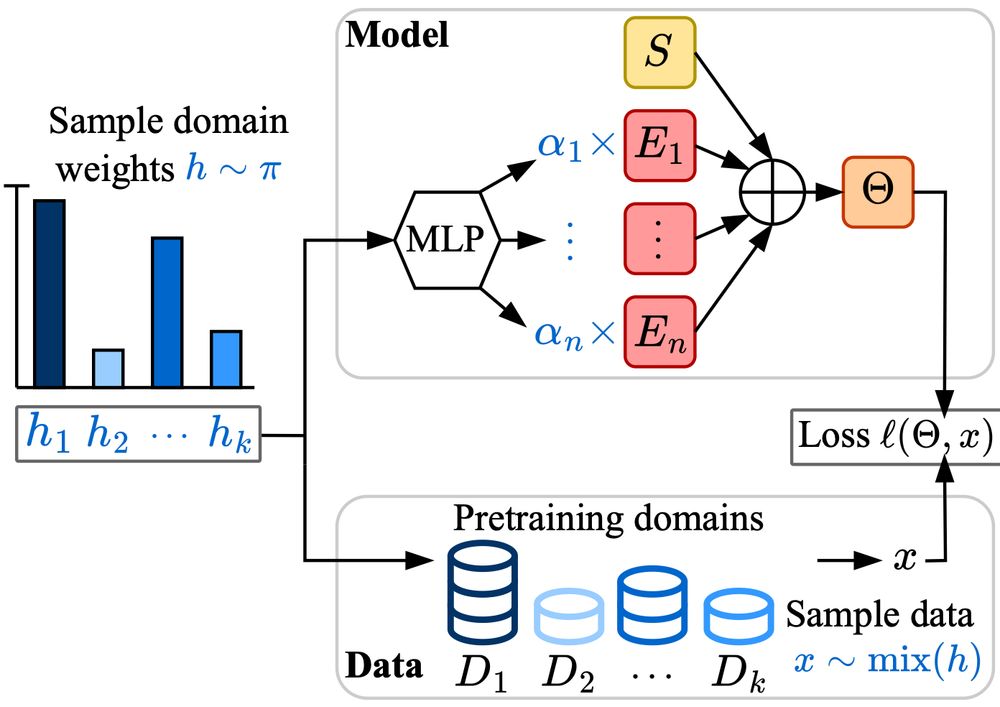
Excited to share Soup-of-Experts, a new neural network architecture that, for any given specific task, can instantiate in a flash a small model that is very good on it.
Made with ❤️ at Apple
Thanks to my co-authors David Grangier, Angelos Katharopoulos, and Skyler Seto!
arxiv.org/abs/2502.01804
Made with ❤️ at Apple
Thanks to my co-authors David Grangier, Angelos Katharopoulos, and Skyler Seto!
arxiv.org/abs/2502.01804
February 5, 2025 at 9:32 AM
Excited to share Soup-of-Experts, a new neural network architecture that, for any given specific task, can instantiate in a flash a small model that is very good on it.
Made with ❤️ at Apple
Thanks to my co-authors David Grangier, Angelos Katharopoulos, and Skyler Seto!
arxiv.org/abs/2502.01804
Made with ❤️ at Apple
Thanks to my co-authors David Grangier, Angelos Katharopoulos, and Skyler Seto!
arxiv.org/abs/2502.01804
Reposted by Samira

Reading "Distilling Knowledge in a Neural Network" left me fascinated and wondering:
"If I want a small, capable model, should I distill from a more powerful model, or train from scratch?"
Our distillation scaling law shows, well, it's complicated... 🧵
arxiv.org/abs/2502.08606
"If I want a small, capable model, should I distill from a more powerful model, or train from scratch?"
Our distillation scaling law shows, well, it's complicated... 🧵
arxiv.org/abs/2502.08606

Distillation Scaling Laws
We provide a distillation scaling law that estimates distilled model performance based on a compute budget and its allocation between the student and teacher. Our findings reduce the risks associated ...
arxiv.org
February 13, 2025 at 9:50 PM
Reading "Distilling Knowledge in a Neural Network" left me fascinated and wondering:
"If I want a small, capable model, should I distill from a more powerful model, or train from scratch?"
Our distillation scaling law shows, well, it's complicated... 🧵
arxiv.org/abs/2502.08606
"If I want a small, capable model, should I distill from a more powerful model, or train from scratch?"
Our distillation scaling law shows, well, it's complicated... 🧵
arxiv.org/abs/2502.08606
Reposted by Samira

Paper🧵 (cross-posted at X): When does composition of diffusion models "work"? Intuitively, the reason dog+hat works and dog+horse doesn’t has something to do with independence between the concepts being composed. The tricky part is to formalize exactly what this means. 1/

February 11, 2025 at 5:59 AM
Paper🧵 (cross-posted at X): When does composition of diffusion models "work"? Intuitively, the reason dog+hat works and dog+horse doesn’t has something to do with independence between the concepts being composed. The tricky part is to formalize exactly what this means. 1/
🚨 One question that has always intrigued me is the role of different ways to increase a model's capacity: parameters, parallelizable compute, or sequential compute?
We explored this through the lens of MoEs:
We explored this through the lens of MoEs:
January 28, 2025 at 6:26 AM
🚨 One question that has always intrigued me is the role of different ways to increase a model's capacity: parameters, parallelizable compute, or sequential compute?
We explored this through the lens of MoEs:
We explored this through the lens of MoEs: