


Robert Nowak
@rdnowak.bsky.social
770 followers
110 following
41 posts
Director of the Center for the Advancement of Progress
Posts
Media
Videos
Starter Packs
Robert Nowak
@rdnowak.bsky.social
· Sep 8

Honored to have participated in this amazing event and meet great people and their work in the data science field.






Reposted by Robert Nowak





Robert Nowak
@rdnowak.bsky.social
· Jun 21

UChicago is thrilled to host #MMLS2025 in just a few days!
We can’t wait to welcome the ML community to campus.
Huge thanks to our amazing sponsors:
@schmidtsciences.bsky.social
University of Chicago Department of Computer Science
@dsi-uchicago.bsky.social
Invenergy
🧵(1/3)
We can’t wait to welcome the ML community to campus.
Huge thanks to our amazing sponsors:
@schmidtsciences.bsky.social
University of Chicago Department of Computer Science
@dsi-uchicago.bsky.social
Invenergy
🧵(1/3)

Robert Nowak
@rdnowak.bsky.social
· May 16
Robert Nowak
@rdnowak.bsky.social
· Apr 25

The Midwest Machine Learning Symposium will happen in Chicago on June 23-4 on the University of Chicago campus (midwest-ml.org/2025/). We have an amazing lineup of speakers:@profsanjeevarora.bsky.social from Princeton, Heng Ji from UIUC, Tuomas Sandholm from CMU, @ravenben.bsky.social from UChicago.

Robert Nowak
@rdnowak.bsky.social
· Feb 7
Robert Nowak
@rdnowak.bsky.social
· Feb 7

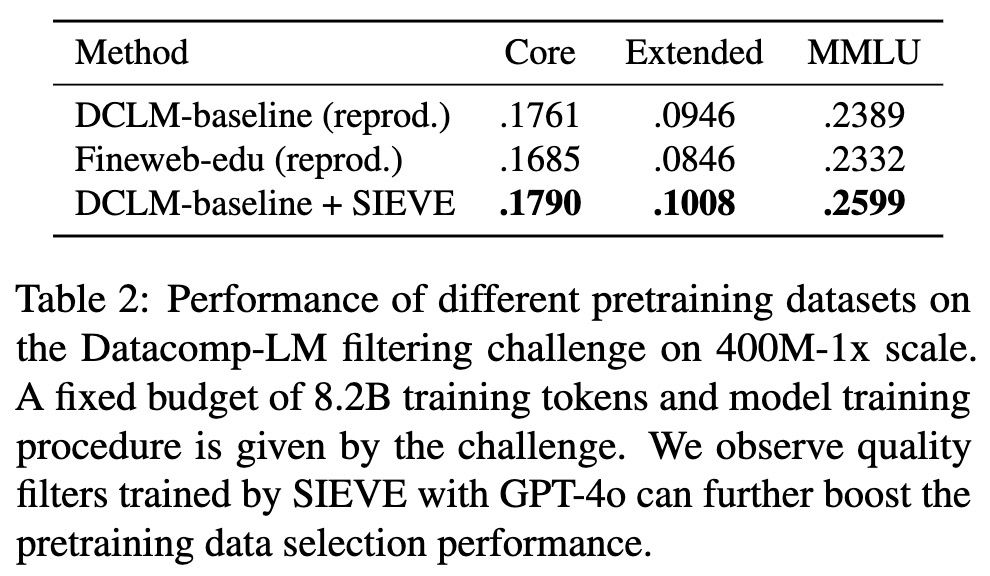
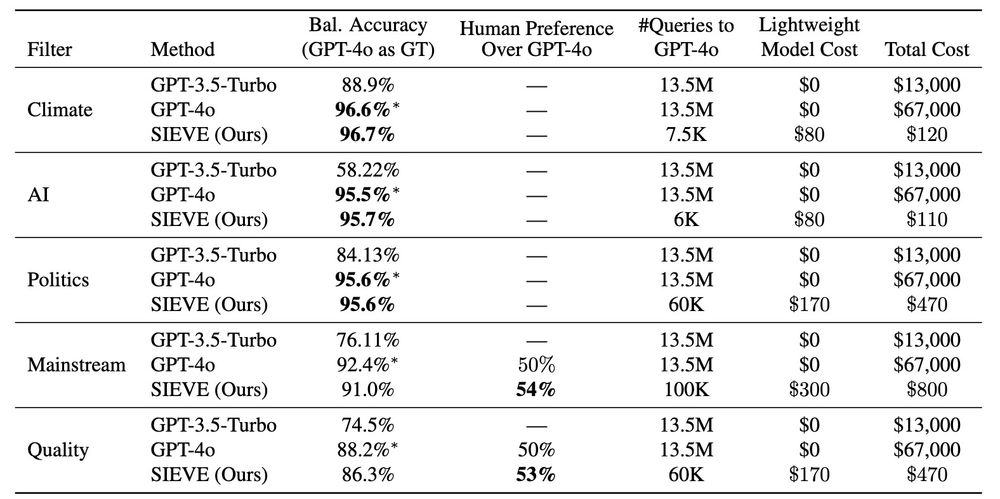
GPT-4o as the Gold Standard: A Scalable and General Purpose Approach to Filter Language Model Pretraining Data
Large language models require vast amounts of high-quality training data, but effective filtering of web-scale datasets remains a significant challenge. This paper demonstrates that GPT-4o is remarkab...
arxiv.org
Robert Nowak
@rdnowak.bsky.social
· Feb 7



Reposted by Robert Nowak





Robert Nowak
@rdnowak.bsky.social
· Jan 4
Robert Nowak
@rdnowak.bsky.social
· Jan 4
Robert Nowak
@rdnowak.bsky.social
· Jan 4