



Prabhav Singh
@psingh54.bsky.social
Research in Language & Speech Processing - Interested in Multimodal AI
CLSP@JHU
CLSP@JHU
Reposted by Prabhav Singh

google slides refreshed their templates and i'm lowkey impressed with how unhinged they are




December 11, 2024 at 5:31 PM
google slides refreshed their templates and i'm lowkey impressed with how unhinged they are
ChatGPT has been down for more than an hour and now I realize how much I use it - I literally can't begin to do anything without it open (even though I might not use it).
Shit's become moral support.
Shit's become moral support.
December 12, 2024 at 2:26 AM
ChatGPT has been down for more than an hour and now I realize how much I use it - I literally can't begin to do anything without it open (even though I might not use it).
Shit's become moral support.
Shit's become moral support.
In my defense, I was late for an assignment and was probably rude to the new O1 Model by OpenAI but I did not except it to attack back damn.
(Is it wrong that I respect O1 for this?)
(Is it wrong that I respect O1 for this?)

December 7, 2024 at 5:04 AM
In my defense, I was late for an assignment and was probably rude to the new O1 Model by OpenAI but I did not except it to attack back damn.
(Is it wrong that I respect O1 for this?)
(Is it wrong that I respect O1 for this?)
How is it that the best papers in most good conferences have a codebase that takes a month to replicate because of incomplete and outdated documentation. Can't even get the baselines on a dataset to run without playing around with their steps for 10 days.
November 23, 2024 at 11:34 PM
How is it that the best papers in most good conferences have a codebase that takes a month to replicate because of incomplete and outdated documentation. Can't even get the baselines on a dataset to run without playing around with their steps for 10 days.
AI2 has to be one of the orgs pushing out the most useful stuff - fully open source. Open Scholar was amazing + This seems super useful too.

Meet Tülu 3, a set of state-of-the-art instruct models with fully open data, eval code, and training algorithms.
We invented new methods for fine-tuning language models with RL and built upon best practices to scale synthetic instruction and preference data.
Demo, GitHub, paper, and models 👇
We invented new methods for fine-tuning language models with RL and built upon best practices to scale synthetic instruction and preference data.
Demo, GitHub, paper, and models 👇
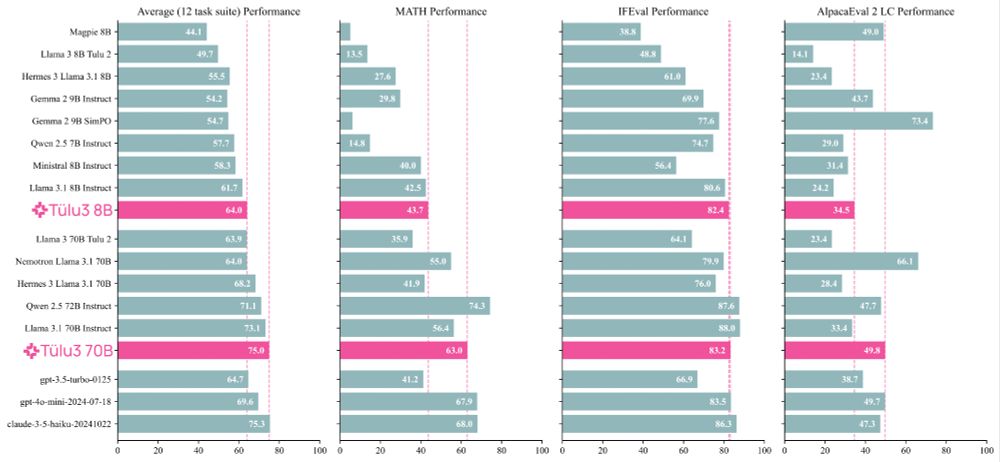
November 23, 2024 at 4:57 AM
AI2 has to be one of the orgs pushing out the most useful stuff - fully open source. Open Scholar was amazing + This seems super useful too.