



Sanjeev Arora
@profsanjeevarora.bsky.social
Director, Princeton Language and Intelligence. Professor of CS.
Reposted by Sanjeev Arora

Check out our new blogpost and policy brief on our recently updated lab website!
❓Are we actually capturing the bubble of risk for cybersecurity evals? Not really! Adversaries can modify agents by a small amount and get massive gains.
❓Are we actually capturing the bubble of risk for cybersecurity evals? Not really! Adversaries can modify agents by a small amount and get massive gains.


July 14, 2025 at 10:22 PM
Check out our new blogpost and policy brief on our recently updated lab website!
❓Are we actually capturing the bubble of risk for cybersecurity evals? Not really! Adversaries can modify agents by a small amount and get massive gains.
❓Are we actually capturing the bubble of risk for cybersecurity evals? Not really! Adversaries can modify agents by a small amount and get massive gains.
Would it make sense to also track how often this happened in pre-2023 cases? Humans "hallucinate" by making cut-and-paste mistakes, or other types of errors.
Honestly it's happening so much that I can't keep up with adding all of them to our tracker. I have ~30 cases that people have sent my way that I'm still ingesting, so will be over 100 soon.
www.polarislab.org/ai-law-track...
www.polarislab.org/ai-law-track...
May 26, 2025 at 2:32 AM
Would it make sense to also track how often this happened in pre-2023 cases? Humans "hallucinate" by making cut-and-paste mistakes, or other types of errors.
The paper seems to reflect reflect a fundamental misunderstanding about how LLMs work. One cannot (currently) tell an LLM to "ignore pretraining data from year X onwards". The LLM doesn't have data stored neatly inside it in sortable format. It is not like a hard drive.

April 22, 2025 at 2:21 AM
The paper seems to reflect reflect a fundamental misunderstanding about how LLMs work. One cannot (currently) tell an LLM to "ignore pretraining data from year X onwards". The LLM doesn't have data stored neatly inside it in sortable format. It is not like a hard drive.
Great comment by my colleague @randomwalker.bsky.social

Some people are professional worriers. That’s not a pejorative — it’s very helpful for there to be people whose job is to anticipate risks before they materialize on a large scale, especially those related to emerging technologies. Some of my own work is in this category. 🧵
March 16, 2025 at 7:06 PM
Great comment by my colleague @randomwalker.bsky.social
Reposted by Sanjeev Arora
Understanding and extrapolating benchmark results will become essential for effective policymaking and informing users. New work identifies indicators that have high predictive power in modeling LLM performance. Excited for it to be out!



March 11, 2025 at 8:07 PM
Understanding and extrapolating benchmark results will become essential for effective policymaking and informing users. New work identifies indicators that have high predictive power in modeling LLM performance. Excited for it to be out!
Reposted by Sanjeev Arora

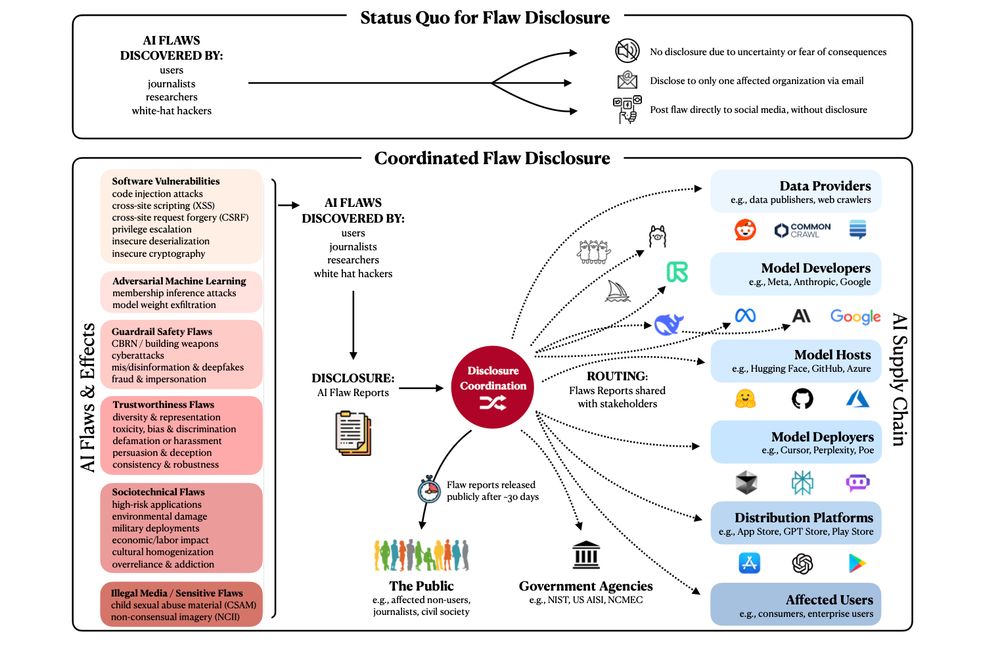
What are 3 concrete steps that can improve AI safety in 2025? 🤖⚠️
Our new paper, “In House Evaluation is Not Enough” has 3 calls-to-actions to empower evaluators:
1️⃣ Standardized AI flaw reports
2️⃣ AI flaw disclosure programs + safe harbors.
3️⃣ A coordination center for transferable AI flaws.
1/🧵
Our new paper, “In House Evaluation is Not Enough” has 3 calls-to-actions to empower evaluators:
1️⃣ Standardized AI flaw reports
2️⃣ AI flaw disclosure programs + safe harbors.
3️⃣ A coordination center for transferable AI flaws.
1/🧵
March 13, 2025 at 3:59 PM
What are 3 concrete steps that can improve AI safety in 2025? 🤖⚠️
Our new paper, “In House Evaluation is Not Enough” has 3 calls-to-actions to empower evaluators:
1️⃣ Standardized AI flaw reports
2️⃣ AI flaw disclosure programs + safe harbors.
3️⃣ A coordination center for transferable AI flaws.
1/🧵
Our new paper, “In House Evaluation is Not Enough” has 3 calls-to-actions to empower evaluators:
1️⃣ Standardized AI flaw reports
2️⃣ AI flaw disclosure programs + safe harbors.
3️⃣ A coordination center for transferable AI flaws.
1/🧵
A new path forward for open AI (note the space between the two words). Looking forward to seeing how it enables great research in the open.

If AI isn’t truly open, it will fail us. We can’t close in a black box our greatest invention yet just so that a few can freely monetize. AI needs its Linux moment, and so we started working towards it. This can only succeed if we all work together!
#oumi #opensource #collaboration
#oumi #opensource #collaboration
January 29, 2025 at 11:19 PM
A new path forward for open AI (note the space between the two words). Looking forward to seeing how it enables great research in the open.
x.com/parksimon080...
Can VLMs do difficult reasoning tasks? Using new dataset for evaluating Simple-to-Hard generalization (a form of OOD generalization) we study how to mitigate the dreaded "modality gap" VLM vs its base LLM.
(note: the poster, Simon Park, applied to PhD programs this spring)
Can VLMs do difficult reasoning tasks? Using new dataset for evaluating Simple-to-Hard generalization (a form of OOD generalization) we study how to mitigate the dreaded "modality gap" VLM vs its base LLM.
(note: the poster, Simon Park, applied to PhD programs this spring)
x.com
x.com
January 8, 2025 at 2:43 PM
x.com/parksimon080...
Can VLMs do difficult reasoning tasks? Using new dataset for evaluating Simple-to-Hard generalization (a form of OOD generalization) we study how to mitigate the dreaded "modality gap" VLM vs its base LLM.
(note: the poster, Simon Park, applied to PhD programs this spring)
Can VLMs do difficult reasoning tasks? Using new dataset for evaluating Simple-to-Hard generalization (a form of OOD generalization) we study how to mitigate the dreaded "modality gap" VLM vs its base LLM.
(note: the poster, Simon Park, applied to PhD programs this spring)
SimPO: new method from Princeton PLI for improving chat models via preference data. Simpler than DPO and widely adopted within weeks by top models in the chatbot arena. Excellent and elementary account by author
@xiamengzhou.bsky.social (she's also on job market!). tinyurl.com/pepcynaxFully
@xiamengzhou.bsky.social (she's also on job market!). tinyurl.com/pepcynaxFully
tinyurl.com
December 3, 2024 at 2:55 PM
SimPO: new method from Princeton PLI for improving chat models via preference data. Simpler than DPO and widely adopted within weeks by top models in the chatbot arena. Excellent and elementary account by author
@xiamengzhou.bsky.social (she's also on job market!). tinyurl.com/pepcynaxFully
@xiamengzhou.bsky.social (she's also on job market!). tinyurl.com/pepcynaxFully
Reposted by Sanjeev Arora

I'll be giving a talk on my two recent preference learning works (led by Angelica Chen and @noamrazin.bsky.social) in the AI Tinkerers Paper Club today (11/26) at noon ET. Excited to share this talk with a broader audience! paperclub.aitinkerers.org/p/join-paper...

Join Paper Club with Princeton University on Model Alignment Challenges in Preference Learning [AI Tinkerers - Paper Club]
Join Our Paper Club Event Series! Meet with Sadhika Malladi, AI Researcher at Princeton University and discuss the challenges of aligning language models with human preferences. Don’t miss this unique...
paperclub.aitinkerers.org
November 26, 2024 at 12:55 PM
I'll be giving a talk on my two recent preference learning works (led by Angelica Chen and @noamrazin.bsky.social) in the AI Tinkerers Paper Club today (11/26) at noon ET. Excited to share this talk with a broader audience! paperclub.aitinkerers.org/p/join-paper...